Spark作业调度阶段分析
Spark作为分布式的大数据处理框架必然或涉及到大量的作业调度,如果能够理解Spark中的调度对我们编写或优化Spark程序都是有很大帮助的;
在Spark中存在转换操作(Transformation Operation)与 行动操作(Action Operation)两种;而转换操作只是会从一个RDD中生成另一个RDD且是lazy的,Spark中只有行动操作(Action Operation)才会触发作业的提交,从而引发作业调度;在一个计算任务中可能会多次调用 转换操作这些操作生成的RDD可能存在着依赖关系,而由于转换都是lazy所以当行动操作(Action Operation )触发时才会有真正的RDD生成,这一系列的RDD中就存在着依赖关系形成一个DAG(Directed Acyclc Graph),在Spark中DAGScheuler是基于DAG的顶层调度模块;
相关名词
Application:使用Spark编写的应用程序,通常需要提交一个或多个作业;
Job:在触发RDD Action操作时产生的计算作业
Task:一个分区数据集中最小处理单元也就是真正执行作业的地方
TaskSet:由多个Task所组成没有Shuffle依赖关系的任务集
Stage:一个任务集对应的调度阶段 ,每个Job会被拆分成诺干个Stage
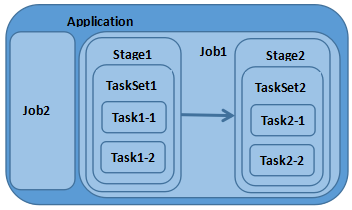
1.1 作业调度关系图
RDD Action作业提交流程
这里根据Spark源码跟踪触发Action操作时触发的Job提交流程,Count()是RDD中的一个Action操作所以调用Count时会触发Job提交;
在RDD源码count()调用SparkContext的runJob,在runJob方法中根据partitions(分区)大小创建Arrays存放返回结果;
RDD.scala
/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
SparkContext.scala
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
}
在SparkContext中将调用DAGScheduler的runJob方法提交作业,DAGScheduler主要任务是计算作业与任务依赖关系,处理调用逻辑;DAGScheduler提供了submitJob与runJob方法用于 提交作业,runJob方法会一直等待作业完成,submitJob则返回JobWaiter对象可以用于判断作业执行结果;
在runJob方法中将调用submitJob,在submitJob中把提交操作放入到事件循环队列(DAGSchedulerEventProcessLoop)中;
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
......
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
......
}
在事件循环队列中将调用eventprocessLoop的onReceive方法;
Stage拆分
提交作业时DAGScheduler会从RDD依赖链尾部开始,遍历整个依赖链划分调度阶段;划分阶段以ShuffleDependency为依据,当没有ShuffleDependency时整个Job 只会有一个Stage;在事件循环队列中将会调用DAGScheduler的handleJobSubmitted方法,此方法会拆分Stage、提交Stage;
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
......
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
......
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
......
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
submitWaitingStages()
}
调度阶段提交
在提交Stage时会先调用getMissingParentStages获取父阶段Stage,迭代该阶段所依赖的父调度阶段如果存在则先提交该父阶段的Stage 当不存在父Stage或父Stage执行完成时会对当前Stage进行提交;
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
if (missing.isEmpty) {
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
}
......
}
参考资料:
http://spark.apache.org/docs/latest/
文章首发地址:Solinx
http://www.solinx.co/archives/579
Spark作业调度阶段分析的更多相关文章
- Spark作业调度
Spark在任务提交时,主要存在于Driver和Executor的两个节点. (1)Driver的作用: 用于将所有要处理的RDD的操作转化为DAG,并且根据RDD DAG将JBO分割为多个Stage ...
- 【Spark学习】Apache Spark作业调度机制
Spark版本:1.1.1 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4135905.html 目录 概 ...
- Spark 作业调度相关术语
作业(Job):RDD 中由行动操作所生成的一个或多个调度阶段 调度阶段(Stage):每个作业会因为 RDD 间的依赖关系拆分成多组任务集合,称为调度阶段,也叫做任务集(TaskSet).高度阶段的 ...
