交互式计算引擎MOLAP篇
交互式计算引擎MOLAP篇
摘自:《大数据技术体系详解:原理、架构与实践》
MOLAP是一种通过预计算cube方式加速查询的OLAP引擎,它的核心思想是“空间换时间”,典型代表包括Druid和Kylin。
一.Druid简介
Druid是一个用于大数据实时查询和分析的高容错,高性能开源分布式OLADP系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。 Durid是基于列存储的,其设计之初主要目的是存储时间序列数据,因此数据强制按照时间分隔不同的数据段(segment),除了时间戳以外,一个数据段中还有纬度(dimension)和度量(metric)两种类型的列。 Durid能够快速对数据进行过滤和聚合,它常用来给一些面向分析人员的应用提供查询引擎。有些大规模的Druid集群每秒钟能够插入数十亿条事件并提供上千次的查询。 Druid官网网站:http://druid.io/。

Druid整个架构由实时线和批处理线两部分构成,本质上是对Lamaba架构的一种实现。如上图所示,Druid系统主要由三个外部依赖:用于分布式协调服务的zookeeper;存储集群数据信息和相关规则的Metadata Storage;存放备份数据的Deep Stroage。
Druid节点类型比较多,可以从三个方面了解系统架构:
(1)首先,从外部看,提供查询接口的节点是Broker节点,它根据具体的情况可能会将查询分发到实时(Real-time)节点或历史(Historical)节点,前者存放实时数据,后者存放历史数据;
(2)其次,从集群内部看,负责协调数据存储的是Coorinator节点,它读取Metadata,通过Zookeeper通知不同的Historical节点应当载入或丢弃哪些数据段;
(3)最后,从数据Ingest来看,可以将实时数据交给Real-time节点进行处理(real-time index),也可以直接将数据建好索引存放到Deep Storage中,然后更新Metadata(batch index),现在Druid提倡用Indexing Service来统一处理两种数据Ingest的情况。
二.Kylin简介
Kylin是Hadoop生态圈下的一个MOLAP系统,是ebay大数据部门从2014年开始研发的支持TB到PB级别数据量的分布式OLAP分析引擎。其特点包括:
(1)可扩展的超快OLAP引擎;
(2)提供ANSI-SQL接口;
(3)交互式查询能力;
(4)引入MOLAP Cube的概念以加速分析过程。
(5)支持JDBC/RESTful等访问方式,与BI工具可无缝整合。
Kylin的核心思想是利用空间换时间,它通过预计算,将查询结果预先存储到HBase上以加快数据处理效率。 Kylin官网网站:http://kylin.apache.org/。
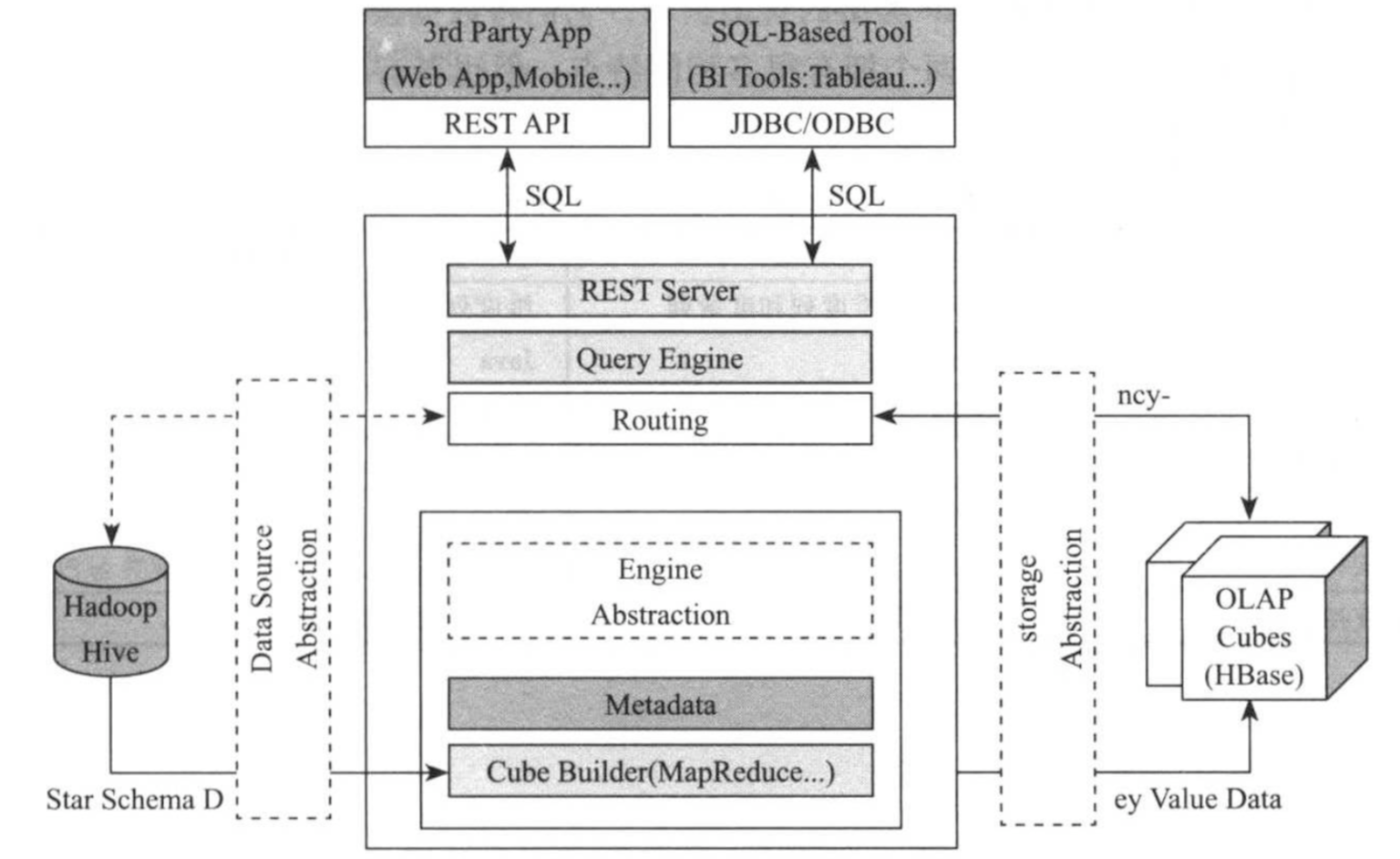
Kylin实现过程复用了大量开源系统,具体如上图所示。
RESST Server:
提供一些RESTful接口,例如创建cube,构建cube,刷新cube,合并cube等cube相关操作,元数据管理,用户访问权限,系统配置动态修改等。
JDBC/ODBC接口:
Kylin提供了JDBC驱动,使用JDBC接口的查询和使用RESTful接口的查询内部实现流程是相同的。这类接口使用Kyin能够兼容各种可视化工具,包括tableau和mondrian等。
Query引擎:
Kylin使用一个开源的calcite框架实现SQL的解析,相当于SQL引擎层。
calcite官网网站:http://calcite.apache.org/.
Routing:
该模块负责将SQL生成的执行计划转换成面向cube缓存的查询。cube是通过预计算缓存在HBase中,这些查询只需从HBase直接获取结果返回即可,一般在妙计甚至毫秒级完成。
Metadata:
Kylin中包含大量的元数据信息,包括cube的定义,星状模型的定义,作业的信息,作业的输出嘻嘻,纬度的存放目录信息等,元数据和cube都存储在Hbase中。
Cube构建引擎:
负责预计算方式的构建cube,这是通过MapReduce/Spark计算生成HTable然后加载到HBase中完成的。
三.Druid于Kylin对比
Druid与kylin均是MOLAP类型的查询引擎,它们将数据按照多维度数据方式存储,并通过索引方式加速计算。它们两个拥有很多相同特点,但也各有自己的特色,它们的异同对比如下图所示。

交互式计算引擎MOLAP篇的更多相关文章
- 交互式计算引擎REOLAP篇
交互式计算引擎ROLAP篇 摘自:<大数据技术体系详解:原理.架构与实践> 一.Impala Impala最初由Cloudera公司开发的,其最初设计动机是充分结合传统数据库与大数据系 ...
