ClickHouse中的循环复制集群拓扑
关系型数据库,但千万级表关联数据库基本上不太可能做到秒出;考虑过Sharding,但数据量大,
各种成本都很高;热数据存储到ElasticSearch,但无法跨索引关联,导致不得不做宽表,
因为权限,酒店信息会变,所以每次要刷全量数据,不适用于大表更新,
维护成本也很高;Redis键值对存储无法做到实时汇总;
1. 现有一个需求需要快速访问 2个字段 至少占 128KB 的 一条记录 , 累计十多亿数据更新,如何保证数据更新过程中生产应用高可用
2. 每天有将近百万次数据查询请求
3. 让用户无论在app端还是pc端查询数据提供秒出的效果
不断扩展使用场景的,是ClickHouse
ClickHouse是一款用于大数据实时分析的列式数据库管理系统,而非数据库。通过向量化执行以及对CPU底层指令集(SIMD)的使用,它可以对海量数据进行并行处理,从而加快数据的处理速度。
主要优点有:
- 为了高效的使用CPU,数据不仅仅按列存储,同时还按向量进行处理;
- 数据压缩空间大,减少IO;处理单查询高吞吐量每台服务器每秒最多数十亿行;
- 索引非B树结构,不需要满足最左原则;只要过滤条件在索引列中包含即可;即使在使用的数据不在索引中,由于各种并行处理机制ClickHouse全表扫描的速度也很快;
- 写入速度非常快,50-200M/s,对于大量的数据更新非常适用。
在某些情况下,需要使用复制配置分布式群集,但没有足够的服务器将每个复制副本放置在单独的节点上。最好在同一个节点上以特殊方式配置多个副本,这样即使在节点出现故障时也可以继续执行查询。这种复制配置可以在不同的分布式系统中找到,通常称为“循环”或“环”复制。在本文中,我们将讨论如何在ClickHouse中设置循环复制。如果您对本主题不熟悉,我们建议您从一篇介绍性文章“ClickHouse数据分发”开始。
概念
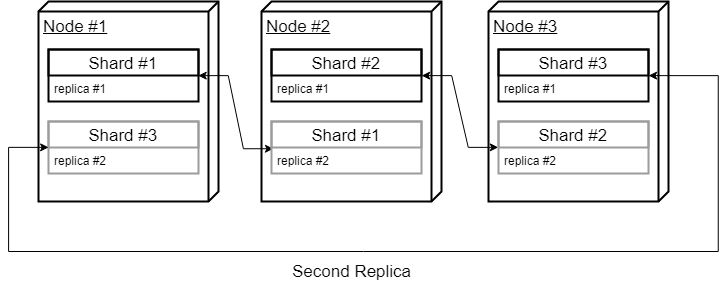
假设有3个服务器和1个表。目标是将数据分发到3个碎片中并复制两次。这需要在每个节点上有两个不同的碎片。
群集配置
让我们从定义3个碎片和2个副本的简单集群配置开始。由于我们只有3个节点可以使用,我们将以“圆形”的方式设置副本主机,这意味着我们将使用第一个和第二个节点作为第一个碎片,使用第二个和第三个节点作为第二个碎片,使用第三个和第一个节点作为第三个碎片。就像这样:
- 1st shard, 1st replica, hostname: cluster_node_1
- 1st shard, 2nd replica, hostname: cluster_node_2
- 2nd shard, 1st replica, hostname: cluster_node_2
- 2nd shard, 2nd replica, hostname: cluster_node_3
- 3rd shard, 1st replica, hostname: cluster_node_3
- 3rd shard, 2nd replica, hostname: cluster_node_1
配置文件如下:
<shard>
<replica>
<host>cluster_node_1</host>
</replica>
<replica>
<host>cluster_node_2</host>
</replica>
</shard>
<shard>
<replica>
<host>cluster_node_2</host>
</replica>
<replica>
<host>cluster_node_3</host>
</replica>
</shard>
<shard>
<replica>
<host>cluster_node_3</host>
</replica>
<replica>
<host>cluster_node_1</host>
</replica>
</shard>
现在您可以看到,我们有以下存储架构:
- cluster_node_1 stores 1st shard, 1st replica and 3rd shard, 2nd replica
- cluster_node_2 stores 1st shard, 2nd replica and 2nd shard, 1st replica
- cluster_node_3 stores 2nd shard, 2nd replica and 3rd shard, 1st replica
这显然不起作用,因为碎片具有相同的表名,当它们位于同一服务器上时,ClickHouse无法区分一个碎片/副本。这里的诀窍是把每个碎片放到一个单独的数据库中!ClickHouse允许为每个shard定义“default_database”,然后在查询时使用它,以便将特定表的查询路由到正确的数据库。
