python系列:二、Urllib库的高级用法
1.设置Headers
有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性。
打开我们的浏览器,调试浏览器F12,出现一个新的界面,实质上这个页面包含了许许多多的内容,这些内容也不是一次性就加载完成的,实质上是执行了好多次请求,一般是首先请求HTML文件,然后加载JS,CSS 等等,经过多次请求之后,网页的骨架和肌肉全了,整个网页的效果也就出来了。
拆分这些请求,我们只看一第一个请求,你可以看到,有个Request URL,还有headers,下面便是response。
其中,agent就是请求的身份,如果没有写入请求身份,那么服务器不一定会响应,所以可以在headers中设置agent。

这样,我们设置了一个headers,在构建request时传入,在请求时,就加入了headers传送,服务器若识别了是浏览器发来的请求,就会得到响应。
另外headers的一些属性,下面的需要特别注意一下:
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
其他的有必要的可以审查浏览器的headers内容,在构建时写入同样的数据即可。
headers = { 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' , 'Referer':'http://www.zhihu.com/articles' }
同上面的方法,在传送请求时把headers传入Request参数里,这样就能应付防盗链了。
另外headers的一些属性,下面的需要特别注意一下:
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
其他的有必要的可以审查浏览器的headers内容,在构建时写入同样的数据即可。
2. Proxy(代理)的设置
urllib 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。假如一个网站它会检测某一段时间某个IP 的访问次数,如果访问次数过多,它会禁止你的访问。所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理。

3.Timeout 设置
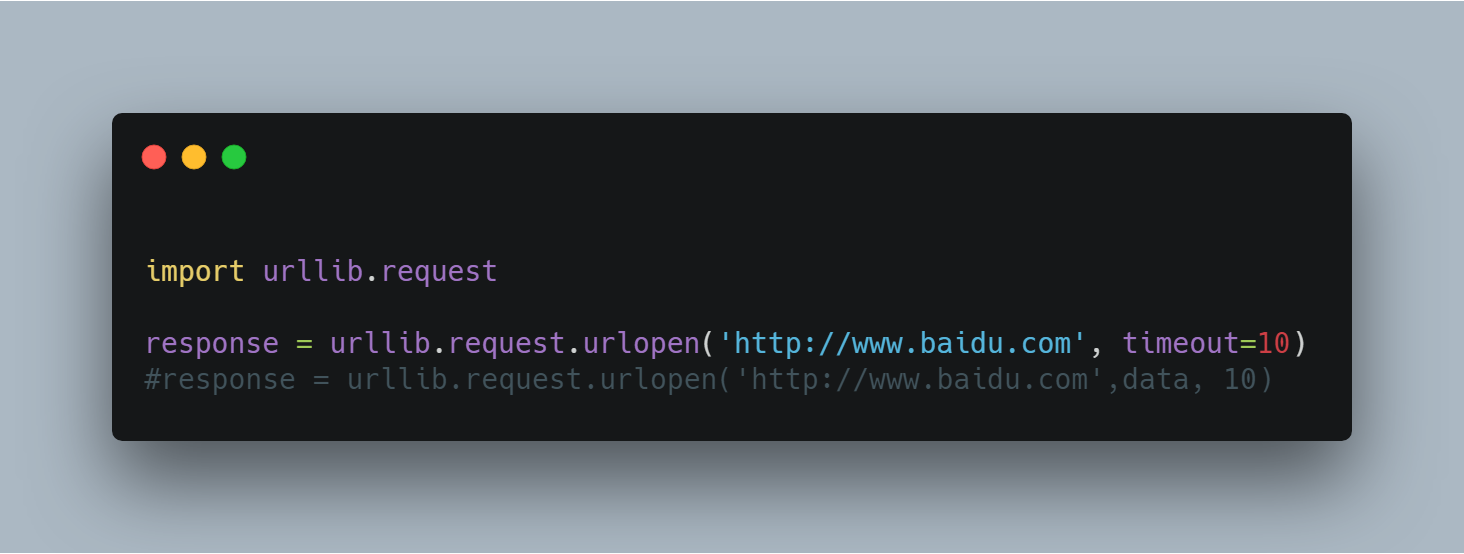
如果第二个参数data为空那么要特别指定是timeout是多少,写明形参,如果data已经传入,则不必声明。
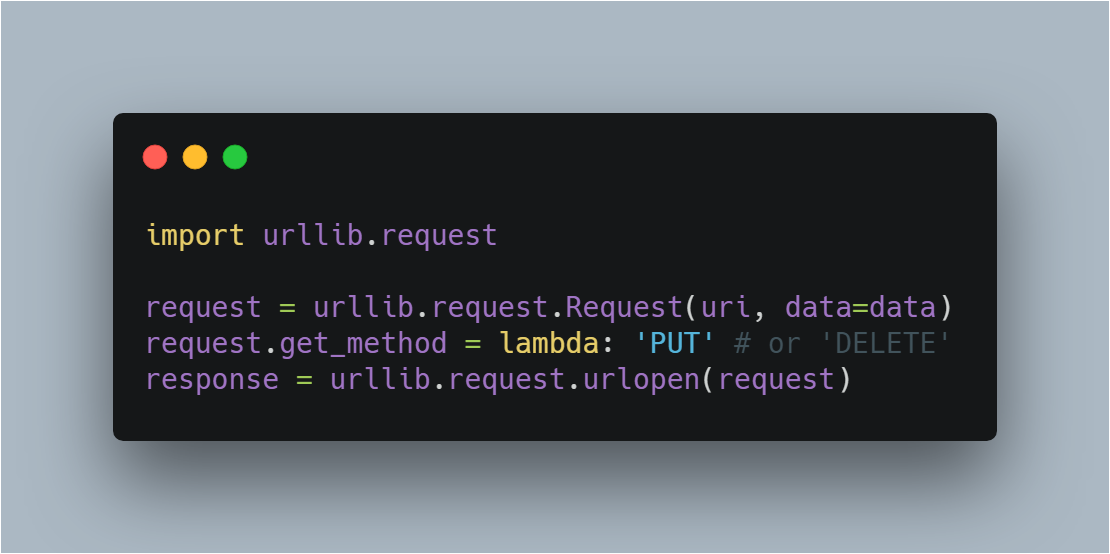
4.使用 HTTP 的 PUT 和 DELETE 方法
http协议有六种请求方法,get,head,put,delete,post,options,我们有时候需要用到PUT方式或者DELETE方式请求。
PUT:这个方法比较少见。HTML表单也不支持这个。本质上来讲, PUT和POST极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。
DELETE:删除某一个资源。基本上这个也很少见,不过还是有一些地方比如amazon的S3云服务里面就用的这个方法来删除资源。
如果要使用 HTTP PUT 和 DELETE ,只能使用比较低层的 httplib 库。虽然如此,我们还是能通过下面的方式,使 urllib2 能够发出 PUT 或DELETE 的请求,不过用的次数的确是少,在这里提一下。
5.使用DebugLog
可以通过下面的方法把 Debug Log 打开,这样收发包的内容就会在屏幕上打印出来,方便调试,这个也不太常用,仅提一下

