Hadoop基础--统计商家id的标签数案例分析
Hadoop基础--统计商家id的标签数案例分析
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.项目需求
将“temptags.txt”中的数据进行分析,统计出商家id的评论标签数量,由于博客园无法上传大文件的文本,因此我把该文本的内容放在博客园的另一个链接了(需要的戳我),如果网页打不开的话也就可以去百度云盘里下载副本,链接:https://pan.baidu.com/s/1daRiwOVe6ohn42fTv6ysJg 密码:h6er。
实现效果如下:
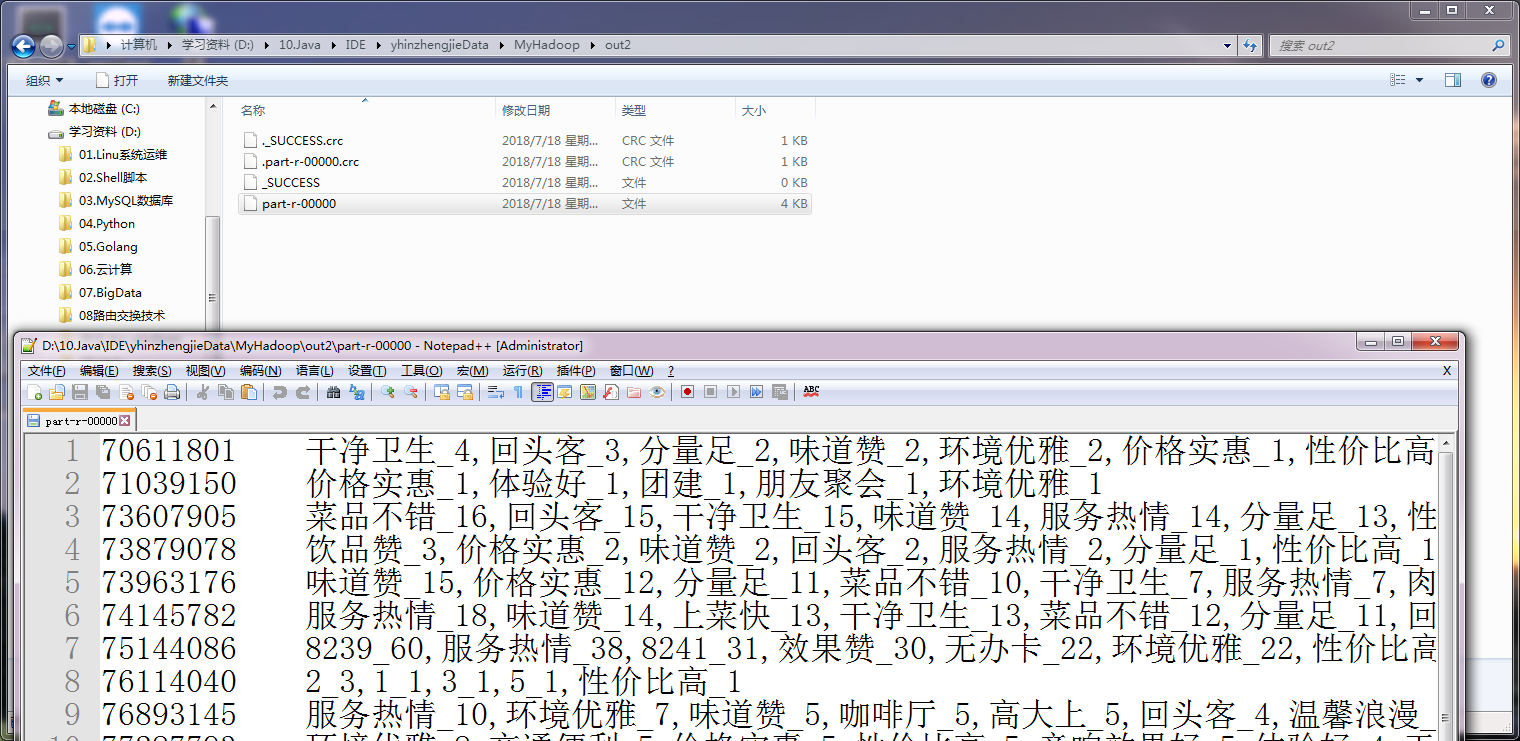
二.代码实现
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.taggen; import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject; import java.util.ArrayList;
import java.util.List; public class Util {
public static List<String> taggen(String comment){
//解析传进来的字符串
JSONObject jo = JSON.parseObject(comment);
//拿到包含商家评论的相关的标签
JSONArray jArray = jo.getJSONArray("extInfoList");
//过滤掉不含商家评论的标签
if(jArray != null && jArray.size() != 0){
//定义一个空的有序集合
List<String> list = new ArrayList<String>();
//通过jArray得到第一个json串,作为json对象
JSONObject jo2 = jArray.getJSONObject(0);
//进一步拿到商家评论的相关的标签
JSONArray jArray2 = jo2.getJSONArray("values");
//进一步过滤掉不含商家评论的标签
if(jArray2 != null && jArray2.size() != 0){
for (Object obj : jArray2) {
//将商检评论的标签添加到我们定义的集合中
list.add(obj.toString());
}
return list;
}
}
return null;
}
}
Util.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.taggen; import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; public class TagBean implements WritableComparable<TagBean> {
private String tag;
private int count; /**
* compareTo() 方法用于将 Number 对象与方法的参数进行比较。可用于比较 Byte, Long, Integer等。
* 该方法用于两个相同数据类型的比较,两个不同类型的数据不能用此方法来比较。
*/
public int compareTo(TagBean o) {
if(o.count == this.count){
return this.getTag().compareTo(o.getTag());
}
return o.count - this.count;
} public void write(DataOutput out) throws IOException {
out.writeUTF(tag);
out.writeInt(count);
}
public void readFields(DataInput in) throws IOException {
tag = in.readUTF();
count = in.readInt();
}
public String getTag() {
return tag;
}
public void setTag(String tag) {
this.tag = tag;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
}
TagBean.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.taggen; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
import java.util.List; public class TaggenMapper extends Mapper<LongWritable,Text,Text,IntWritable> { /**
*
* @param key //这是读取行的偏移量
* @param value //这是这是的数据,每条数据格式都类似,比如:70611801 {"reviewPics":null,"extInfoList":null,"expenseList":null,"reviewIndexes":[1,2],"scoreList":[{"score":4,"title":"环境","desc":""},{"score":5,"title":"服务","desc":""},{"score":4,"title":"口味","desc":""}]}
* @param context
*/
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split("\t");
String id = arr[0];
String json = arr[1];
//我们对数据进行解析,把用户评论的标签数都整合起来,用tags变量来接受数据
List<String> tags = Util.taggen(json);
//如果tags没数据,则不写入
if(tags != null && tags.size() != 0){
for(String tag : tags){
//给数据打标签,最终结果类似于 : 70611801_价格实惠
String compKey = id+ "_"+ tag;
context.write(new Text(compKey), new IntWritable(1));
}
}
}
}
TaggenMapper.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.taggen; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class TaggenReducer extends Reducer<Text, IntWritable , Text, IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
Integer sum = 0;
for(IntWritable value : values){
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
