19、Executor原理剖析与源码分析
一、原理图解
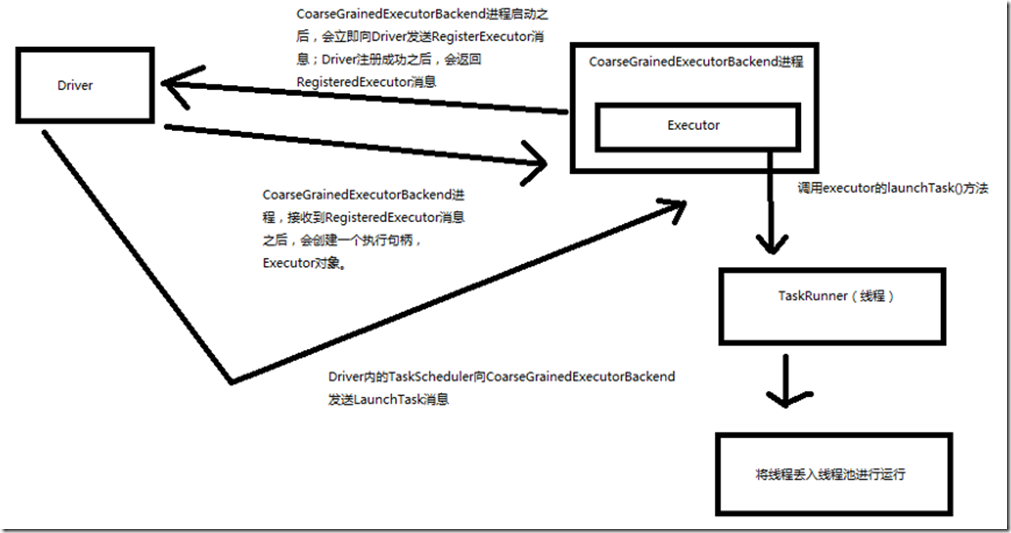
二、源码分析
1、Executor注册机制
worker中为Application启动的executor,实际上是启动了这个CoarseGrainedExecutorBackend进程; Executor注册机制:
###org.apache.spark.executor/CoarseGrainedExecutorBackend.scala /**
* 在actor的初始化方法中
*/
override def preStart() {
logInfo("Connecting to driver: " + driverUrl)
// 获取了driver的executor
driver = context.actorSelection(driverUrl)
// 向driver发送RegisterExecutor消息,driver是CoarseGrainedSchedulerBackend的一个内部类
// driver注册executor成功之后,会发送回来RegisteredExecutor消息
driver ! RegisterExecutor(executorId, hostPort, cores, extractLogUrls)
context.system.eventStream.subscribe(self, classOf[RemotingLifecycleEvent])
} ###org.apache.spark.executor/CoarseGrainedExecutorBackend.scala override def receiveWithLogging = {
// driver注册executor成功之后,会发送回来RegisteredExecutor消息
// 此时,CoarseGrainedExecutorBackend会创建Executor对象,作为执行句柄
// 其实它的大部分功能,都是通过Executor实现的
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
val (hostname, _) = Utils.parseHostPort(hostPort)
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
3、启动Task
###org.apache.spark.executor/CoarseGrainedExecutorBackend.scala
// 启动task
case LaunchTask(data) =>
if (executor == null) {
logError("Received LaunchTask command but executor was null")
System.exit(1)
} else {
// 反序列化task
val ser = env.closureSerializer.newInstance()
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
// 用内部的执行句柄,Executor的launchTask()方法来启动一个task
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
###org.apache.spark.executor/Executor.scala
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer) {
// 对于每一个task,都会创建一个TaskRunner
// TaskRunner继承的是Java多线程中的Runnable接口
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
// 将TaskRunner放入内存缓存
runningTasks.put(taskId, tr)
// Executor内部有一个Java线程池,这里其实将task封装在一个线程中(TaskRunner),直接将线程丢入线程池,进行执行
// 线程池是自动实现了排队机制的,也就是说,如果线程池内的线程暂时没有空闲的,那么丢进去的线程都是要排队的
threadPool.execute(tr)
}
19、Executor原理剖析与源码分析的更多相关文章
- 65、Spark Streaming:数据接收原理剖析与源码分析
一.数据接收原理 二.源码分析 入口包org.apache.spark.streaming.receiver下ReceiverSupervisorImpl类的onStart()方法 ### overr ...
