Learning Combinatorial Embedding Networks for Deep Graph Matching(基于图嵌入的深度图匹配)
1. 文献信息
题目: Learning Combinatorial Embedding Networks for Deep Graph Matching(基于图嵌入的深度图匹配)
作者:上海交通大学研究团队(Runzhong Wang ,Junchi Yan,Xiaokang Yang)
期刊:ICCV 2019
注:此篇论文篇幅较长,其中涉及图匹配等问题,为方便阅读,保留了较多关键信息。
2. 背景
这篇论文聚焦于计算机视觉领域一项历久弥新的问题:图匹配问题。在计算机视觉中,图匹配旨在利用图结构信息,寻找物体之间节点与节点的对应关系。已有的研究工作通常从数学优化的角度求解图匹配的数学形式,而忽视了机器学习、尤其是深度学习在图匹配问题上的巨大潜力。作者提出,基于嵌入(embedding)技术的深度学习方法具有高效建模图结构的能力,它能够降低图匹配求解运算的复杂度,同时整个框架能够进行端到端的训练。
3. 内容
图匹配问题:图匹配是计算机视觉和模式识别领域中一项重要的基础性问题。通常,图匹配问题的结果由一个指派矩阵(assignment matrix)X表示,其中指派矩阵的每行、每列有且仅有一个元素为1。为了同时建模图结构之间的相似度,研究者们引入了同时包含一阶和二阶相似度信息的相似度矩阵(affinity matrix)K。相似度矩阵是一个具有高阶复杂度的矩阵,它的对角线元素包含了节点与节点的相似度信息,非对角线元素包含了边与边的相似度信息。基于相似度矩阵K与指派矩阵X,图匹配问题可以被公式化为Lawler形式的二次指派问题(Lawler’s Quadratic Assignment Problem, Lawler’s QAP):

其中,vec(X)代表对矩阵X进行列向量化。公式(1)中,一个列向量的转置乘矩阵乘列向量,其结果是一个数值。直观地看,公式(1)最大化了图匹配对应关系中的一阶相似度和二阶相似度。在数学上,公式(1)是一个NP-难的二次指派问题。一方面,过去的图匹配研究工作主要聚焦于如何快速、精确地求解公式(1)。在这篇工作中,作者引入了深度嵌入技术,将公式(1)中NP-难的二次指派问题转化为可以精确求解的线性指派问题。另一方面,图匹配面临的问题是如何建模相似度,即如何构建相似度矩阵K。传统的图匹配方法通常采用形如公式(2)的高斯核函数建模边特征fij与fab之间的相似度。