- 奇点云数据中台技术汇(三)| DataSimba系列之计算引擎篇
随着移动互联网.云计算.物联网和大数据技术的广泛应用,现代社会已经迈入全新的大数据时代.数据的爆炸式增长以及价值的扩大化,将对企业未来的发展产生深远的影响,数据将成为企业的核心资产.如何处理大数据,挖 ...
- 【Spark深入学习 -13】Spark计算引擎剖析
----本节内容------- 1.遗留问题解答 2.Spark核心概念 2.1 RDD及RDD操作 2.2 Transformation和Action 2.3 Spark程序架构 2.4 Spark ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- 一文让你彻底了解大数据实时计算引擎 Flink
前言 在上一篇文章 你公司到底需不需要引入实时计算引擎? 中我讲解了日常中常见的实时需求,然后分析了这些需求的实现方式,接着对比了实时计算和离线计算.随着这些年大数据的飞速发展,也出现了不少计算的框架 ...
- 阿里蒋晓伟谈计算引擎Flink和Spark的对比
本文整理自云栖社区之前对阿里搜索事业部资深搜索专家蒋晓伟老师的一次采访,蒋晓伟老师,认真而严谨.在加入阿里之前,他曾就职于西雅图的脸书,负责过调度系统,Timeline Infra和Messenger ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 基于Kafka的实时计算引擎如何选择?(转载)
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
随机推荐
- saltstack执行state.sls耗时长的坑
一直用的 jenkins + saltstack 自动化构建发布项目,一共也就不超过20台服务器,奈何运行时间越来越慢,并且负载越来越高(这里大部分都是使用state模块),但是不用state模块效率 ...
- Laya的Tween缓动没有初始化repeat导致的Bug
当你使用一个Tween给一个图标做旋转动画,循环播放.(repeat是播放次数, repeat=0无限循环,repeat=1播放一次) Laya.Tween.to(this.light,{rotati ...
- PCL贪婪投影三角化算法
贪婪投影三角化算法是一种对原始点云进行快速三角化的算法,该算法假设曲面光滑,点云密度变化均匀,不能在三角化的同时对曲面进行平滑和孔洞修复. 方法: (1)将三维点通过法线投影到某一平面 (2)对投影得 ...
- idea关闭sonarLint自动扫描
手动运行SonarLint 停止SonarLint自动检测代码之后,可以使用Ctrl+Shift+S手动运行SonarLint检查代码
- linux-pdb命令行下python断点调试工具
一般地,我们可以使用如下的方式进入调试(比如我们要调试的源文件为hello.py): 1. 在命令行启动目标程序,加上-m参数. python -m pdb hello.py 这样程序会自动停在第 ...
- Sublime Text3安装LESS
Sublime Text3安装LESS 1.Sublime Text3利用Package Control安装LESS插件.LESS2CSS插件 2.去node官网下载node.js http://no ...
- Spring RestTemplate的使用示例
@Bean注册一个RestTemplate: 调用服务: 因为要参与网络传输,所以要实现序列化接口:
- quartz2.3.0(十一)任务执行中故障情况,可设置重新执行任务
任务类 package org.quartz.examples.example11; import org.quartz.Job; import org.quartz.JobExecutionCont ...
- Elasticsearch-6.7.0系列(六)ES设置集群密码
感谢此老兄:<手把手教你搭建一个 Elasticsearch 集群> 前提准备 安装kibana-6.7.0: <Elasticsearch-6.7.0系列(三)5601端口 kib ...
- Java设计模式之委派模式(Dellegate/Dispather)
概述: 委派模式有点像代理模式又有点像策略模式. 区别在于代理模式注重过程,委派模式注重结果. 生活中也有很多委派模式的例子:例如公司老板给项目经理下达任务,将任务全权交给项目经理,有项目经理根据一定 ...