TaggenReducer.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.taggen; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class TaggenMapper2 extends Mapper<Text,Text, Text,Text> { //89223651_价格实惠 8
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { //此时的key其实就是上一个MapReduce的结果,比如:70611801_价格实惠
String compkey = key.toString();
//我们将结果进行拆分,取出来id,比如 : 70611801
String id = compkey.split("_")[0];
//我们将结果进行拆分,取出来tag,比如 : 价格实惠
String tag = compkey.split("_")[1];
//此时的value的值其实就是对key的一个计数 : 比如key出现的次数为8
String sum = value.toString();
//这个时候我们就是将tag和之前的value进行拼接,得出结果如下 : 价格实惠_8
String newVal = tag + "_" + sum;
//最后将我们重写组合的key和value重新分发给reduce
context.write(new Text(id), new Text(newVal));
}
}
TaggenMapper2.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.taggen; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException;
import java.util.TreeSet; public class TaggenReducer2 extends Reducer<Text,Text,Text,Text> { protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//使用TreeSet的目的是实现去重并排序
TreeSet<TagBean> ts = new TreeSet<TagBean>();
//迭代value,并将其放入treeSet,而TreeSet使用的排序是自定义(TagBean)的。
for(Text value:values){
String[] arr = value.toString().split("_");
String tag = arr[0];
int count = Integer.parseInt(arr[1]);
TagBean tagBean = new TagBean();
tagBean.setTag(tag);
tagBean.setCount(count);
ts.add(tagBean);
}
//迭代TreeSet中的TagBean,并得到tag和count,放进StringBuffer
StringBuffer sb = new StringBuffer();
for (TagBean tb : ts) {
String tag = tb.getTag();
int count = tb.getCount();
String val = tag+"_"+count;
sb.append(val+ ",");
}
String newVal = sb.toString().substring(0, sb.length() -1);
//经过上面的整理,可以把同一个商家id的所有标签整个到一起,最终发送出去FileOutputFormat,最终格式为类型如 : 83084036 价格实惠_1,干净卫生_1
context.write(key,new Text(newVal));
//TreeSet置空
ts.clear();
//StringBuffer置空
sb.setLength(0);
}
}
TaggenReducer2.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.taggen; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TaggenApp { public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","file:///");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJobName("taggen");
job.setJarByClass(TaggenApp.class);
job.setMapperClass(TaggenMapper.class);
job.setReducerClass(TaggenReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\out");
if(fs.exists(outPath)){
fs.delete(outPath,true);
}
FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\temptags.txt"));
FileOutputFormat.setOutputPath(job,outPath);
if(job.waitForCompletion(true)){
Job job2 = Job.getInstance(conf);
job2.setJobName("taggen2");
job2.setJarByClass(TaggenApp.class);
job2.setMapperClass(TaggenMapper2.class);
job2.setReducerClass(TaggenReducer2.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(Text.class);
job2.setInputFormatClass(KeyValueTextInputFormat.class);
Path outPath2 = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\out2");
if(fs.exists(outPath2)){
fs.delete(outPath2,true);
}
FileInputFormat.addInputPath(job2,outPath);
FileOutputFormat.setOutputPath(job2,outPath2);
job2.waitForCompletion(true);
}
}
}
Hadoop基础--统计商家id的标签数案例分析的更多相关文章
- Scala进阶之路-统计商家id的标签数以及TopN示例案例分析
Scala进阶之路-统计商家id的标签数以及TopN示例案例分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.项目需求 将“temptags.txt”中的数据进行分析,统计出 ...
