C++数据结构之二叉查找树(BST)
C++数据结构之二叉查找树(BST)
二分查找法在算法家族大类中属于“分治法”,二分查找的过程比较简单,代码见我的另一篇日志,戳这里!因二分查找所涉及的有序表是一个向量,若有插入和删除结点的操作,则维护表的有序性所花的代价是O(n)。
就查找性能而言,二叉查找树和二分查找不分伯仲,但是,就维护表的有序性而言,二叉排序树无须移动结点,只需修改指针即可完成插入和删除操作,且其平均的执行时间均为O(lgn),因此更有效。二叉查找树,顾名思义,是一种可以用来二分查找的树数据结构,其左孩子比父节点小,右孩子比父节点大,还有一个特性就是”中序遍历“可以让结点有序。在对关键字进行查找的时候,根据关键字与根节点的关键字比较的结果,分别选择继续与其左子树或者右子树进行比较,直到找到所查找的关键字或者访问节点的左右子树不存在(没找到关键字)则退出!
二叉查找树的主要操作有:插入关键字,查找关键字,删除关键字。下面分别对这三个步骤做详细描述和算法实现。
为了方便,我将二叉查找树实现为一个类,结构如下:

typedef struct Node_
{
struct Node_ *parent;
struct Node_ *left;
struct Node_ *right;
T data;
}Node; class BinaryTree
{
public:
BinaryTree():root(NULL){};
~BinaryTree();
bool insertNode(T data);
bool deleteNode(T data);
Node* findNode(T data);
private:
Node *root;
};
1. 插入关键字的过程如下所示:

插入过程的代码如下:
bool BinaryTree::insertNode(T data)
{
Node *x = NULL, *current, *parent; /***********************************************
* allocate node for data and insert in tree *
***********************************************/ /* find x's parent */
current = root;
parent = NULL;
while (current) {
if (compEQ(data, current->data)) return true;
parent = current;
current = compLT(data, current->data) ?
current->left : current->right;
} /* setup new node */
if ((x = (Node*)malloc(sizeof(*x))) == 0)
{
cout << "Insufficient memory (insertNode)!" << endl;
return false;
}
x->data = data;
x->parent = parent;
x->left = NULL;
x->right = NULL; /* insert x in tree*/
if(parent)
if(compLT(x->data, parent->data))
parent->left = x;
else
parent->right = x;
else
root = x; return true;
}
其中的compEQ和compLT为2个宏定义,用来比较两个关键字的大小。
2. 查找关键字的过程比较简单,和二分查找方法类似,代码如下:
Node* BinaryTree::findNode(T data)
{
/*******************************
* find node containing data *
*******************************/ Node *current = root;
while(current != NULL)
if(compEQ(data, current->data))
return current;
else
current = compLT(data, current->data) ?
