22.天眼查cookie模拟登陆采集数据
通过账号登录获取cookies,模拟登录(前提有天眼查账号),会员账号可查看5000家,普通只是100家,同时也要设置一定的反爬措施以防账号被封。
拿有权限的账号去获取cookies,去访问页面信息,不过这样呢感觉还是不合适,因为之前也采集过都是避开登录和验证码的问题,因为这些数据只是人家网站让不让你拿,该怎样去拿的问题。
这里只是简单地做一下测试,实际采集会遇到各种问题的,这里只是个解题思路仅供参考。
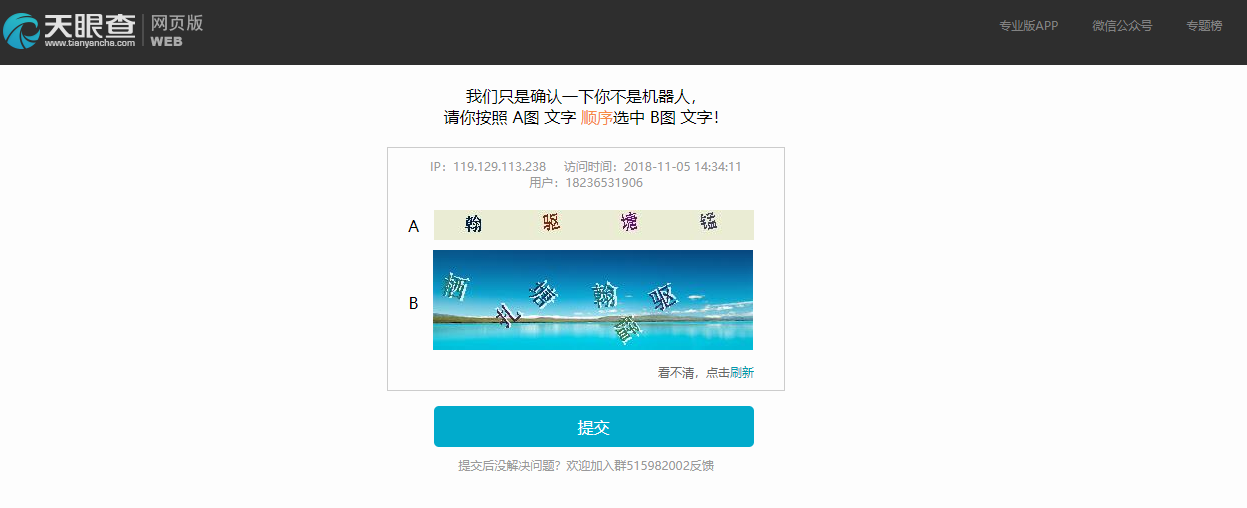
不然会被检测如图:
# coding:utf-8 import requests
from lxml import etree
import re
#请求地址
target_url ='https://www.tianyancha.com/search?key=' headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'TYCID=b9583550959d11e897e06dcb73cfa6e2; undefined=b9583550959d11e897e06dcb73cfa6e2; _ga=GA1.2.442696904.1533136553; ssuid=9383237588; aliyungf_tc=AQAAAI5OlAkhwQcA7nGBd5KVOLSC9NYt; csrfToken=-56Od6hSl_S1CmBVCzLLBYEI; _gid=GA1.2.928876903.1541388137; _gat_gtag_UA_123487620_1=1; Hm_lvt_e92c8d65d92d534b0fc290df538b4758=1541393330,1541393799,1541394021,1541394112; Hm_lpvt_e92c8d65d92d534b0fc290df538b4758=1541394115; tyc-user-info=%257B%2522myQuestionCount%2522%253A%25220%2522%252C%2522integrity%2522%253A%25220%2525%2522%252C%2522state%2522%253A%25220%2522%252C%2522vipManager%2522%253A%25220%2522%252C%2522onum%2522%253A%25220%2522%252C%2522monitorUnreadCount%2522%253A%25226%2522%252C%2522discussCommendCount%2522%253A%25220%2522%252C%2522token%2522%253A%2522eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiIxODIzNjUzMTkwNiIsImlhdCI6MTU0MTM5NDEzMSwiZXhwIjoxNTU2OTQ2MTMxfQ.biIMiqd7l2LBwARywkoJ4J-dFh7zT-SSzz0V-GKc9r4EENomkv-1SA68RvVn0sZUzN_3wHbrw-Sl0ksedBgNGA%2522%252C%2522redPoint%2522%253A%25220%2522%252C%2522pleaseAnswerCount%2522%253A%25220%2522%252C%2522vnum%2522%253A%25220%2522%252C%2522bizCardUnread%2522%253A%25220%2522%252C%2522mobile%2522%253A%252218236531906%2522%257D; auth_token=eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiIxODIzNjUzMTkwNiIsImlhdCI6MTU0MTM5NDEzMSwiZXhwIjoxNTU2OTQ2MTMxfQ.biIMiqd7l2LBwARywkoJ4J-dFh7zT-SSzz0V-GKc9r4EENomkv-1SA68RvVn0sZUzN_3wHbrw-Sl0ksedBgNGA',
'Host': 'www.tianyancha.com',
'Referer': 'https://www.tianyancha.com/',
'Upgrade-Insecure-Requests': '',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36',
}
#搜索关键字
list=['佛山']
for j in range(6):
for i in list:
form_data={
'key': '{}'.format(i),
}
url = 'https://www.tianyancha.com/search/p{}?key={}'.format(j,i)
# 发送post请求,翻译数据
response = requests.get(url, data=form_data, headers=headers)
# print(response.text)
html = etree.HTML(response.text)
#获取当前搜索界面url
link_urls = html.xpath("//div[@class='content']/div[@class='header']/a/@href")
for link_url in link_urls:
# print(link_url)
response = requests.get(link_url, headers=headers)