- Spark大数据处理技术
全球首部全面介绍Spark及Spark生态圈相关技术的技术书籍 俯览未来大局,不失精细剖析,呈现一个现代大数据框架的架构原理和实现细节 透彻讲解Spark原理和架构,以及部署模式.调度框架.存储管理及 ...
- Spark SQL在100TB上的自适应执行实践(转载)
Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇 ...
- Spark参数配置
转自:http://hadoop1989.com/2015/10/08/Spark-Configuration/ 一.Spark参数设置 二.查看Spark参数设置 三.Spark参数分类 四.Spa ...
- spark总结——转载
转载自: spark总结 第一个Spark程序 /** * 功能:用spark实现的单词计数程序 * 环境:spark 1.6.1, scala 2.10.4 */ // 导入相关类库impor ...
- [转]Spark SQL2.X 在100TB上的Adaptive execution(自适应执行)实践
Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇 ...
- Spark Stage 的划分
Spark作业调度 对RDD的操作分为transformation和action两类,真正的作业提交运行发生在action之后,调用action之后会将对原始输入数据的所有transformation ...
随机推荐
- 2016年8月ios面试问题总结
1.app分发方式 所谓分发方式简单点讲就是你的app都可以通过哪些途径给用户使用. a:个人或者公司的开发者账号 可以上传appStore,用户通过appStore下载. b:企业账号:打包分发. ...
- 【.net深呼吸】非 Web 项目使用缓存
从.net 4 开始,非web项目也可以使用缓存技术,故曰:.net 4 乃框架成熟之标志也. 对于缓存嘛,耍过 ASP.NET 的伙伴们肯定知道,这么说吧,就是将一些使用频率较高的数据放于内存中,并 ...
- 跨域的jsonP
1.出现原因:因为web中的同源策略(域名,协议,端口号)限制了跨域访问. 2.区别于json (个人理解)json是数据交换格式,jsonp是数据通信中的交互方式 3.jsonp的get与p ...
- JS 对象封装的常用方式
JS是一门面向对象语言,其对象是用prototype属性来模拟的,下面,来看看如何封装JS对象. 常规封装 function Person (name,age,sex){ this.name = na ...
- Hive索引功能测试
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 从Hive的官方wiki来看,Hive0.7以后增加了一个对表建立index的功能,想试下性能是 ...
- 用SignalR 2.0开发客服系统[系列2:实现聊天室]
前言 交流群:195866844 上周发表了 用SignalR 2.0开发客服系统[系列1:实现群发通讯] 这篇文章,得到了很多帮助和鼓励,小弟在此真心的感谢大家的支持.. 这周继续系列2,实现聊天室 ...
- 详解web容器 - Jetty与Tomcat孰强孰弱
Jetty 基本架构 Jetty目前的是一个比较被看好的 Servlet 引擎,它的架构比较简单,也是一个可扩展性和非常灵活的应用服务器.它有一个基本数据模型,这个数据模型就是 Handler(处理器 ...
- 在DevExpress程序中使用条形码二维码控件,以及进行报表打印处理
在很多业务系统里面,越来越多涉及到条形码.二维码的应用了,不管在Web界面还是WInform界面都需要处理很多物料相关的操作,甚至很多企业为了减少录入错误操作,为每个设备进行条形码.二维码的标签,直接 ...
- 高德地图API 简单使用
主要是功能是 在地图上添加标记点.在标记点添加相应的内容.单击查看内容.双击直接进入相应的项目系统. <!DOCTYPE html> <html xmlns="http:/ ...
- "检索COM类工厂中 CLSID为 {00024500-0000-0000-C000-000000000046}的组件时失败,原因是出现以下错误: 80070005" 问题的解决
一.故障环境 Windows 2008 .net 3.0 二.故障描述 调用excel组件生成excel文档时页面报错.报错内容一大串,核心是"检索COM类工厂中 CLSID为 {000 ...