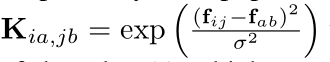
然而,形如上面公式的固定参数形式并不能适应多样化的输入图像,建模得到的相似度信息并不能准确地反映节点之间的匹配关系。因此,在过去的研究工作中,许多基于机器学习的图匹配方法被提出,利用机器学习方法准确地建模图匹配相似度。特别的,CVPR2018的最佳论文提名Deep Learning of Graph Matching首次将深度学习引入图匹配,其中采用了VGG16网络提取特征、谱方法求解图匹配、像素偏移损失函数用于监督训练。在PCA-GM中,作者采用了同样的VGG16网络结构以进行公平的对比,同时采用了Sinkhorn算法替代谱方法,求解匹配问题。
概述:在这篇工作中,通过CNN网络与嵌入网络,作者高效地建模了图像与图结构的相似度信息。作者提出了排列损失函数以替代已有工作中的偏移损失函数,进行端到端的监督训练。通过引入嵌入技术,图匹配求解的复杂度大大降低,原先无法被精确求解的二阶组合优化问题转化为了能够精确求解的一阶问题。在论文中,作者采用了Sinkhorn算法,在精确求解图匹配问题的同时允许梯度回传。这是图嵌入技术被首次用于计算机视觉的图匹配任务中。论文中提出的深度图匹配框架如图 1所示。在实验中,作者提出的PCA-GM算法以15%的相对精度超越了CVPR2018的最佳论文提名Deep Learning of Graph Matching,同时还能够在多个类别之间进行知识迁移。
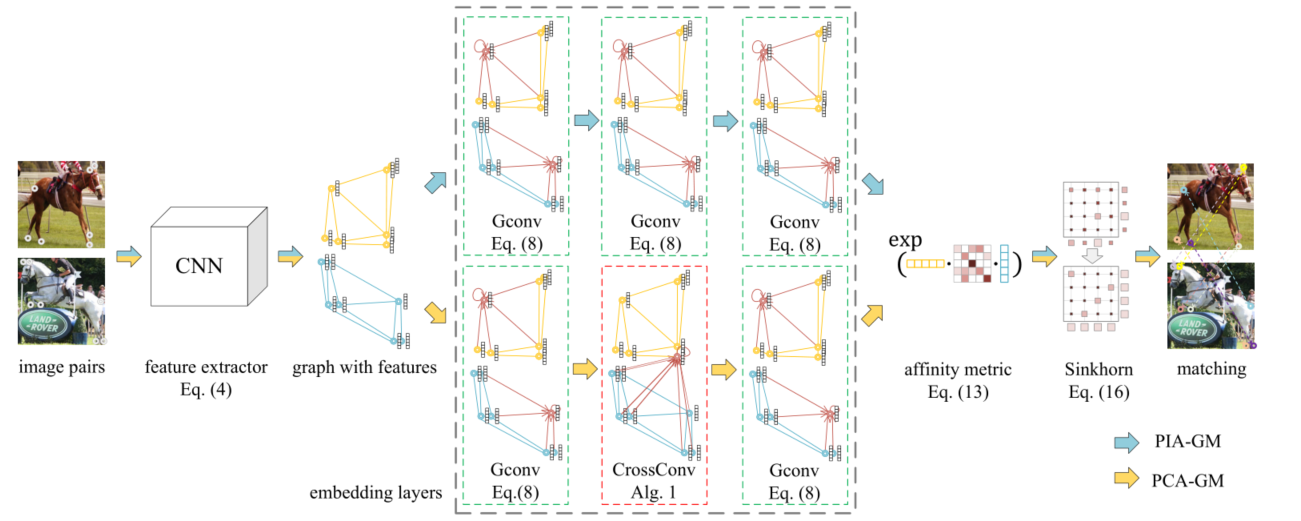
图 1 论文提出的框架概览
图内卷积:如图 1所示,在PCA-GM中,输入一对含有关键点的图片,我们使用CNN网络(VGG16)为每个关键点提取一个特征向量。随后,通过德洛内三角化(Delaunay triangulation),我们建立了一对包含图像特征的图结构。通过图嵌入方法,我们能够在节点的特征向量中嵌入图结构信息。
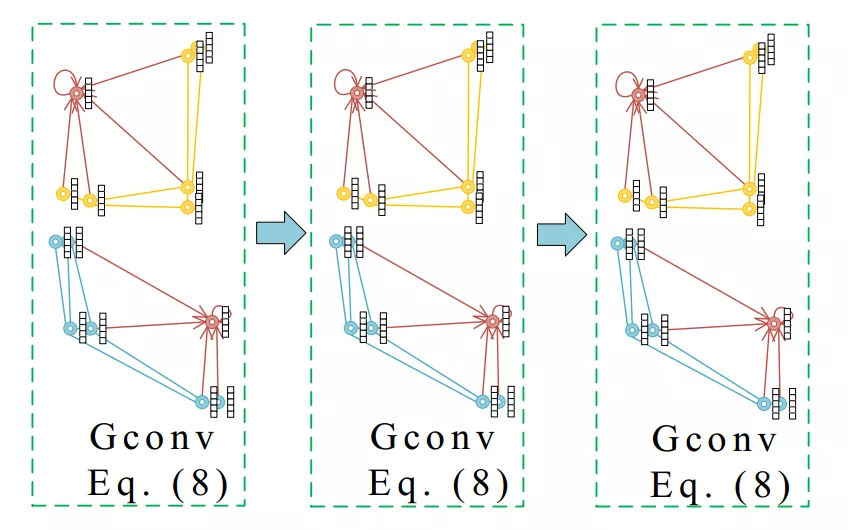
图 2 图内卷积
在模型中,作者采用了图卷积作为图嵌入的方法。作者提出的图内卷积GConv实际上与图卷积网络GCN类似,通过在邻接的节点之间传递特征信息,图内卷积能够在节点的特征向量中嵌入图结构的信息,进而体现图结构的相似度。图内卷积的所有网络参数在所有节点之间共享。基于如图 2所示的图内卷积,作者提出了PIA-GM模型(图 1中蓝色箭头所示)。
跨图卷积:基于图内卷积,作者进一步提出了跨图卷积CrossConv的形式。跨图卷积在两个待匹配的图结构之间传递特征,如图 3所示。
