DataPipeline丨LinkedIn元数据之旅的最新进展—Data Hub

作者:Mars Lan, Seyi Adebajo, Shirshanka Das
译者: DataPiepline yaran
作为全球最大的职场社交平台,LinkedIn的数据团队不断致力于扩展其基础架构,以满足不断增长的大数据生态系统需求。随着数据量和丰富度的增长,对数据科学家和工程师而言:发现数据资产,理解它们的来源并基于这些见解采取适当的行动变得愈发具有挑战。
为了在数据增长的同时继续扩展数据的生产力和创新力,我们创建了一个通用的元数据搜索和发现工具Data Hub。
一、扩展元数据
为提高LinkedIn数据团队的工作效率,我们之前开发并开源了WhereHows,一个中央元数据存储库和数据集门户。存储的元数据类型包括技术元数据(例如,位置、模式、分区、所有权)和过程元数据(例如,沿袭、作业执行、生命周期信息)。WhereHows还有一个搜索引擎,以帮助定位感兴趣的数据集。
自2016年最初发布WhereHows以来,业界对通过使用元数据来提高数据科学家生产力的关注度越来越高。例如,在这个领域开发的工具包括AirBnb的Dataportal,Uber的Databook,Netflix的Metacat,Lyft的Amundsen以及最近Google的Data Catalog。在LinkedIn,我们也一直在忙于扩展我们的元数据收集范围,以便在保持公平性、隐私性和透明度的同时为新用例提供支持。但是,我们开始意识到WhereHows无法满足我们不断变化的元数据需求。以下是我们从扩展WhereHows中得到的经验总结:
1. 推比拉更好
虽然直接从源中提取元数据似乎是收集元数据最直接的方式,但开发和维护很快就会成为一场噩梦。让各个元数据提供者通过API或消息将信息推送到中央存储库的方式更具可扩展性。这种基于推送的方法还可确保更及时地反映新的和更新的元数据。
2. 通用比具体更好 WhereHows对数据集或作业的元数据应该是什么样子有着强烈意见。这就导致出现固定的API、数据模型和存储格式,一旦对元数据模型有微小地更改将导致堆栈上下的级联更改。如果我们设计一个通用的体系结构,该结构不受存储和服务的元数据模型的影响,那将更具可扩展性。这反过来将使我们能够专注于发展适合我们业务的元数据模型,而不必担心堆栈的较低层。
3. 在线与离线同样重要
一旦收集了元数据,就很自然地想要分析元数据以获得价值。一个简单的解决方案是将所有元数据转储到离线系统,如Hadoop,可以执行任意分析。但是,我们很快发现仅仅支持离线分析是不够的。例如访问控制和数据隐私处理,必须在线查询最新的元数据。