- 18、TaskScheduler原理剖析与源码分析
一.源码分析 ###入口 ###org.apache.spark.scheduler/DAGScheduler.scala // 最后,针对stage的task,创建TaskSet对象,调用taskS ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- 22、BlockManager原理剖析与源码分析
一.原理 1.图解 Driver上,有BlockManagerMaster,它的功能,就是负责对各个节点上的BlockManager内部管理的数据的元数据进行维护, 比如Block的增删改等操作,都会 ...
- 20、Task原理剖析与源码分析
一.Task原理 1.图解 二.源码分析 1. ###org.apache.spark.executor/Executor.scala /** * 从TaskRunner开始,来看Task的运行的工作 ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- 21、Shuffle原理剖析与源码分析
一.普通shuffle原理 1.图解 假设有一个节点上面运行了4个 ShuffleMapTask,然后这个节点上只有2个 cpu core.假如有另外一台节点,上面也运行了4个ResultTask,现 ...
- 23、CacheManager原理剖析与源码分析
一.图解 二.源码分析 ###org.apache.spark.rdd/RDD.scalal ###入口 final def iterator(split: Partition, context: T ...
- 16、job触发流程原理剖析与源码分析
一.以Wordcount为例来分析 1.Wordcount val lines = sc.textFile() val words = lines.flatMap(line => line.sp ...
随机推荐
- git 学习笔记 ---撤销修改
自然,你是不会犯错的.不过现在是凌晨两点,你正在赶一份工作报告,你在readme.txt中添加了一行: $ cat readme.txt Git is a distributed version co ...
- 子进程的LD_PRELOAD
一个指定LD_PRELOAD的进程创建的子进程是否受LD_PRELOAD的影响? 1. fork()后在子进程中执行函数. main.c #include <unistd.h> #incl ...
- 纯 CSS 画 iphone
好几天没有更新了,直接上效果吧,哈哈!(我想这个应该大部分都会!哈哈哈!) 代码如下: html: <div class="container"> <div cl ...
- python图片二值化提高识别率
import cv2from PIL import Imagefrom pytesseract import pytesseractfrom PIL import ImageEnhanceimport ...
- Spring事务传播机制与隔离机制
详情查看 https://www.jianshu.com/p/249f2cd42692
- 【转】如何使用jupyter编写数学公式(译)
[1.如何使用jupyter编写数学公式(译)][1] [1]: https://www.jianshu.com/p/93ccc63e5a1b
- 使用maven导入module时,报java.security.InvalidAlgorithmParameterException: the trustAnchors parameter must be non-empty
在新装IDEA导入Flink源码时出现一些问题,在此记录,希望能帮到大伙! 一.环境 IDEA2019.1.2(破解版):OpenJDK 1.8.0_40:Maven 3.5.3/3.2.5/3.6. ...
- 191011 python3-format函数
# 题目:一球从100米高度自由落下,每次落地后反跳回原高度的一半:# 再落下,求它在第10次落地时,共经过多少米?第10次反弹多高?方法一: l = 100.0 s = 100 for i in r ...
- Mongodb Sharding 集群配置
mongodb的sharding集群由以下3个服务组成: Shards Server: 每个shard由一个或多个mongod进程组成,用于存储数据 Config Server: 用于存储集群的M ...
- Java Map的正确使用方式
原文:https://www.liaoxuefeng.com/article/1256136507802816 正确使用Map,只需要正确实现hashCode()和equals()就行了吗? 恐怕还不 ...