# print(response.text)
html2 = etree.HTML(response.text)
#公司名称
company = html2.xpath("//h1[@class='name']").extract_first()
print(company)
print('*'*100)
# coding:utf-8 import requests
from lxml import etree
import re
#请求地址
target_url ='https://www.tianyancha.com/search?key=' headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'TYCID=b9583550959d11e897e06dcb73cfa6e2; undefined=b9583550959d11e897e06dcb73cfa6e2; _ga=GA1.2.442696904.1533136553; ssuid=9383237588; aliyungf_tc=AQAAAI5OlAkhwQcA7nGBd5KVOLSC9NYt; csrfToken=-56Od6hSl_S1CmBVCzLLBYEI; _gid=GA1.2.928876903.1541388137; _gat_gtag_UA_123487620_1=1; Hm_lvt_e92c8d65d92d534b0fc290df538b4758=1541393330,1541393799,1541394021,1541394112; Hm_lpvt_e92c8d65d92d534b0fc290df538b4758=1541394115; tyc-user-info=%257B%2522myQuestionCount%2522%253A%25220%2522%252C%2522integrity%2522%253A%25220%2525%2522%252C%2522state%2522%253A%25220%2522%252C%2522vipManager%2522%253A%25220%2522%252C%2522onum%2522%253A%25220%2522%252C%2522monitorUnreadCount%2522%253A%25226%2522%252C%2522discussCommendCount%2522%253A%25220%2522%252C%2522token%2522%253A%2522eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiIxODIzNjUzMTkwNiIsImlhdCI6MTU0MTM5NDEzMSwiZXhwIjoxNTU2OTQ2MTMxfQ.biIMiqd7l2LBwARywkoJ4J-dFh7zT-SSzz0V-GKc9r4EENomkv-1SA68RvVn0sZUzN_3wHbrw-Sl0ksedBgNGA%2522%252C%2522redPoint%2522%253A%25220%2522%252C%2522pleaseAnswerCount%2522%253A%25220%2522%252C%2522vnum%2522%253A%25220%2522%252C%2522bizCardUnread%2522%253A%25220%2522%252C%2522mobile%2522%253A%252218236531906%2522%257D; auth_token=eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiIxODIzNjUzMTkwNiIsImlhdCI6MTU0MTM5NDEzMSwiZXhwIjoxNTU2OTQ2MTMxfQ.biIMiqd7l2LBwARywkoJ4J-dFh7zT-SSzz0V-GKc9r4EENomkv-1SA68RvVn0sZUzN_3wHbrw-Sl0ksedBgNGA',
'Host': 'www.tianyancha.com',
'Referer': 'https://www.tianyancha.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36',
}
#搜索关键字
list=['佛山']
for j in range():
for i in list:
form_data={
'key': '{}'.format(i),
}
url = 'https://www.tianyancha.com/search/p{}?key={}'.format(j,i)
# 发送post请求,翻译数据
response = requests.get(url, data=form_data, headers=headers)
# print(response.text)
html = etree.HTML(response.text)
#获取当前搜索界面url
link_urls = html.xpath("//div[@class='content']/div[@class='header']/a/@href")
for link_url in link_urls:
# print(link_url)
response = requests.get(link_url, headers=headers)
# print(response.text)
html2 = etree.HTML(response.text)
#公司名称
company = html2.xpath("//h1[@class='name']").extract_first()
print(company)
print('*'*)
22.天眼查cookie模拟登陆采集数据的更多相关文章
- 使用ApiPost测试接口时需要先登录怎么办?利用Cookie模拟登陆!