4. 关系扮演重要角色
元数据通常传达重要的关系(例如,血统,所有权和依赖关系),这些关系能够实现强大的功能,如影响分析,数据汇总,更好的搜索相关性等。将所有这些关系建模为最重要的组件并支持对它们进行有效地分析查询是非常重要的。
5. 多中心化
我们意识到仅仅围绕单个实体(数据集)建模元数据是不够的。整个生态系统的数据,代码和角色实体(数据集,数据科学家,团队,代码,微服务API,指标,AI功能,AI模型,仪表板,笔记本等)都需要集成到元数据地图。
二、一起了解下Data Hub
大约一年前,我们根据这些知识从头开始设计WhereHows。我们意识到LinkedIn越来越需要跨各种数据实体的统一的搜索和发现体验,以及将它们连接在一起的元数据图。因此,我们决定扩大项目范围,构建一个完全通用的元数据搜索和发现工具Data Hub,其雄心勃勃的愿景是:将LinkedIn员工与对他们至关重要的数据联系起来。
我们将单片WhereHows堆栈分成两个不同的堆栈:模块化UI前端和通用元数据架构后端。新架构使我们能够快速扩展元数据收集范围,而不仅仅是数据集和作业。在撰写本文时,Data Hub已经存储并索引数千万条元数据记录,这些记录包含19个不同的实体,包括数据集,指标,作业,图表,AI功能,人员和组。我们还计划在不久的将来在机器学习模型和标签,实验,仪表板,微服务API和代码上,发挥元数据的作用。
三、模块化UI
Data Hub Web应用程序是大多数用户与元数据交互的方式。该应用程序用Ember Framework编写,运行在Play中间层上。为了使开发具有可扩展性,我们充分利用各种现代化的网络技术,包括ES9,ES.Next,TypeScript, Yarn以及 Prettier和 ESLint这样的代码质量工具。展现层,控制层和数据层被模块化为包,以便应用程序中的特定视图由相关包组合构建。
组件服务框架
在应用模块化UI基础架构时,我们将Data Hub Web应用程序构建为一系列为了完成业务的组件,这些组件分组为可安装的软件包。该软件包架构在基础上使用了Yarn Workspaces和Ember附加组件,并使用Ember的组件和服务进行组件化。您可以将此视为使用小型构建块(即组件和服务)构建的UI,以创建更大的构建块(即Ember附加组件和npm / Yarn软件包),这些构建块组合在一起最终构成Data Hub Web应用程序。
将组件和服务作为应用程序的核心,该框架允许我们分离不同的方面并将应用程序中的其他功能组合在一起。此外,每一层的分段提供了一个非常可定制的架构,允许消费者扩展或简化其应用程序,以便仅利用与其领域相关的功能或构建新的元数据模型。