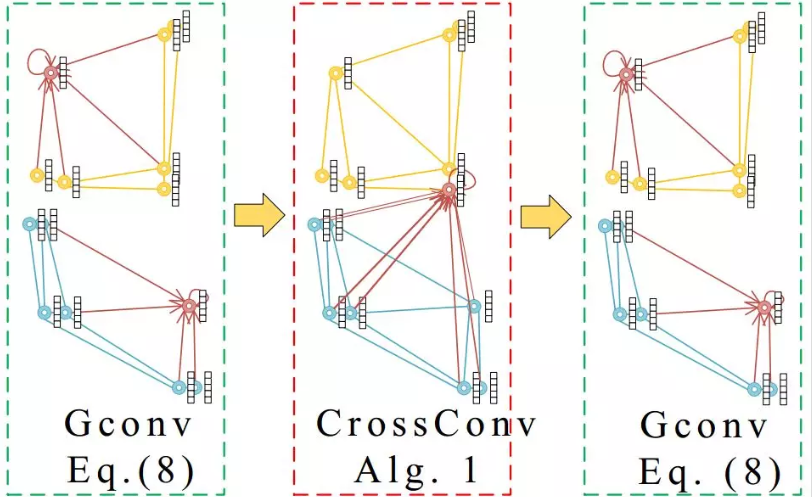
图 3 跨图卷积
在作者提出的跨图卷积算法中,首先输入上一层(k-1层)的特征向量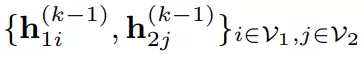 。随后,第二行中,通过计算两图之间任意两个向量的相似度,构造一个的相似度矩阵。第三行对相似度矩阵采用Sinkhorn算法,求解得到一个匹配关系。这是由k-1层网络的特征预测得到的匹配关系。这个预测得到的匹配关系作为两个图结构之间跨图更新的权重,在上一层特征中越相似的点对,在跨图更新时具有越高的传播权重。因此,直观地看,跨图卷积层在匹配过程中同时考虑了两个待匹配图结构的信息,在嵌入层中引入了一一对应的匹配约束;与之对比,单纯的图内卷积只考虑了单个图内部的结构信息,没有考虑节点一一对应的匹配约束。通过跨图卷积更新,两图之间原本较为相似的特征会更加相似。基于如图 3所示的跨图卷积,作者在论文中提出了PCA-GM模型(图 1中黄色箭头所示)。
。随后,第二行中,通过计算两图之间任意两个向量的相似度,构造一个的相似度矩阵。第三行对相似度矩阵采用Sinkhorn算法,求解得到一个匹配关系。这是由k-1层网络的特征预测得到的匹配关系。这个预测得到的匹配关系作为两个图结构之间跨图更新的权重,在上一层特征中越相似的点对,在跨图更新时具有越高的传播权重。因此,直观地看,跨图卷积层在匹配过程中同时考虑了两个待匹配图结构的信息,在嵌入层中引入了一一对应的匹配约束;与之对比,单纯的图内卷积只考虑了单个图内部的结构信息,没有考虑节点一一对应的匹配约束。通过跨图卷积更新,两图之间原本较为相似的特征会更加相似。基于如图 3所示的跨图卷积,作者在论文中提出了PCA-GM模型(图 1中黄色箭头所示)。
匹配求解:在经过图内和跨图卷积层后,图结构中的每个节点都拥有一个同时包含了图像特征以及图结构特征的嵌入特征向量。通过为任意两个嵌入特征计算相似度,我们即可构建一个相似度矩阵M。在衡量相似度时,作者额外引入了相似度权重矩阵A: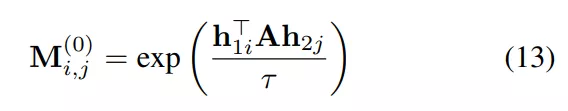
其中τ是调整公式(13)判别能力的超参数,包含了可学习的相似度权重。需要注意的是,由于作者采用了嵌入技术,将图结构特征嵌入到了节点的特征向量中,因此公式(13)得到的相似度矩阵规模是线性的,其复杂度小于公式(1)中的NP-难问题。实际上,由公式(13)组成的图匹配问题可以被公式化为线性指派问题,可以采用如下介绍的Sinkhorn算法在端到端的框架中精确求解。