current->left : current->right;
return NULL;
}
3. 删除关键字的过程分为2种情况讨论:单孩子的情况和左右孩子的情况。
1> 单孩子情况分析:
如果删除的节点有左孩子那就把左孩子顶上去,如果有右孩子就把右孩子顶上去,so easy!如图所示:
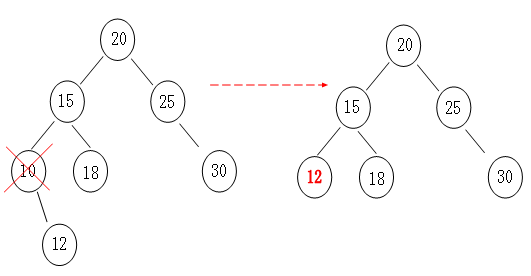
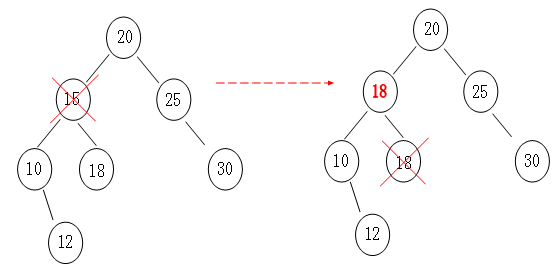
2> 左右孩子情况分析:
首先可以这么想象,如果我们要删除一个数组的元素,那么我们在删除后会将其后面的一个元素顶到被删除的位置,如下图所示:

那么二叉树操作同样也是一样,我们根据“中序遍历(inorder tree walk)”找到要删除结点的后一个结点,然后顶上去就行了,原理跟“数组”一样一样的。
好了,贴代码:
bool BinaryTree::deleteNode(T data)
{
Node* pNode = findNode(data);
if (pNode == NULL)
{
cout << "Cannot find this data in BST!" << endl;
return false;
} Node *x, *y;
/* find tree successor */
if (pNode->left == NULL || pNode->right == NULL)
y = pNode;
else {
y = pNode->right;
while (y->left != NULL) y = y->left;
} /* x is y's only child */
if (y->left != NULL)
x = y->left;
else
x = y->right; /* remove y from the parent chain */
if (x) x->parent = y->parent;
if (y->parent)
if (y == y->parent->left)
y->parent->left = x;
else
y->parent->right = x;
else
root = x; /* y is the node we're removing */
/* z is the data we're removing */
/* if z and y are not the same, replace z with y. */
if (y != pNode) {
y->left = pNode->left;
if (y->left) y->left->parent = y;
y->right = pNode->right;
if (y->right) y->right->parent = y;
y->parent = pNode->parent;
if (pNode->parent)
if (pNode == pNode->parent->left)
pNode->parent->left = y;
else
pNode->parent->right = y;
else
root = y;
free (pNode);
}
else {
free (y);
}
return true;
}
好了,二叉查找树的代码告一段落,我们在来分析一下二叉查找树的插入过程,假如有以下序列:<4, 17, 16, 20, 37, 38, 43>,则会生成如下所示二叉树:
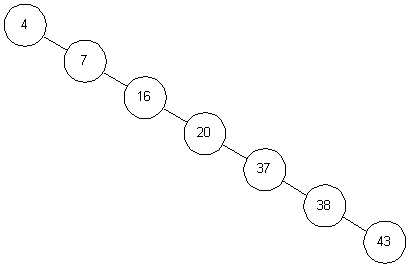
这已经完全退化成了一个单链表,势必影响到关键字的查找过程。不过总会有解决办法的,下一篇博客我将继续这个话题,对普通二叉树经过旋转,即使用平衡二叉树,使其保持最坏复杂度在O(logN)。
谢谢大家的阅读,希望能够帮到大家!PS:文章中部分图片利用了博客园另外一篇文章的插图(戳这里)!
Published by Windows Live Write!
作者: 薛定谔の喵
出处: http://www.cnblogs.com/berlin-sun/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
C++数据结构之二叉查找树(BST)的更多相关文章
- 查找系列合集-二叉查找树BST
一. 二叉树 1. 什么是二叉树? 在计算机科学中,二叉树是每个结点最多有两个子树的树结构. 通常子树被称作“左子树”(left subtree)和“右子树”(right subtree). 二叉树常 ...
- [学习笔记] 二叉查找树/BST
平衡树前传之BST 二叉查找树(\(BST\)),是一个类似于堆的数据结构, 并且,它也是平衡树的基础. 因此,让我们来了解一下二叉查找树吧. (其实本篇是作为放在平衡树前的前置知识的,但为了避免重复 ...
- 数据结构:二叉查找树(C语言实现)
数据结构:二叉查找树(C语言实现) ►写在前面 关于二叉树的基础知识,请看我的一篇博客:二叉树的链式存储 说明: 二叉排序树或者是一棵空树,或者是具有下列性质的二叉树: 1.若其左子树不空,则左子树上 ...
