MySQL JOIN原理
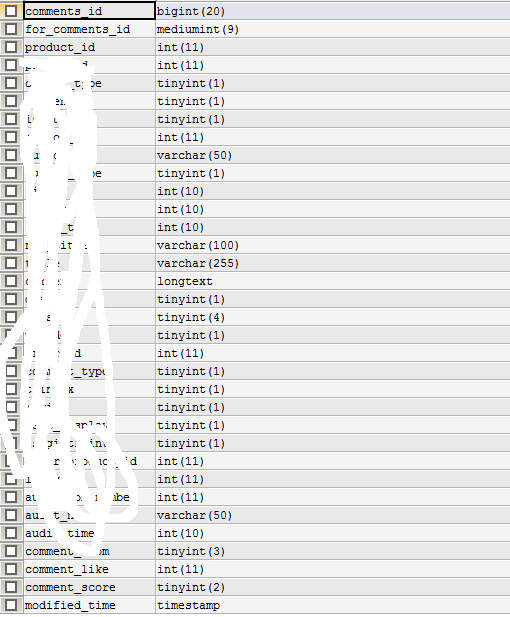
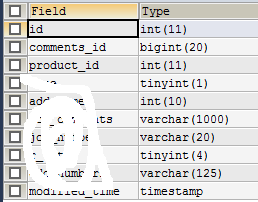
先看一下实验的两张表:
EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;

SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id
WHERE gc.comments_id =

EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.order_id=gcf.product_id

EXPLAIN SELECT * FROM comments gc
LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id

EXPLAIN SELECT * FROM comments_for gcf
LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id
WHERE gcf.comments_id =
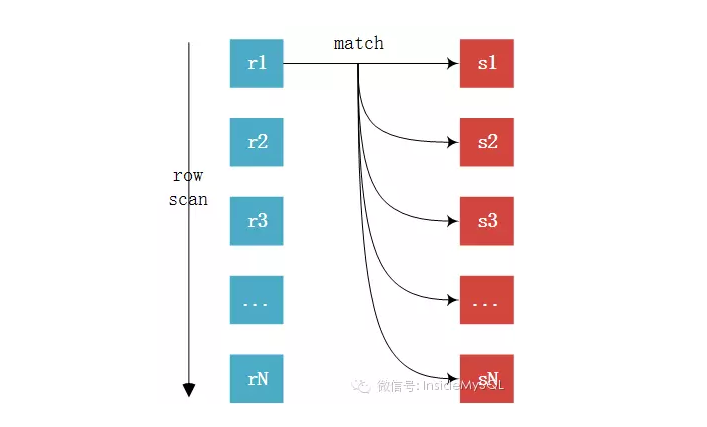
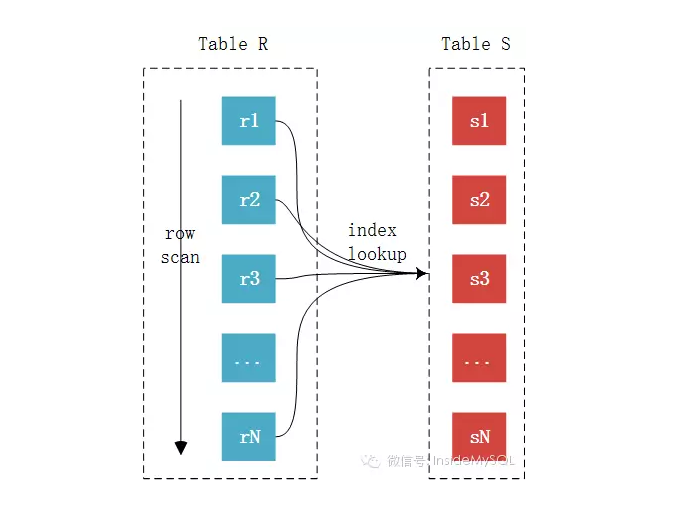
 此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。MySQL JOIN原理的更多相关文章
- MySQL JOIN原理(转)
先看一下实验的两张表: 表comments,总行数28856 表comments_for,总行数57,comments_id是有索引的,ID列为主键. 以上两张表是我们测试的基础,然后看一下索引,co ...
- 由一个场景分析Mysql的join原理
背景 这几天同事写报表,sql语句如下 select * from `sail_marketing`.`mk_coupon_log` a left join `cp0`.`coupon` c on c ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
- MySQL索引原理及慢查询优化 转载
原文地址: http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- MySQL索引原理及慢查询优化(转)
add by zhj:这是美团点评技术团队的一篇文章,讲的挺不错的. 原文:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰 ...
- 【转载】MySQL索引原理及慢查询优化
原文链接:美团点评技术团队:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型 ...
- MySQL查询原理及其慢查询优化案例分享(转)
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓“好马配好鞍”,如何能够更 好的使用它,已经成为开发工程师的必修课,我们经常会从职 ...
- MySQL索引原理与慢查询优化
索引目的 索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才 ...
随机推荐
- Django_在单独文件中加载Django环境临时调试
创建Django环境后,每次在打印调试都需要基于项目有些麻烦. 如何在项目外的文件中加载项目环境进行便携的调试? 创建一个新的 orm.py import os if __name__ == '__m ...
- 【题解】 bzoj1207: [HNOI2004]打鼹鼠 (动态规划)
bzoj1207,懒得复制,戳我戳我 Solution: 挺傻逼的一个\(dp\),直接推就好了 这题在bzoj上的数据有点问题,题目保证每个时间点不会出现在同一位置两个地鼠,然而他有= =(还浪费我 ...
- web入门之十 JS高级编程基础
学习内容 JavaScript函数 JavaScript类和对象 解析JSON数据 能力目标 深入了解JavaScript函数 熟悉JavaScript面向对象编程 熟练进行JSON数据解析 本章简介 ...
- Spring MVC 向页面传值-Map、Model和ModelMap
原文链接:https://www.cnblogs.com/caoyc/p/5635878.html Spring MVC 向页面传值-Map.Model和ModelMap 除了使用ModelAndVi ...
- 关于ehcache配置中timeToLiveSeconds和timeToIdleSeconds的区别
在使用ehcache框架时,timeToLiveSeconds和timeToIdleSeconds这两个属性容易混淆,今天有空就记录一下,以防之后又忘记了. 首先来说明一下这两个属性分别有什么作用:( ...
- Hadoop生态圈-Azkaban实战之Command类型多job工作流flow
Hadoop生态圈-Azkaban实战之Command类型多job工作流flow 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Azkaban内置的任务类型支持command.ja ...
- python获取指定目录下所有文件名os.walk和os.listdir
python获取指定目录下所有文件名os.walk和os.listdir 觉得有用的话,欢迎一起讨论相互学习~Follow Me os.walk 返回指定路径下所有文件和子文件夹中所有文件列表 其中文 ...
- swift学习笔记3
1.在 Swift 中,枚举类型是一等(first-class)类型.它们采用了很多在传统上只被类(class)所支持的特性,例如计算型属性(computed properties),用于提供枚举值的 ...
- SQL记录-PLSQL-DBMS输出
PL/SQL DBMS输出 DBMS_OUTPUT是一个内置的软件包,能够显示输出显示调试信息,并从PL/ SQL块,子程序,包和触发器发送消息.我们已经使用这个包在我们所有的教程中. 让我们来看 ...
- JVM内存管理---垃圾收集器
说起垃圾收集(Garbage Collection,GC),大部分人都把这项技术当做Java语言的伴生产物.事实上,GC的历史远比Java久远,1960年诞生于MIT的Lisp是第一门真正使用内存动态 ...