关于在ClickHouse中使用“Circle”拓扑的另一个重要注意事项是,您应该将每个特定shard的内部复制选项设置为TRUE。定义如下:
<shard>
<internal_replication>true</internal_replication>
<replica>
<default_database>testcluster_shard_1</default_database>
<host>cluster_node_1</host>
</replica>
<replica>
<default_database>testcluster_shard_1</default_database>
<host>cluster_node_2</host>
</replica>
</shard>
现在让我们尝试定义与此配置相对应的shard表。
数据库架构
如上所述,为了在同一节点上彼此分离碎片,需要特定于碎片的数据库。
- 第1个节点架构
- testcluster_shard_1
- testcluster_shard_3
- 第2个节点架构
- testcluster_shard_2
- testcluster_shard_1
- 第3个节点架构
- testcluster_shard_3
- testcluster_shard_2
复制表架构
现在让我们为碎片设置复制表。ReplicatedMergeTree表定义需要两个重要参数:
Zookeeper中的表碎片路径
副本标记
Zookeeper路径对于每个碎片都应该是唯一的,副本标记在每个特定碎片中都应该是唯一的:
第1个节点:
CREATE TABLE testcluster_shard_1.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_1/events’, ‘replica_1’, …)
CREATE TABLE testcluster_shard_3.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_3/events’, ‘replica_2’, …)第2个节点
CREATE TABLE testcluster_shard_2.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_2/events’, ‘replica_1’, …)
CREATE TABLE testcluster_shard_1.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_1/events’, ‘replica_2’, …)第3个节点
CREATE TABLE testcluster_shard_3.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_3/events’, ‘replica_1’, …)
CREATE TABLE testcluster_shard_2.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_2/events’, ‘replica_2’, …)分布式表架构
剩下的就是分布式表。为了让ClickHouse为本地shard表选择合适的默认数据库,需要使用空数据库创建分布式表。这就触发了默认值的使用。
CREATE TABLE tc_distributed
…
ENGINE = Distributed( ‘testcluster’, ‘’, tc_shard, rand() )当查询到分布式表时,ClickHouse会自动为每个本地tc_shard表添加相应的默认数据库。
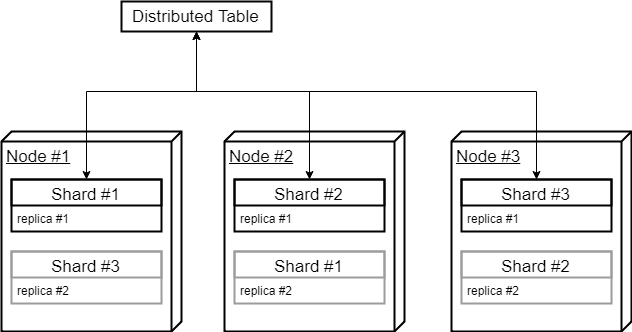
将“load_balancing”设置设置为“按顺序”是有意义的,否则,ClickHouse可能会偶尔选择第二个副本执行查询,从而导致从同一群集节点查询的两个碎片不是最佳的。
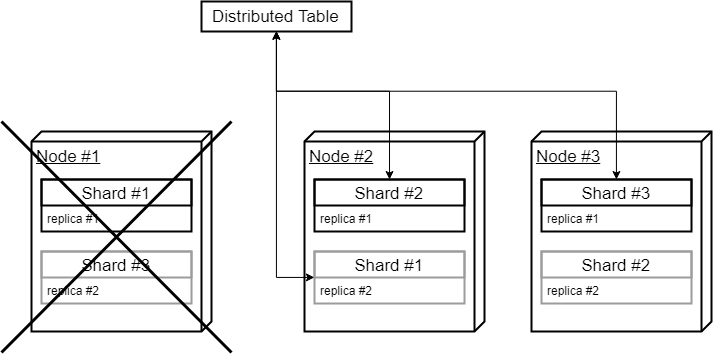
如果其中一个节点关闭,则仍有足够的数据运行查询:
结论
如上所示,可以在ClickHouse中设置循环或环形复制拓扑,但这并不简单,需要不明显的配置和额外的数据库来分离碎片和副本。除了复杂的配置之外,由于每个群集节点的双重插入负载,这种设置与单独的副本节点相比性能更差。虽然对副本重复使用相同的节点似乎很有吸引力,但在考虑循环复制部署时,需要考虑性能和配置问题。
ClickHouse中的循环复制集群拓扑的更多相关文章
- mysql组复制集群简介
mysql组复制集群拓扑: 环境: centos6.5 mysql5.7.19 一.组复制搭建: 配置hosts文件 再三台服务器上分别启动一个mysql实例,共三个. 参考配置文件如下: serve ...