在计算得到相似度矩阵后,作者采用了Sinkhorn算法,从相似度矩阵求解匹配结果。Sinkhorn算法是一种迭代算法,它通过将输入的矩阵交替进行行归一化以及列归一化,最终收敛得到一个每行、每列加和均为1的双随机矩阵(doubly stochastic matrix)。Sinkhorn算法如公式(14)(15)所示
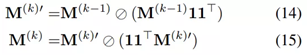
由于Sinkhorn算法只包含了乘、除操作,Sinkhorn算法完全可微,能够被用于端到端的深度学习训练中。论文作者借助了PyTorch 的自动微分技术,高效地实现了Sinkhorn算法及其反向传播。
损失函数:在论文中,作者提出了基于交叉熵的损失函数:排列损失函数(Permutation loss)
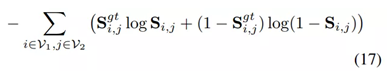
作为对比,CVPR2018的工作采用了基于像素偏移的损失函数:

在实验中,作者证明,基于交叉熵的排列损失函数能够为模型提供更精确的监督信息。在图 4所示的对比中,排列损失函数的优势被具象地阐述:图 4中,粉红色标注的两个节点(马的左耳)代表真实的匹配关系。右图中,每个节点上方的数字代表模型预测当前节点与左图粉红节点匹配的概率。在这次不理想的预测中,右图中的真值节点(右图中的粉红色节点)只获得了0.05的概率。然而,基于像素偏移的损失函数为这次预测给出了一个相当低的损失值(只有0.070);作为对比,排列损失函数能够给出一个较高的损失值(5.139)。显然,排列损失函数为模型训练提供了更加准确的监督信息。

图 4 排列损失与偏移损失对比
直观来看,在图 4所示的例子中,排列损失函数能够分清马的左、右耳,进而让模型学习其中的结构化差异;与之对比,由于马的左、右耳在空间上离得太近,偏移损失函数并不能够将它们明确地区分,因此不能为训练提供足够的监督信息。从图匹配的数学形式看,作为一个组合优化问题,图匹配问题与图像中关键点实际的像素位置并无紧密联系,采用基于交叉熵的排列损失函数迎合了图匹配作为组合优化问题的本质。
实验结果:在包括了真实图片匹配以及仿真数据集上,作者提出的PCA-GM与PIA-GM均取得了最高的匹配精度,超越了基于传统机器学习的方法以及CVPR2018 Deep Learning of Graph Matching中提出的模型GMN。
仿真数据集:
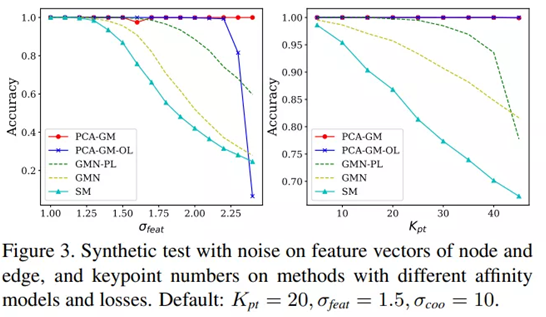
PascalVOC数据集:

Willow ObjectClass数据集:

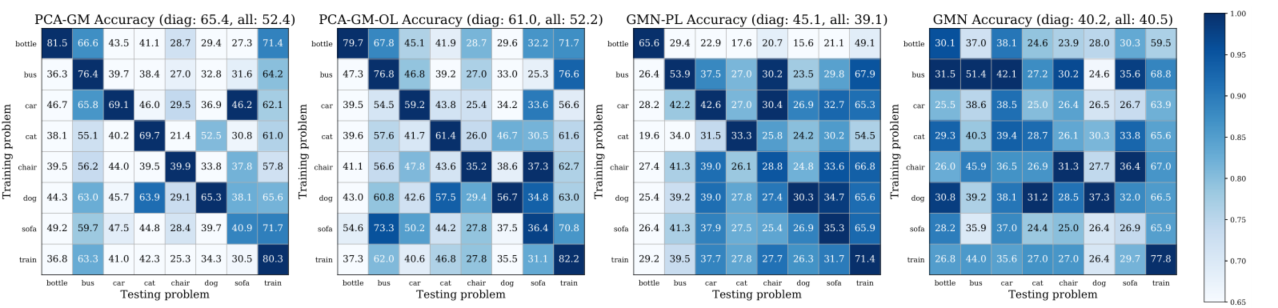
作者还通过混淆矩阵(Confusion matrix)的实验,说明了模型在不同类别的物体之间具有泛化能力。实验结果表明,PCA-GM模型学习得到的图结构在相似的类别(例如猫和狗)之间具有很好的泛化性,这说明模型学习到了图结构的相似度,展现了嵌入模型在图相关问题上的巨大潜能。
1.1.4 结论
这篇文章提出了一种基于嵌入方法的深度图匹配算法PCA-GM。PCA-GM提出了基于嵌入的图结构建模以及基于交叉熵的排列损失函数。在仿真数据集以及真实图片数据集上的实验证明了基于嵌入的深度图匹配算法的优越性。这篇文章为图匹配,尤其是深度图匹配研究提供了全新的思路。
Learning Combinatorial Embedding Networks for Deep Graph Matching(基于图嵌入的深度图匹配)的更多相关文章
- 基于图嵌入的高斯混合变分自编码器的深度聚类(Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding, DGG)
基于图嵌入的高斯混合变分自编码器的深度聚类 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedd ...
- Coursera, Deep Learning 1, Neural Networks and Deep Learning - week1, Introduction to deep learning
整个deep learing 系列课程主要包括哪些内容 Intro to Deep learning
- Coursera, Deep Learning 1, Neural Networks and Deep Learning - week4, Deep Neural Networks
Deep Neural Network Getting your matrix dimention right 选hyper-pamameter 完全是凭经验 补充阅读: cost 函数的计算公式: ...
- Coursera, Deep Learning 1, Neural Networks and Deep Learning - week3, Neural Networks Basics
NN representation 这一课主要是讲3层神经网络 下面是常见的 activation 函数.sigmoid, tanh, ReLU, leaky ReLU. Sigmoid 只用在输出0 ...