与Data Hub交互
在最高级别,前端提供三种类型的交互:(1)搜索,(2)浏览,(3)查看/编辑元数据。以下是一些实际应用的截图(点开看更清晰哦)

Data Hub应用截图
与典型的搜索引擎体验类似,用户可以通过提供关键字列表来搜索一种或多种类型的实体。他们可以通过筛选一系列方面来进一步实现结果。高级用户还可以使用OR,NOT和regex等运算符来执行复杂搜索。
Data Hub中的数据实体可以以树状方式组织和浏览,其中每个实体都允许出现在树中的多个位置。这使用户能够以不同的方式浏览相同的目录,例如,通过物理部署配置或业务功能组织。树中甚至有一个专门的部分,仅显示“经过认证的实体”,这些实体可通过单独的治理过程进行策划。
最终的交互视图/编辑元数据也是最复杂的一个。每个数据实体都有一个可以显示所有相关元数据的“配置文件页面”,例如,数据集配置文件页面可能包含其架构,所有权,合规性,运行状况和沿袭元数据。它还可以显示实体与其他实体之间的关系。对于可编辑的元数据,用户还可以直接通过UI进行更新。
四、通用元数据架构
为了充分实现Data Hub的愿景,我们需要一种能够使用元数据进行扩展的架构。可扩展性挑战有以下四种不同形式:
1. 建模:以开发人员友好的方式为所有类型的元数据和关系建模。
2. 获取:通过API和流,大规模获取大量元数据更改。
3. 服务:服务于收集的原始和派生元数据,以及针对元数据的各种复杂查询。
4. 索引:大规模索引元数据,并在元数据发生更改时自动更新索引。
元数据建模
简而言之,元数据是“ 提供关于其他数据的信息的数据。”在元数据建模方面,带来了两个不同要求:
1. 元数据也是数据
为模拟元数据,我们需要一种通用的建模语言。
2. 元数据是分布式的
期望所有元数据来自单一来源是不现实的。例如,管理数据集的访问控制列表(ACL)的系统很可能与存储模式元数据的系统不同。一个好的建模框架应该允许多个团队独立地发展他们的元数据模型,同时呈现与数据实体相关的所有元数据的统一视图。
我们选择利用Pegasus,这是一种由LinkedIn创建的开放源码和完善的数据模式语言。Pegasus专为通用数据建模而设计,因此适用于大多数元数据。但是,由于Pegasus没有提供模型关系或关联的明确方法,因此我们引入了一些自定义扩展来支持这些用例。
为了演示如何使用Pegasus对元数据建模,让我们看一个简单的例子,它由以下修改后的实体关系图(ERD)演示。