- Hadoop基础-Map端链式编程之MapReduce统计TopN示例
Hadoop基础-Map端链式编程之MapReduce统计TopN示例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.项目需求 对“temp.txt”中的数据进行分析,统计出各 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例)
Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编辑配置文件(pml.xml)(我 ...
- Hadoop基础原理
Hadoop基础原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 业内有这么一句话说:云计算可能改变了整个传统IT产业的基础架构,而大数据处理,尤其像Hadoop组件这样的技术出 ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
随机推荐
- HTML基础之DOM操作
DOM(Document Object Model 文档对象模型) 一个web页面的展示,是由html标签组合成的一个页面,dom对象实际就是将html标签转换成了一个文档对象.可以通过dom对象中j ...
- libgdx学习记录13——矩形CD进度条绘制
利用ShapeRenderer可进行矩形进度条的绘制,多变形的填充等操作. 这是根据角度获取矩形坐标的函数. public Vector2 GetPoint( float x, float y, fl ...
- Partition2:对现有表分区
在SQL Server中,普通表可以转化为分区表,而分区表不能转化为普通表,普通表转化成分区表的过程是不可逆的,将普通表转化为分区表的方法是: 在分区架构(Partition Scheme)上创建聚集 ...
- 记录:Ubuntu 18.04 安装 tensorflow-gpu 版本
狠下心来重新装了系统,探索一下 gpu 版本的安装.比较令人可喜的是,跟着前辈们的经验,还是让我给安装成功了.由于我是新装的系统,就像婴儿般纯净,所以进入系统的第一步就是安装 cuda,只要这个不出错 ...
- python + selenium webdriver 自动化测试 之 环境异常处理 (持续更新)
1.webdriver版本与浏览器版本不匹配,在执行的时候会抛出如下错误提示 selenium.common.exceptions.WebDriverException: Message: unkno ...
- Unity导入模型出现 (Avatar Rig Configuration mis-match. Bone length in configuration does not match position in animation)?
昨天遇到这两个模型导入的问题,查了一下资料,自己摸索了一下解决方法..总结一下~ 出现的原因:(问题1)Warning 当模型文件导入以后并且设置Animation Type是Generic的时候,动 ...
- Vigenere加密
Vigenere加密法原理很简单,实现起来也不难.与普通的单码加密法不同,明文经过加密之后,每个字母出现的频率就不会有高峰和低峰. 密钥中字母代表行和明文中的字母代表行.在vigenere表中找到对应 ...
- 了不起的Node.js--之三
开发工具: 我使用的开发工具是Mac版的WebStorm,这个工具支持Nodejs,只要按照如下步骤设置即可以支持 1.WebStorm的开发界面,这个开发工具还是非常好用的. 2.WebStorm的 ...
- 2-Fourteenth Scrum Meeting-20151214
任务安排 成员 今日完成 明日任务 闫昊 用本地数据库记录课程结构和学习进度 修复bug 唐彬 请假(编译……) 编写与服务器交互的代码 史烨轩 请假(编译……) 获取视频url 余帆 请假( ...
- 炸弹人的Alpha版使用说明
本游戏是一款手机游戏,学生可以在无聊时打发时间,放松心情.现在只有三关,但游戏运行还算可以. 注意事项: 目前游戏还有一些不好的地方,游戏无法暂停,如果游戏任务死亡,则无法重开. 游戏后面的关卡还需要 ...