以上便是一部分高级特性,前三个是重要内容,在后面,还有cookies的设置还有异常的处理。
python系列:二、Urllib库的高级用法的更多相关文章
- python 爬虫2 Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. import url ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- Python爬虫入门(3-4):Urllib库的高级用法
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
- Python爬虫 Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 芝麻HTTP: Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 4.Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
随机推荐
- Linux内核链表复用实现队列
有了前面Linux内核复用实现栈的基础,使用相同的思想实现队列,也是非常简单的.普通单链表复用实现队列,总会在出队或入队的时候有一个O(n)复杂度的操作,大多数采用增加两个变量,一个head,一个ta ...
- JAVA中String空对象的字符串拼接
今天使用JSONObject中get一个不存在的对线,最后拼接成sql语句插入数据库时,最后数据库中的值为字符串'null',而不是空对象. 追踪许久才发现自己的java白学了. java strin ...
- C# 动态执行JS
有时候需要,在程序中灵活的嵌入自定义的计算逻辑,使用C#加载JS脚本形式可以实现: // 添加引用 using Microsoft.JScript; string jsStr = "var ...
- MySQL 使用 ON UPDATE CURRENT_TIMESTAMP 自动更新 timestamp (转)
原文地址: https://blog.csdn.net/heatdeath/article/details/79833492 `create_time` timestamp not null defa ...
- JZ落选跟我们有什么关系
今天中午睡前刷了一下微博,看到JZ派落选了,底下一大堆冷嘲热讽的. 比如,养了一堆白眼狼,给了XG一堆利好政策,却这样FZ. 这种心态像极了多子女家庭的生活. 多子女家庭里,总有几个是性格比较乖巧,也 ...
- Docker实践之04-操作容器
目录 一.查看容器列表 二.启动容器 三.终止容器 四.重启容器 五.后台运行容器 六.获取容器输出信息 七.进入容器 八.导出和导入容器 九.删除容器 一.查看容器列表 可以使用命令docker c ...
- Centos7之阿里Arthas部署
阿里Arthas Arthas(阿尔萨斯)是Alibaba开源的一个Java诊断工具,无需做任何配置,就可以直观的获取各种维度的性能数据,方便开发者进行问题的定位和诊断. 应用场景 动态跟踪Java代 ...
- java核心技术(卷一)
一,java基本程序设计结构: 1,在网页中运行的 Java 程序称为 applet. 要使用 applet ,需要启用 Java 的 Web 浏览器执行字节码. 2,jdk安装目录下的 src.zi ...
- 浅谈PageRank
浅谈PageRank 2017-04-25 18:00:09 guoziqing506 阅读数 17873更多https://blog.csdn.net/guoziqing506/article/de ...
- 1-3docker commit定制镜像
以定制⼀个 Web 服务器为例⼦ 1.commit定制镜像 docker pull nginx:1.17 运行容器 --name:容器名字 -d:后台 -p本地端口:容器内端口 docker ru ...