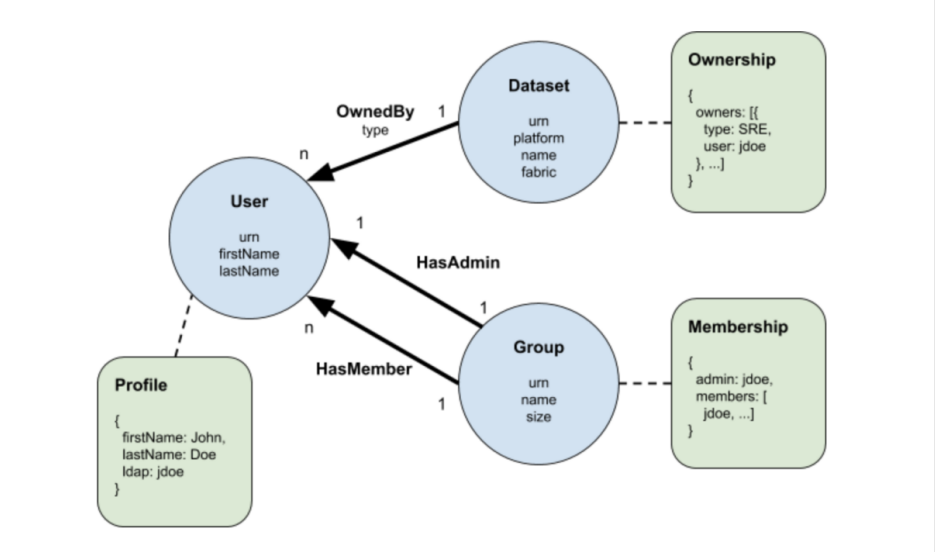
该示例包含三种类型的实体:用户、组和数据集,由图中的蓝色圆圈表示。我们用箭头来表示这些实体之间的三种关系类型,即OwnedBy,HasMember和HasAdmin。换句话说,一个组由一个管理员和多个用户组成,他们可以拥有一个或多个数据集。
与传统的ERD不同,我们将实体和关系的属性分别直接放在圆圈内和关系名称下面,以便将新类型的组件(称为“元数据方面”)附加到实体。不同的团队可以拥有和发展同一实体元数据的不同方面,而不会相互干扰,从而实现分布式元数据建模要求。三种类型的元数据方面:所有权,配置文件和成员资格在上面的示例中呈现为绿色矩形。虚线表示元数据方面与实体的关联。例如,配置文件可以与用户相关联,且所有权可以与数据集等相关联。
您可能已经注意到实体和关系属性与元数据方面存在重叠,例如,User的firstName属性应该与关联的Profile的firstName字段相同。重复的原因将在本文的后半部分进行解释。
以Pegasus为例,我们将每个实体,关系和元数据方面转换为单独的Pegasus架构文件(PDSC)。为简单起见,我们在此仅包含每个类别的一个模型。首先,让我们看一下用户实体的PDSC:
每个实体都需要具有URN形式的全局唯一ID ,可以将其视为一种类型的GUID。User实体具有包括名字,姓氏和LDAP的属性,每个属性都映射到用户记录中的可选字段。
接下来是OwnedBy关系的PDSC模型:
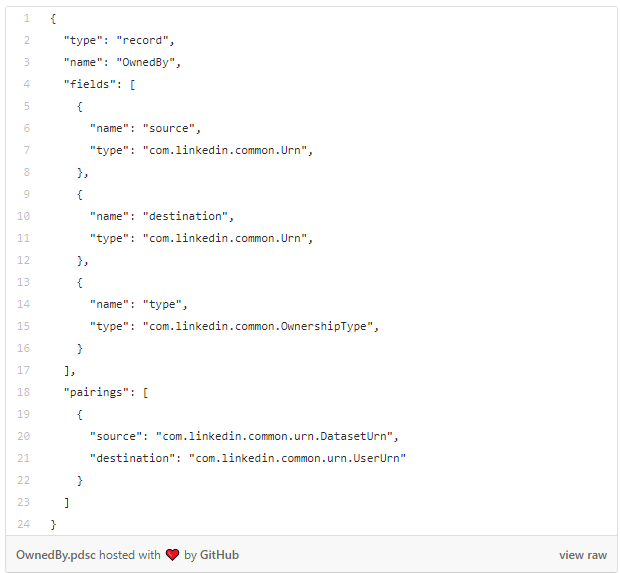
每个关系模型自然包含“源”和“目标”字段,这些字段使用其URN指向特定实体实例。该模型可以选择包含其他属性字段,例如本例中的“type”。在这里,我们还引入了一个名为“pairings”的自定义属性,以限制与特定的源和目标URN类型的关系。在这种情况下,OwnedBy关系只能用于将数据集连接到用户。
最后,您将在下面找到Ownership 元数据方面的模型。在此,我们选择将所有权建模为包含type和ldap字段的记录数组。但是,只要它是有效的PDSC记录,对于元数据方面的建模几乎没有限制。这令满足先前所述的“元数据也是数据”的要求成为可能。

在创建所有模型之后,下个问题是如何将它们连接在一起以形成所提议的ERD。我们将把这个讨论推迟到本文后面的元数据索引部分。
元数据获取
Data Hub提供两种获取元数据的形式:直接API调用或Kafka流。前者用于需要读写一致性的元数据更改,后者更适用于面向事实的更新。
