redis渐进式 rehash
转载(http://redisbook.com/preview/dict/incremental_rehashing.html)
上一节说过, 扩展或收缩哈希表需要将 ht[0] 里面的所有键值对 rehash 到 ht[1] 里面, 但是, 这个 rehash 动作并不是一次性、集中式地完成的, 而是分多次、渐进式地完成的。
这样做的原因在于, 如果 ht[0] 里只保存着四个键值对, 那么服务器可以在瞬间就将这些键值对全部 rehash 到 ht[1] ; 但是, 如果哈希表里保存的键值对数量不是四个, 而是四百万、四千万甚至四亿个键值对, 那么要一次性将这些键值对全部 rehash 到 ht[1] 的话, 庞大的计算量可能会导致服务器在一段时间内停止服务。
因此, 为了避免 rehash 对服务器性能造成影响, 服务器不是一次性将 ht[0] 里面的所有键值对全部 rehash 到 ht[1] , 而是分多次、渐进式地将 ht[0] 里面的键值对慢慢地 rehash 到 ht[1] 。
以下是哈希表渐进式 rehash 的详细步骤:
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
图 4-12 至图 4-17 展示了一次完整的渐进式 rehash 过程, 注意观察在整个 rehash 过程中, 字典的 rehashidx 属性是如何变化的。
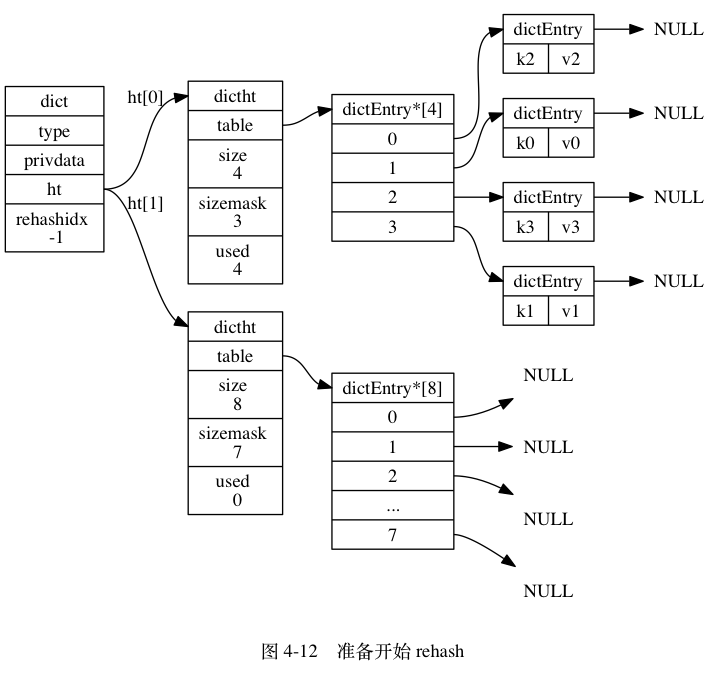
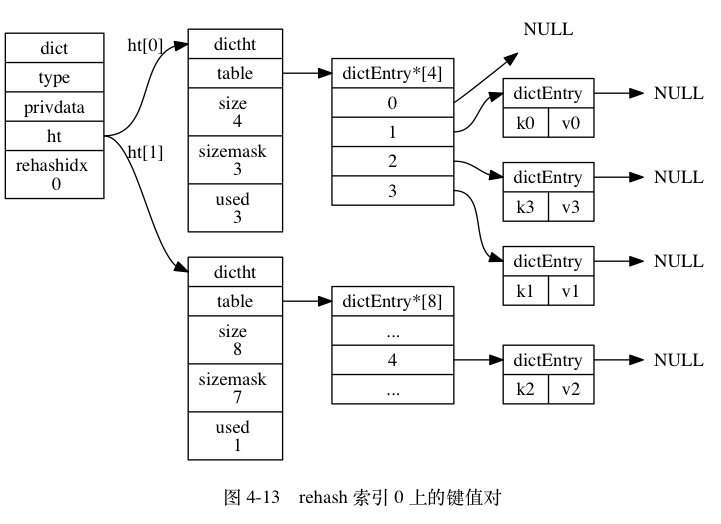
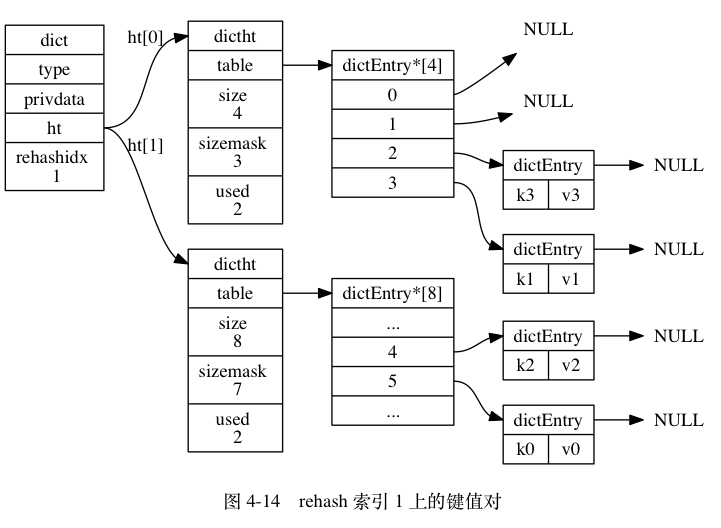
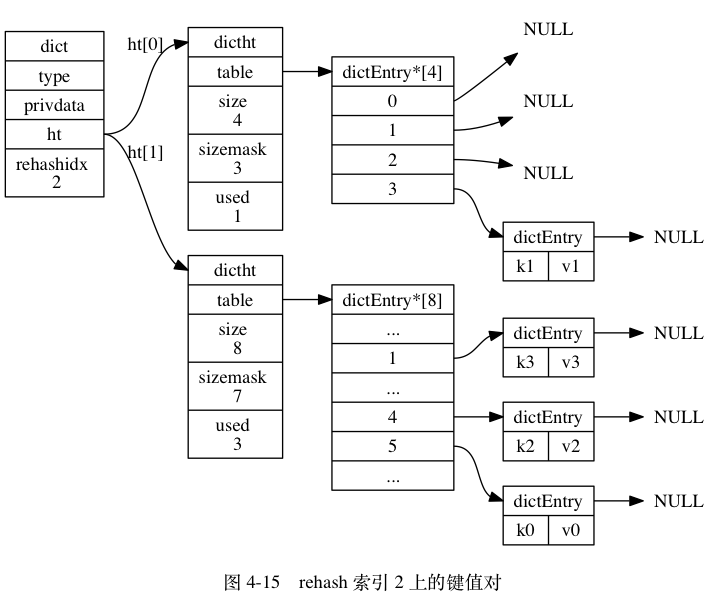
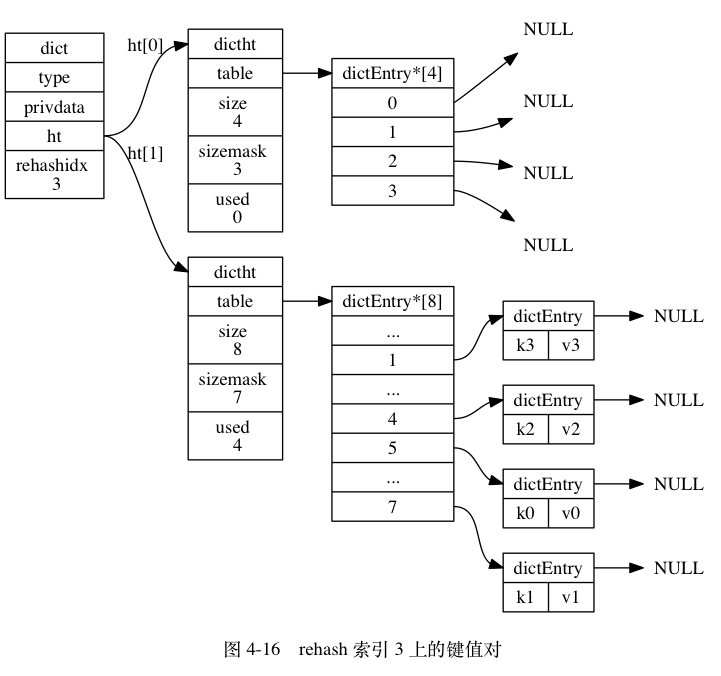
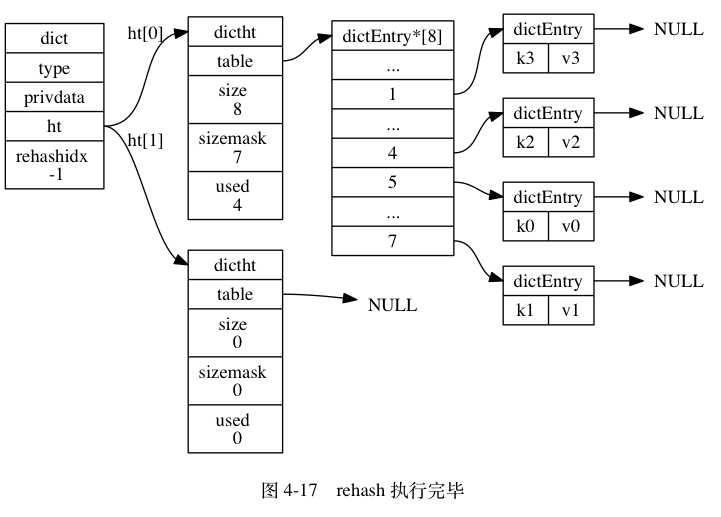
渐进式 rehash 执行期间的哈希表操作
因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0]里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
redis渐进式 rehash的更多相关文章
- redis渐进式rehash机制
在Redis中,键值对(Key-Value Pair)存储方式是由字典(Dict)保存的,而字典底层是通过哈希表来实现的.通过哈希表中的节点保存字典中的键值对.我们知道当HashMap中由于Hash冲 ...