ApiPost简介: ApiPost是一个支持团队协作,并可直接生成文档的API调试.管理工具.它支持模拟POST.GET.PUT等常见请求,是后台接口开发者或前端.接口测试人员不可多得的工具 . 下 ...
- selenium3.7+ python3 添加cookie模拟登陆
一.背景介绍 最近做一个爬虫项目,用selenium调用浏览器去获取渲染后的源码,但是每次登陆都需要手机验证,这真的是头痛啊,这种验证方式不要想着去破解,还是老老实实用手机收验证码去吧!反正我是不知道 ...
- 爬虫——cookie模拟登陆
cookie适用于抓取需要登录才能访问的页面网站 cookie和session机制 http协议为无连接协议,cookie: 存放在客户端浏览器,session: 存放在Web服务器 人人网登录案例 ...
- python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下 ...
- 20170717_python爬虫之requests+cookie模拟登陆
在成功登陆之前,失败了十几次.完全找不到是什么原因导致被网站判断cookie是无效的. 直到用了firefox的httpfox之后才发现cookie里还有一个ASP.NET_SessionId 这个字 ...
- 三种urllib实现网页下载,含cookie模拟登陆
coding=UTF-8 import re import urllib.request, http.cookiejar, urllib.parse # # print('-------------- ...
- python 用cookie模拟登陆网站
import re import requests def get_info(url): headers = { "Cookie" :"***************** ...
- php使用CURL进行模拟登录采集数据
<?php $cookie_path = './'; //设置cookie保存路径 //-----登录要提交的表单数据--------------- $vars['username'] = '张 ...
- PHP curl 携带cookie请求抓取源码,模拟登陆。
公司需要采集一批手机号码,有指定网站.但是需要登陆后才能看到客户号码,手动点击复制太慢,如此就写了以下模拟登陆采集号码程序,分享给大家参考参考. function request_url_data($ ...
随机推荐
- Pandas的使用(1)
Pandas的使用(1) 1.绘图 import pandas as pd import numpy as np import matplotlib.pyplot as plt ts = pd.Ser ...
- Linux学习 LVM ***
一.前言 LVM,逻辑卷管理工具,它的作用是提供一种灵活的磁盘管理办法.通常我们的某个分区用完了,想要扩容,很麻烦.但是用lvm就可以很方便的扩容,收缩. 看它的原理图: 它的原理大致是:首先将磁盘做 ...
- oracle--合并行数据(拼接字符串),获取查询数据的前3条数据...
--标准函数Lpad 可以实现左补零,但是如果多于需要长度,则会截断字符串 SELECT LPAD ('1' , 3 , '0') FROM DUAL -- return 001 情况一:需要补零. ...
- Mysql 性能优化7【重要】sql语句的优化 浅谈MySQL中优化sql语句查询常用的30种方法(转)
原文链接 http://www.jb51.net/article/39221.htm 这篇文章大家都在转载,估计写的有条理吧,本人稍微做一下补充 1.对查询进行优化,应尽量避免全表扫描,首先应考虑 ...
- ThinkPHP 3.1.2 CURD特性 -3
一.ThinkPHP 3 的CURD介绍 (了解) 二.ThinkPHP 3 读取数据 (重点) 对数据的读取 Read $m=new Model('User'); $m=M('User'); ...
- java线程大全一讲通
Java线程:概念与原理 一.操作系统中线程和进程的概念 现在的操作系统是多任务操作系统.多线程是实现多任务的一种方式. 进程是指一个内存中运行的应用程序,每个进程都有自己独立的一块内存空间,一个进程 ...
- 简单说throw和throws的区别
1. 区别 throws是用来声明一个方法可能抛出的所有异常信息,throws是将异常声明但是不处理,而是将异常往上传,谁调用我就交给谁处理.而throw则是指抛出的一个具体的异常类型. 2.分别介绍 ...
- VirtualBox中挂载物理磁盘
注1. 详细内容请参考VirtualBox帮助文件. 注2. 需对dos命令有一定了解. 注3. 以下命令均需以管理员身份执行,VirtualBox也需以管理员身份运行. 主要应用host上的vbox ...
- ALGO-152_蓝桥杯_算法训练_8-2求完数
记: 掌握完数的概念 AC代码: #include <stdio.h> int main(void) { int i,j,sum; ; i <= ; i ++) { sum = ; ...
- 记录一次OOM分析过程
工具: jstat jmap jhat 1.jstat查看gc情况 S0C.S1C.S0U.S1U:Survivor 0/1区容量(Capacity)和使用量(Used) EC.EU:Eden区容量和 ...