Data Hub的API基于Rest.li,这是一种可扩展,强类型的RESTful服务架构,广泛用于LinkedIn。由于Rest.li使用Pegasus作为其接口定义,因此可以逐字使用上一节中定义的所有元数据模型。从API到存储需要多级模型转换的日子已经成为历史 - API和模型将始终保持同步。
对于基于Kafka的获取,元数据生成者被期望产生一个标准化的元数据改变事件(MCE),其包含一个由相应实体URN键控的对特定元数据方面的建议更改列表。MCE的格式是Apache Avro,它是由Pegasus元数据模型自动生成的。
在API和Kafka事件模式中使用相同的元数据模型,使得我们可以轻松地改进模型,而无需费力地维护相应的转换逻辑。但是,要实现真正无缝的模式演变,我们需要将所有模式更改限制为始终向后兼容。这在构建时通过添加兼容性检查强制执行。
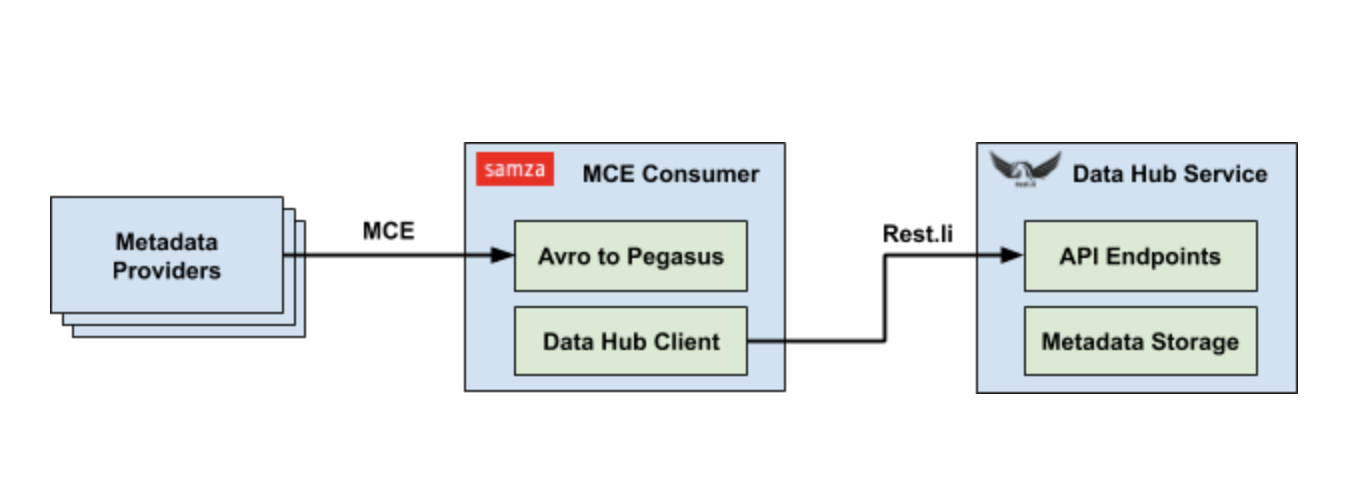
在LinkedIn,我们倾向于更多地依赖Kafka流,因为它在生产者和消费者之间提供了松散的耦合。我们每天都会收到来自不同制作人的数百万个MCE,随着扩大元数据收集的范围,预计该数量将呈指数级增长。为了构建流式元数据提取管道,我们利用Apache Samza作为流处理框架。获取Samza作业的目的是快速简单地实现高吞吐量。它只是将Avro数据转换回Pegasus并调用相应的Rest.li API来完成获取。
元数据服务
一旦摄取存储了元数据,就必须有效地提供原始元数据和派生元数据。Data Hub旨在支持四种常见的大量元数据查询:
1. 面向文档的查询
2. 面向图形的查询
3. 涉及连接的复杂查询
4. 全文检索
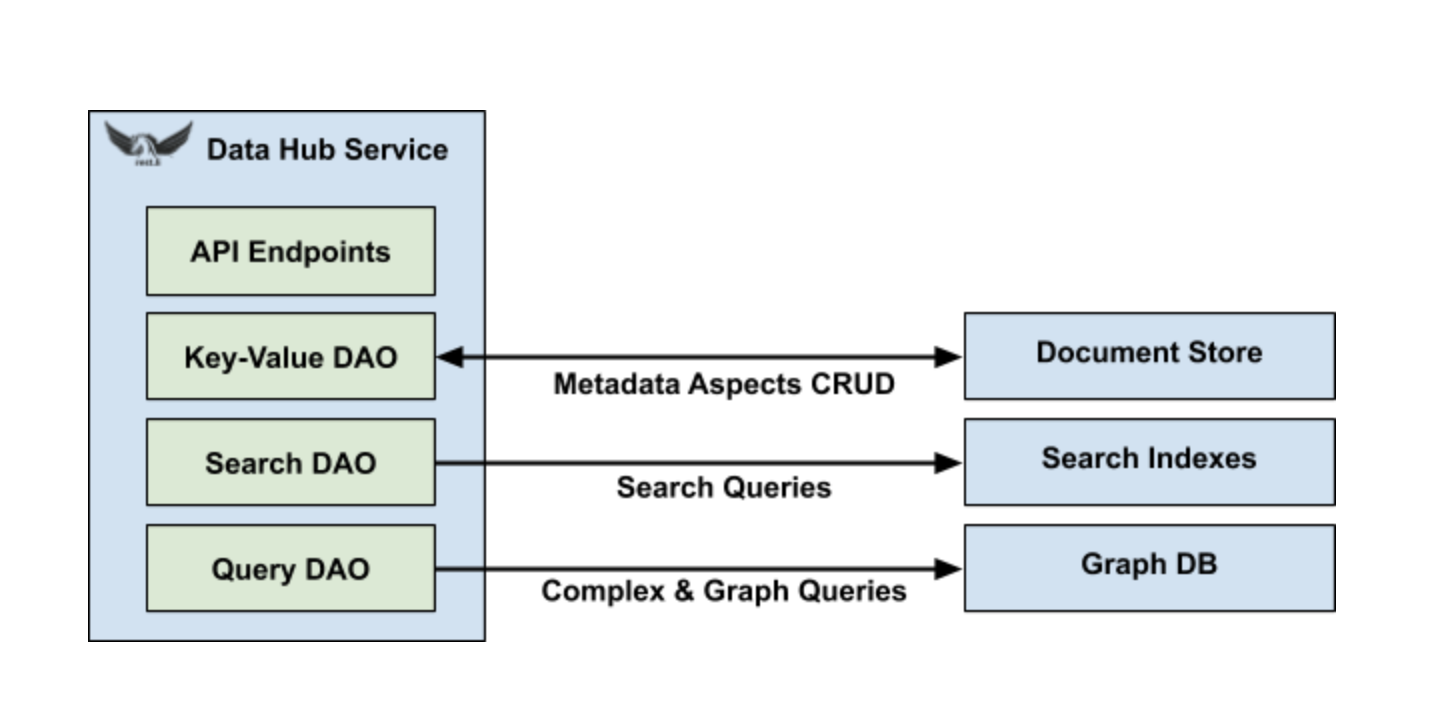
为实现这一目标,Data Hub需要使用多种数据系统,每种数据系统都专门用于扩展和提供有限类型的查询。例如,Espresso是LinkedIn的NoSQL数据库,特别适合大规模面向文档的CRUD。同样,Galene可以轻松索引和提供网络规模的全文搜索。当谈到非平凡的图形查询时,specialized graph DB可以比RDBMS更好地执行数量级,这并不奇怪。然而,事实证明,图结构也是表示外键关系的自然方式,能有效地回答复杂的连接查询。
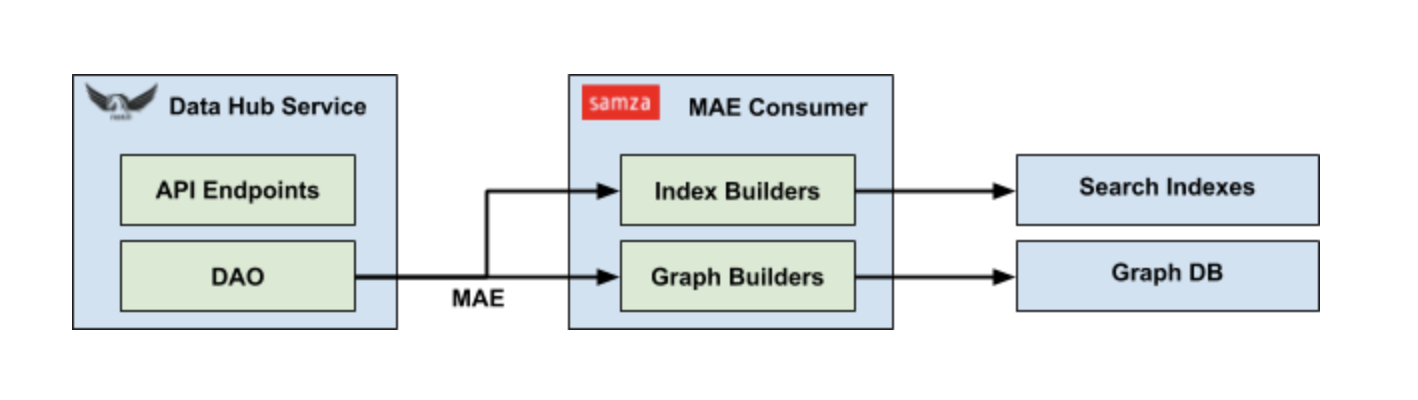
Data Hub通过一组通用数据访问对象(DAO)进一步抽象底层数据系统,例如键值DAO,查询DAO和搜索DAO。进而,当修改DAO的实现时,无需再更改Data Hub中的任何业务逻辑。这将使我们能够在充分利用LinkedIn专有存储技术的同时,能够为流行的开源系统提供参考实现的开源Data Hub。