- Coursera, Deep Learning 1, Neural Networks and Deep Learning - week2, Neural Networks Basics
Logistic regression Cost function for logistic regression Gradient Descent 接下来主要讲 Vectorization Logi ...
- 深度学习材料:从感知机到深度网络A Deep Learning Tutorial: From Perceptrons to Deep Networks
In recent years, there’s been a resurgence in the field of Artificial Intelligence. It’s spread beyo ...
- Deep Learning of Graph Matching 阅读笔记
Deep Learning of Graph Matching 阅读笔记 CVPR2018的一篇文章,主要提出了一种利用深度神经网络实现端到端图匹配(Graph Matching)的方法. 该篇文章理 ...
- 《Deep Learning of Graph Matching》论文阅读
1. 论文概述 论文首次将深度学习同图匹配(Graph matching)结合,设计了end-to-end网络去学习图匹配过程. 1.1 网络学习的目标(输出) 是两个图(Graph)之间的相似度矩阵 ...
- 论文阅读 TEMPORAL GRAPH NETWORKS FOR DEEP LEARNING ON DYNAMIC GRAPHS
14 TEMPORAL GRAPH NETWORKS FOR DEEP LEARNING ON DYNAMIC GRAPHS link:https://scholar.google.com.hk/sc ...
随机推荐
- NO34 awk
- vue axios 数据请求实现
1.安装nginx npm install axios --save-dev cnpm install axios --save-dev 使用淘宝镜像 保存依赖文件到本地 装好了.packjson.j ...
- 关于C++中vector<vector<int> >的使用
1.定义 vector<vector<int>> A;//错误的定义方式 vector<vector<int> > A;//正确的定义方式 2.插入元素 ...
- 编程题目: 两个队列实现栈(Python)
感觉两个队列实现栈 比 两个栈实现队列 麻烦 1.栈为空:当两个队列都为空的时候,栈为空 2.入栈操作:当队列2为空的时候,将元素入队到队列1:当队列1位空的时候,将元素入队到队列2: 如果队列1 和 ...
- 合天rev200.exe
查过之后无壳,查看一下详细信息 运行一下. 猜测可能是输入两个password...拖到ida里面查看,shfit+f12查看 转到此处然后继续查看,找到第一个password通过 一开始时直接输入的 ...
- 数学软件实训1-MATLAB程序设计及应用初步
数学软件实训任务一 一 题目:MATLAB程序设计及应用初步 二 目的:掌握MATLAB程序设计的基本方法,会利用MATLAB程序设计思想编程处理一些简单问题. 三 要求: 1 掌握控制流的基本语法结 ...
- 010.Delphi插件之QPlugins,遍历服务接口
这个DEMO注意是用来看一个DLL所拥有的全部服务接口 演示效果如下 代码如下: unit Frm_Main; interface uses Winapi.Windows, Winapi.Messag ...
- 内存寻址能力与CPU的位宽有关系吗?
答案是:没有关系.CPU的寻址能力与它的地址总线位宽有关,而我们通常说的CPU位宽指的是数据总线位宽,它和地址总线位宽半毛钱关系也没有,自然也与寻址能力无关. 简单的说,CPU位宽指的是一个时钟周期内 ...
- HihoCoder第七周:完全背包问题
1043 : 完全背包 时间限制:20000ms 单点时限:1000ms 内存限制:256MB 描述 且说之前的故事里,小Hi和小Ho费劲心思终于拿到了茫茫多的奖券!而现在,终于到了小Ho领取奖励的时 ...
- 使用Nginx搭建Tomcat9集群,Redis实现Session共享
使用Nginx搭建Tomcat9集群,Redis实现Session共享 1.tomcat准备 首先准备两个tomcat9 ,修改配置文件server.xml 如果在多个服务器上分别启动tomcat 则 ...