- 二叉查找树(BST)
二叉查找树(BST):使用中序遍历可以得到一个有序的序列
- 二叉查找树BST 模板
二叉查找树BST 就是二叉搜索树 二叉排序树. 就是满足 左儿子<父节点<右儿子 的一颗树,插入和查询复杂度最好情况都是logN的,写起来很简单. 根据BST的性质可以很好的解决这些东 ...
- 算法与数据结构基础 - 二叉查找树(Binary Search Tree)
二叉查找树基础 二叉查找树(BST)满足这样的性质,或是一颗空树:或左子树节点值小于根节点值.右子树节点值大于根节点值,左右子树也分别满足这个性质. 利用这个性质,可以迭代(iterative)或递归 ...
- 浅谈算法和数据结构: 七 二叉查找树 八 平衡查找树之2-3树 九 平衡查找树之红黑树 十 平衡查找树之B树
http://www.cnblogs.com/yangecnu/p/Introduce-Binary-Search-Tree.html 前文介绍了符号表的两种实现,无序链表和有序数组,无序链表在插入的 ...
- 【查找结构 2】二叉查找树 [BST]
当所有的静态查找结构添加和删除一个数据的时候,整个结构都需要重建.这对于常常需要在查找过程中动态改变数据而言,是灾难性的.因此人们就必须去寻找高效的动态查找结构,我们在这讨论一个非常常用的动态查找树— ...
- JS中数据结构之二叉查找树
树是一种非线性的数据结构,以分层的方式存储数据.在二叉树上进行查找非常快,为二叉树添加或删除元素也非常快. 一棵树最上面的节点称为根节点,如果一个节点下面连接多个节点,那么该节点称为父节点,它下面的节 ...
随机推荐
- .Net 4.5中的HttpClient试用
.Net 4.5中增加了一个新的System.Net.Http.HttpClient名字空间(在 System.Net.Http.dll 中),用于发送 HTTP 请求和接收 HTTP 响应. 基本操 ...
- Android研究之游戏开发处理按键的响应
1.onKeyDown 方法 onKeyDown 方法是KeyEvent.Callback 接口中的一个抽象方法,重写onKeyDown 方法能够监听到按键被按下的事件,我们先看看onKeyDown方 ...
- android进度条
android进度条 1.达到的效果 2.布局代码 先写一个my_browser.xml文件 存放WebView <?xml version="1.0" encoding=& ...
- linux_ubuntu12.04 卸载和安装mysql、远程访问、not allowed
一: 安装mysql 卸载mysql 第一步 sudo apt-get autoremove --purge mysql-server-5.0 sudo apt-get remove mysql-se ...
- CSharp设计模式读书笔记(7):适配器模式(学习难度:★★☆☆☆,使用频率:★★★★☆)
适配器模式(Adapter Pattern):将一个接口转换成客户希望的另一个接口,使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper).适配器模式既可以作为类结构型模式,也可以作为对象 ...
- SVN & Git (一)
(一)SVN的使用.CornerStone图形化管理工具! SVN是Subversion的简称,是一个开放源代码的版本控制系统,相较于RCS.CVS,它采用了分支管理系统,它的设计目标就是取代CVS. ...
- MAC 命令行工具(Command Line Tools)安装
不过升级后安装命令行工具(Command Line Tools)时发现官网没有clt的下载安装包了,原来改了,使用命令在线安装. 打开终端,输入命令:xcode-select --install 选择 ...
- 如何利用【百度地图API】进行定位?非GPS定位
原文:如何利用[百度地图API]进行定位?非GPS定位 如果你可以上网,如果你有火狐浏览器,那么恭喜你.你能很容易使用以下代码进行定位! ------------------------------- ...
- 还是畅通project(杭州电1233)
还是畅通project Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Tota ...
- SQL代理执行EXE可执行程序
原文:SQL代理执行EXE可执行程序 1.如果没有启用xp_cmdshell安全配置是不可以使用的-- 启用xp_cmdshellEXEC sp_configure 'xp_cmdshell', 1 ...