web scraper无法解决爬虫问题?通通可以交给python!
今天一位粉丝的需求所涉及的问题值得和大家分享分享~~~
背景问题
是这样的,他看了公号里的关于web scraper的系列文章后,希望用它来爬取一个网站搜索关键词后的文章标题和链接,如下图

按照教程,复制网页地址、写选择器、运行调试,发现无论怎样修改都无法提取到任何的信息。
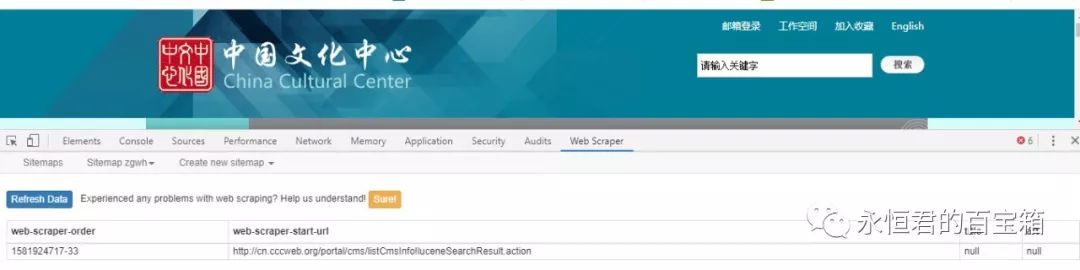
问题分析
这个网站网址是:
http://cn.cccweb.org/portal/cms/listCmsInfo!luceneSearchResult.action
通过观察发现一些特征:
1、无论你点击那一页,这个网址都是一样的。
2、当你把这个网址复制到新的标签页里打开是,发现是空白的内容。

也就意味着这个网址搜索的时候提交的关键词等参数不会在地址栏当中显示,通过burp抓包也证实了我的猜测,是post请求。

那这样的话,web scraper是无法处理、爬取这类网址不变的页面。
那就没法爬了吗?
No!!!这不是还有万能的python啊

问题解决
简单上手的话,就用python+selenium库来搞定好了。。之前也写过文章介绍过:python实现浏览器自动化操作
selenium是一个用来自动化测试的庞大家族。

python中的selenium库可以简单理解为借助计算机来模拟人工的一些操作,借助这个我们可以实现让浏览器模拟我们人类,打开浏览器和网址,搜索关键词,提取并保存数据。
基本用法如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')#打开百度
print(browser.title)#打印标题
browser.quit() #退出
以及
browser.find_element_by_id("searchContents").click()#点击搜索栏
browser.find_element_by_id("searchContents").send_keys("法国")#输入法国
browser.find_element_by_name("submit1").click()#点击搜索
browser.find_element_by_link_text("下一页>>").click()#点击下一页
使用效果如下:

最后保存的数据文件效果如下:

小结一下
1、web scraper爬虫工具小巧简单方便,但是功能有限,遇到像上面这种网址不变的情况,就不适用了。
2、python的selenium库,模拟操作浏览器、鼠标、键盘等爬取数据,简单直观。
3、爬虫入门python最适合不过了。
你可能还会想看:
爬虫系列教程:
python爬虫系列(5)- 看了这篇文章你也可以一键下载网络小说
python爬虫系列(4)- 提取网页数据(正则表达式、bs4、xpath)
python爬虫系列(3)- 网页数据解析(bs4、lxml、Json库)
python爬虫系列(2)- requests库基本使用
python爬虫系列(1)- 概述
python实例:
python帮你定制批量获取你想要的信息
python帮你定制批量获取智联招聘的信息
用python定制网页跟踪神器,有信息更新第一时间通知你(附视频演示)
用python助你一键下载在线小说
教你制作一个微信机器人陪你聊天,只要几行代码
Google图片搜索出了大量满意图片,批量下载它们!
带你看看不一样的微信!
Web Scraper系列教程:
Web Scraper 使用教程(一)- 安装
Web Scraper 使用教程(二)- 基本用法之安装、配置、运行
Web Scraper 使用教程(三)- 基本用法(常用选择器类型)
Web Scraper 使用教程(四)- 进阶用法(同一个页面爬取多个类型内容)
Web Scraper 使用教程(五)- 进阶用法(爬取向下滚动加载页面)
Web Scraper 使用教程(六)- 进阶用法(网址有规律变化进行翻页)
Web Scraper 使用教程(七)- 进阶用法(点击「翻页器」进行翻页)
欢迎交流!
web scraper无法解决爬虫问题?通通可以交给python!的更多相关文章
- web scraper插件爬虫进阶(能满足非技术人员的爬虫需求,建议收藏!!!!)
为了照顾更多的小伙伴,大家的学习能力及了解程度都不同,因此大家可以通过以下目录来有选择性的学习,节约大家的时间. 备注: 一定要实操!!! 一定要实操!!! ...
- 简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用
这是简易数据分析系列的第 15 篇文章. 年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法 ...
- Web Scraper——轻量数据爬取利器
日常学习工作中,我们多多少少都会遇到一些数据爬取的需求,比如说写论文时要收集相关课题下的论文列表,运营活动时收集用户评价,竞品分析时收集友商数据. 当我们着手准备收集数据时,面对低效的复制黏贴工作,一 ...
- 使用 Chrome 浏览器插件 Web Scraper 10分钟轻松实现网页数据的爬取
web scraper 下载:Web-Scraper_v0.2.0.10 使用 Chrome 浏览器插件 Web Scraper 可以轻松实现网页数据的爬取,不写代码,鼠标操作,点哪爬哪,还不用考虑爬 ...
- 简易数据分析 06 | 如何导入别人已经写好的 Web Scraper 爬虫
这是简易数据分析系列的第 6 篇文章. 上两期我们学习了如何通过 Web Scraper 批量抓取豆瓣电影 TOP250 的数据,内容都太干了,今天我们说些轻松的,讲讲 Web Scraper 如何导 ...
- 不写代码也能爬虫Web Scraper
https://www.jianshu.com/p/d0a730464e0c web scraper中文网 http://www.iwebscraper.com/category/%E6%95%99% ...
- web scraper 抓取分页数据和二级页面内容
如果是刚接触 web scraper 的,可以看第一篇文章. web scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据. ...
- Web Scraper 翻页——控制链接批量抓取数据
 这是简易数据分析系列的第 5 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
随机推荐
- 查看包名和Activity的小工具
添加到右键菜单,很方便. 做个记录:请移步原文
- webpack-dev-server 使用 react-router 启用 browserhistory 采坑记
问题的产生 今天下午请假,忙完手头事之后,在家实在无聊,想着从0开始搭建一个 react 的项目.webpack 基本配置之前研究过,没什么大问题.谁想,在 react-router 的配置时出现了个 ...
- OpenStack的Trove组件详解
一:简介 一.背景 1. 对于公有云计算平台来说,只有计算.网络与存储这三大服务往往是不太够的,在目前互联网应用百花齐放的背景下,几乎所有应用都使用到数据库,而数据库承载的往往是应用最核心的数 ...
- Java 获取IP工具类、Vo类整理记录
前言 日常开发中,获取ip是常用的功能,本文记录如何在Java中获取本机外网ip.地理位置,访问用户的外网ip.地理位置,以及指定外网ip的地理位置: 代码编写 1.获取访问用户外网ip,我们从访问者 ...
- MySQL常用控制台指令
MySQL服务的启用与停止 MySQL服务的启用: net start mysql80 MySQL服务的停止: net stop mysql80 MySQL的登入与退出 数据库的登入: mysql - ...
- Jmeter(四) - 从入门到精通 - 创建网络测试计划(详解教程)
1.简介 在本节中,您将学习如何创建基本的 测试计划来测试网站.您将创建五个用户,这些用户将请求发送到JMeter网站上的两个页面.另外,您将告诉用户两次运行测试.因此,请求总数为(5个用户)x(2个 ...
- $工具, 属性, TAB点击切换
$工具方法 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <tit ...
- JAVA中的注释方法
Java的三种注释方法 ①单行注释:使用 // ,其注释内容从//开始到本行结束,比较常用, 快捷键为:Ctrl + / 或者 Ctrl + Shift + C 取消注释:Ctrl + / 或者 ...
- FTP免费工具,FTP免费工具推荐!
IIS7服务器管理工具是FTP操作的客户端软件,能够作为批量操作FTP命令!同时,它还能够作为VNC的操作客户端进行VNC的相关操作!能够连接Windows和Linux的服务器和PC,并进行实时的检测 ...
- IDEA字节码学习查看神器jclasslib bytecode viewer介绍
转载来自:https://blog.csdn.net/w605283073/article/details/103209221 一.背景 很多人想学习Java反汇编后的字节码,但是一方面缺乏好的资料, ...