DAO抽象的另一个主要好处是标准化的变更数据捕获(CDC)。无论底层数据存储系统的类型如何,通过键值DAO的任何更新操作都将自动发出元数据审计事件(MAE)。每个MAE包含相应实体的URN,以及特定元数据方面的前后图像。这支持lambda架构,其中可以批量或流处理MAE。与MCE类似,MAE的模式也是由元数据模型自动生成的。
元数据索引
最后一个缺失的部分是元数据索引管道。该系统将元数据模型连接在一起,并在图形数据库和搜索引擎中创建相应索引,以促进有效查询。这些业务逻辑以索引构建器和图形构建器的形式捕获,并作为处理MAE的Samza作业的一部分执行。每个构建器都在作业中注册了它们对特定元数据方面的兴趣,并将使用相应的MAE进行调用。然后,构建器会返回到一个幂等更新列表,这些更新将应用于搜索索引或graph DB。
元数据索引管道也是高度可扩展的,因为它可以基于每个MAE的实体URN进行分区,以支持每个实体的有序处理。
五、结论和期待
在这篇文章中,我们介绍了Data Hub,这是我们在LinkedIn元数据之旅中的最新进展。该项目包括模块化UI前端和通用元数据架构后端。
过去六个月,Data Hub在LinkedIn每周支持1500多员工的搜索和各种特定的操作工作。LinkedIn的元数据图包含超过一百万个数据集,23个数据存储系统,25k个指标,500多个AI功能,最重要的是所有LinkedIn员工都是该图的创建者,消费者和操作者。
我们通过向产品添加更多有趣的用户故事和相关性算法来继续改进Data Hub。我们还计划为GraphQL添加原生支持,并利用Pegasus领域特定的语言(PDL)在不久的将来自动生成代码。与此同时,我们正积极与开源社区分享WhereHows的演变,并将在Data Hub公开发布后发表声明。
文章来源:Linkedin Engineering , 《Data Hub: A Generalized Metadata Search & Discovery Tool》作者 / Mars Lan, Seyi Adebajo, Shirshanka Das
DataPipeline丨LinkedIn元数据之旅的最新进展—Data Hub的更多相关文章
- DataPipeline丨DataOps的组织架构与挑战
作者:DataPipeline CEO 陈诚 前两周,我们分别探讨了“数据的资产负债表与现状”及“DataOps理念与设计原则”.接下来,本文会在前两篇文章的基础上继续探讨由DataOps设计原则衍生 ...