- redis字典快速映射+hash釜底抽薪+渐进式rehash | redis为什么那么快
前言 相信你一定使用过新华字典吧!小时候不会读的字都是通过字典去查找的.在Redis中也存在相同功能叫做字典又称为符号表!是一种保存键值对的抽象数据结构 本篇仍然定位在[redis前传]系列中,因为本 ...
- redis的rehash过程
在扩容和收缩的时候,如果哈希字典中有很多元素,一次性将这些键全部rehash到ht[1]的话,可能会导致服务器在一段时间内停止服务.所以,采用渐进式rehash的方式,详细步骤如下: 为ht[1]分配 ...
- 图解Redis之数据结构篇——字典
前言 字典在Redis中的应用非常广泛,数据库与哈希对象的底层实现就是字典. 系列文章 图解Redis之数据结构篇--简单动态字符串SDS 图解Redis之数据结构篇--链表 图解Redis之 ...
- Java后端技术面试汇总(第四套)
1.Java基础 • 为什么JVM调优经常会将-Xms和-Xmx参数设置成一样:• Java线程池的核心属性以及处理流程:• Java内存模型,方法区存什么:• CMS垃圾回收过程:• Full GC ...
- 拿捏了!ConcurrentHashMap!
概述 本文将对JDK8中 ConcurrentHashMap 源码进行一定程度的解读.解读主要分为六个部分:主要属性与相关内部类介绍.构造函数.put过程.扩容过程.size过程.get过程.与JDK ...
- Redis的字典(dict)rehash过程源代码解析
Redis的内存存储结构是个大的字典存储,也就是我们通常说的哈希表.Redis小到能够存储几万记录的CACHE,大到能够存储几千万甚至上亿的记录(看内存而定),这充分说明Redis作为缓冲的强大.Re ...
- 美团针对Redis Rehash机制的探索和实践
背景 Squirrel(松鼠)是美团技术团队基于Redis Cluster打造的缓存系统.经过不断的迭代研发,目前已形成一整套自动化运维体系,涵盖一键运维集群.细粒度的监控.支持自动扩缩容以及热点Ke ...
- 《闲扯Redis八》Redis字典的哈希表执行Rehash过程分析
一.前言 随着操作的不断执行, 哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的负载因子(load factor)维持在一个合理的范围之内, 当哈希表保存的键值对数量太多或者太少时, 程序需要 ...
随机推荐
- ssh远程登录连接慢的解决方法
近期在搭建自动化集群服务,写脚本ssh批量分发公钥至其它服务器时比较缓慢,便在度娘上寻找解决方法如下: 方法一: 以ssh -v 调试模式远程登录: [root@bqh-nfs- ceshi]# ss ...
- mybatis中如何将多个表的查询结果,放入结果集中返回
1.首先需要将resultMap进行改造,为了避免对其他sql的影响建议另外定义一个resultMapExtral,避免id相同, 2.然后在resultMapExtral中添加其它表的字段,若多个表 ...
- Flask统计代码行数
流程: 1.获取前端的文件 2.判断文件是否zip文件 3.解压压缩包并保存 4.遍历解压后的文件夹 5.判断文件是否py文件,将绝对路径添加到列表 6.循环列表,排除注释和空号,统计行数 from ...
- 批处理引擎MapReduce应用案例
批处理引擎MapReduce应用案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. MapReduce能够解决的问题有一个共同特点:任务可以被分解为多个子问题,且这些子问题相对独立 ...
- ISCC之msc_无法运行的exe
打开hxd,里面老长一串base64 解码试了一下,解出来是png文件头,但是图片有错误 百度了一下,PNG文件头是89 50 4E 47 0D 0A 1A 0A 再回去看 改成0A了事, 出来一张二 ...
- rxjs 入门--环境配置
原文: https://codingthesmartway.com/getting-started-with-rxjs-part-1-setting-up-the-development-enviro ...
- workerman——消息推送(web-msg-send)
前言 说下场景,当后台将号码池的号码分配给指定客服的时候,需要给指定的客户推送一条消息告诉该客户,通讯录有新增数据. 步骤 下载 https://www.workerman.net/web-sende ...
- kvm创建win7虚拟机默认只识别2个cpu解决方法
现在人在部署OpenStack之后会发现按照配额运行Linux的虚拟机没有问题,但是运行windows的虚拟机会发现如果配置2个以上的核则无法识别,windows server也最多支持到4个核.无法 ...
- H5性能测试,首屏时间统计(Argus)
Argus 腾讯质量开发平台,官网链接:https://wetest.qq.com/product/argus 主要针对性:H5的游戏性能测试 主要介绍: 独家首屏时间统计: 告别人工掐秒 自动统计首 ...
- cookies localStorage和sessionStorage的区别
sessionStorage用于本地存储一个会话(session)中的数据,这些数据只有在同一个会话中的页面才能访问并且当会话结束后数据也随之销毁.因此sessionStorage不是一种持久化的本地 ...