- 在 TKE 中使用 Velero 迁移复制集群资源
概述 Velero(以前称为Heptio Ark)是一个开源工具,可以安全地备份和还原,执行灾难恢复以及迁移 Kubernetes 群集资源和持久卷,可以在 TKE 集群或自建 Kubernetes ...
- 【MySQL】MySQL-主从复制-集群方案-数据一致性问题解决方案 && MySQL备份的各种姿势
1.写性能如何保证:分库分表 2.读性能如何保证:主从结构,实时备份 3.一致性问题怎么解决: 3.1.微博案例:Redis缓存,热数据查询走Redis,主从的延迟通过Redis消除 3.2.支付宝的 ...
- Redis高可用复制集群实现
redis简单介绍 Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库.Redis 与其他 key - value 缓存产品有以下三个特点: 支持数据的持久化,可以将 ...
- MHA实现mysql高可用复制集群
MHA简述 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件.在My ...
- MongoDB搭建ReplSet复制集群
MongoDB的复制集是一个主从复制模式 又具有故障转移的集群,任何成员都有可能是master,当master挂掉用会很快的重新选举一个节点来充当master. 复制集中的组成主要成员 Primary ...
- Hadoop 机架(集群拓扑)设置
本文通过MetaWeblog自动发布,原文及更新链接:https://extendswind.top/posts/technical/hadoop_rack_awareness Hadoop会通过集群 ...
- Mariadb之半同步复制集群配置
首先我们来了解下在mariadb/mysql数据库主从复制集群中什么是同步,什么是异步,什么是半同步:所谓同步就是指主节点发生写操作事件,它不会立刻返回,而是等到从节点接收到主节点发送过来的写操作事件 ...
- Java应用服务器之tomcat会话复制集群配置
会话是识别用户,跟踪用户访问行为的一个手段,通过cookie(存在客户端)或session(存在服务端)来判断本次请求是那个客户端发送过来:常用的会话保持有绑定会话,就是前边我们聊的在代理上通过算法或 ...
随机推荐
- 优化sql技巧
当表很大的时候可以设计冗余字段,避免与大表连表查询造成性能低下 比如日志表和用户表,日志表通常到后期会相当的大可以做一个username的冗余字段,避免查看username的时候去和user表关联 当 ...
- 使用Google学术简单方法汇总
1 Google学术打不开,简单方法汇总. 2 谷歌学术镜像 http://dir.scmor.com/google/ 3,https://xs.glgoo.net/ 4, https://sch ...
- ent 基本使用十五 一个图遍历的例子
以下是来自官方的一个user group pet 的查询demo 参考关系图 环境准备 docker-compose mysql 环境 version: "3" services: ...
- [RN] React Native :Error: Cannot find module 'asap/raw'
今天在使用 react-native-dropdownmenus 的时候,安装没问题,但Link的时候 报: Error: Cannot find module 'asap/raw' 朋友们莫慌,一步 ...
- 第02组 Alpha冲刺(3/4)
队名:十一个憨批 组长博客 作业博客 组长黄智 过去两天完成的任务:写博客,复习C语言 GitHub签入记录 接下来的计划:构思游戏实现 还剩下哪些任务:敲代码 燃尽图 遇到的困难:Alpha冲刺时间 ...
- linux高性能服务器编程 (六) --高级I/O函数
第六章 高级I/O函数 Linux提供了很多高级的I/O函数,它不是基础的I/O函数(open/read) 1.创建文件描述符的函数比如:pipe.dup/dup2函数 2.读写数据的函数比如:rea ...
- 织梦一二级导航菜单被点击顶级栏目高亮(加class)解决方法
织梦一二级导航菜单被点击的栏目高亮显示方法详解,废话不多说直接举例说明: 织梦一级菜单被点击栏目高亮调用方法: {dede:channel typeid ='1' type ='son' curre ...
- <每日 1 OJ> -LeetCode 28. 实现 strStr()
题目: 实现 strStr() 函数. 给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始).如果不存 ...
- Spring项目中Properties不能加载多个的问题
A模块和B模块都分别拥有自己的Spring XML配置,并分别拥有自己的配置文件: A模块 A模块的Spring配置文件如下: <?xml version="1.0" enc ...
- abp 中log4net 集成Kafka
1.安装包 Install-Package log4net.Kafka.Core 2.修改log4net.config 配置文件 <?xml version="1.0" en ...