- SQL on Hadoop系统的最新进展(1)
转自:http://blog.jobbole.com/47892/ 为什么非要把SQL放到Hadoop上? SQL易于使用.那为什么非得基于Hadoop呢?the robust and scalabl ...
- 国浩:Cassandra在360的最新进展
大家好,我是来自奇虎360的国浩.今天我给大家带来的是Cassandra在360的最新进展. 我会从四个方面来介绍Cassandra在360的应用情况:Cassandra在360的使用历史再结合两个案 ...
- paper 91:边缘检测近期最新进展的讨论
VALSE QQ群对边缘检测近期最新进展的讨论,内容整理如下: 1)推荐一篇deep learning的文章,该文章大幅度提高了edge detection的精度,在bsds上,将edge detec ...
- paper 90:人脸检测研究2015最新进展
搜集整理了2004~2015性能最好的人脸检测的部分资料,欢迎交流和补充相关资料. 1:人脸检测性能 1.1 人脸检测测评 目前有两个比较大的人脸测评网站: 1:Face Detection Data ...
- Graph 卷积神经网络:概述、样例及最新进展
http://www.52ml.net/20031.html [新智元导读]Graph Convolutional Network(GCN)是直接作用于图的卷积神经网络,GCN 允许对结构化数据进行端 ...
- R-Tree空间索引算法的研究历程和最新进展分析
转自原文 R-Tree空间索引算法的研究历程和最新进展分析,2008 摘要:本文介绍了空间索引的概念.R-Tree数据结构和R-Tree空间索引的算法描述,并从R-Tree索引技术的优缺点对R-Tre ...
- 官宣 MAUI 在.NET Preview 3的最新进展
我们在.NET 6 Preview 3中交付了.NET多平台应用UI的移动和桌面开发的最新进展.此版本添加了Windows平台和WinUI 3,改进了基本应用程序和启动构建器,添加了原生生命周期事件, ...
- DataPipeline丨金融行业如何统一管理单个任务下所有API的同步情况
目前,依靠"手工人力"的电子表格数据治理模式逐渐被"自动智能"的专业工具取代.数据管理员.业务分析师开始采用"平台工具"来梳理主数据.元数据 ...
随机推荐
- IComparable和IComparer接口
C#中,自定义类型,支持比较和排序,需要实现IComparable接口.IComparable接口存在一个名为CompareTo()的方法,接收类型为object的参数表示被比较对象,返回整型值:1表 ...
- Anaconda3(0)环境基本使用
https://blog.csdn.net/u012005313/article/details/82347817 主要内容: 查看环境列表 创建新的 Python 环境 激活/停止 Python 环 ...
- 9.consul获取服务实例,调用测试
package main import ( "context" "fmt" "github.com/go-kit/kit/endpoint" ...
- Spring Boot 知识笔记(servlet、监听器、拦截器)
一.通过注解自定义servlet package net.Eleven.demo.servlet; import javax.servlet.ServletException; import java ...
- Ubuntu下安装配置SQLSERVER2017
摘要自微软官网: https://docs.microsoft.com/zh-cn/sql/linux/quickstart-install-connect-ubuntu 安装步骤: 1. 导入公共秘 ...
- LOAM笔记
CSDN有篇结合paper分析代码的博文,下面是我对paper的理解: 1. 综述 整个LOAM本质就是一个激光里程计,没有闭环检测,也就没有图优化框架在里面,该算法把SLAM问题分为两个算法同时运行 ...
- python 之类的继承
#类的继承 class As1(): def As2(self): print("he11...") class As2(As1): def As2(self): print(&q ...
- Spring Security教程(四)
在前面三个博客的例子中,登陆页面都是用的Spring Security自己提供的,这明显不符合实际开发场景,同时也没有退出和注销按钮,因此在每次测试的时候都要通过关闭浏览器来注销达到清除session ...
- scala eval
package com.jason case class JJ(d: Double*) object Ss { def main(args: Array[String]): Unit = { impo ...
- [转帖]Java Netty简介
Java Netty简介 https://www.cnblogs.com/ghj1976/p/3779820.html Posted on 2014-06-10 13:41 蝈蝈俊 阅读(2992) ...