入门大数据---Hbase 过滤器详解
一、HBase过滤器简介
Hbase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predicate push down)。这样可以保证过滤掉的数据不会被传送到客户端,从而减轻网络传输和客户端处理的压力。
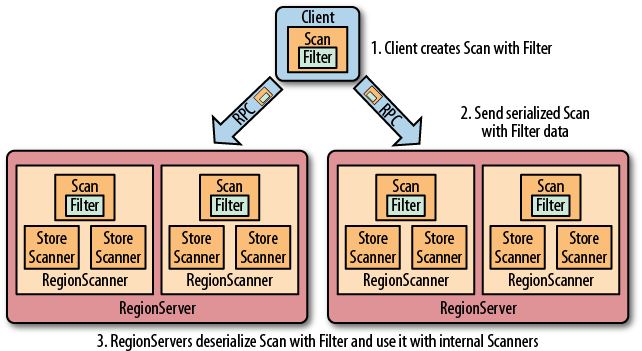
二、过滤器基础
2.1 Filter接口和FilterBase抽象类
Filter 接口中定义了过滤器的基本方法,FilterBase 抽象类实现了 Filter 接口。所有内置的过滤器则直接或者间接继承自 FilterBase 抽象类。用户只需要将定义好的过滤器通过 setFilter 方法传递给 Scan 或 put 的实例即可。
setFilter(Filter filter)
// Scan 中定义的 setFilter
@Override
public Scan setFilter(Filter filter) {
super.setFilter(filter);
return this;
}
// Get 中定义的 setFilter
@Override
public Get setFilter(Filter filter) {
super.setFilter(filter);
return this;
}
FilterBase 的所有子类过滤器如下:
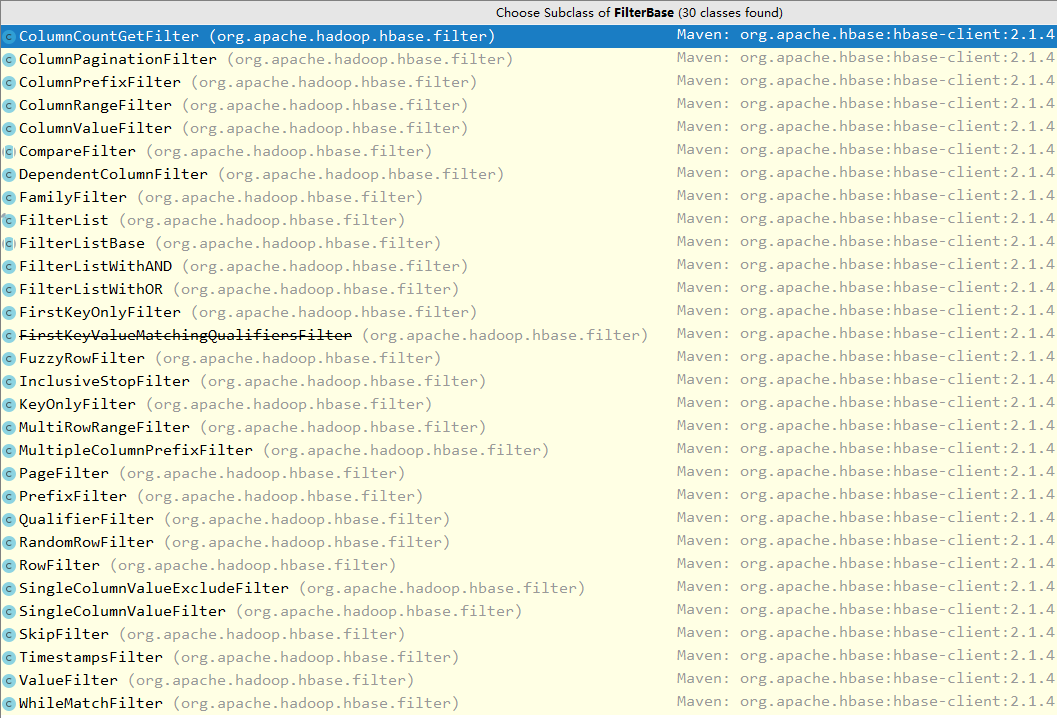
说明:上图基于当前时间点(2019.4)最新的 Hbase-2.1.4 ,下文所有说明均基于此版本。
2.2 过滤器分类
HBase 内置过滤器可以分为三类:分别是比较过滤器,专用过滤器和包装过滤器。分别在下面的三个小节中做详细的介绍。
三、比较过滤器
所有比较过滤器均继承自 CompareFilter。创建一个比较过滤器需要两个参数,分别是比较运算符和比较器实例。
public CompareFilter(final CompareOp compareOp,final ByteArrayComparable comparator) {
this.compareOp = compareOp;
this.comparator = comparator;
}
3.1 比较运算符
- LESS (<)
- LESS_OR_EQUAL (<=)
- EQUAL (=)
- NOT_EQUAL (!=)
- GREATER_OR_EQUAL (>=)
- GREATER (>)
- NO_OP (排除所有符合条件的值)
比较运算符均定义在枚举类 CompareOperator 中
@InterfaceAudience.Public
public enum CompareOperator {
LESS,
LESS_OR_EQUAL,
EQUAL,
NOT_EQUAL,
GREATER_OR_EQUAL,
GREATER,
NO_OP,
}
注意:在 1.x 版本的 HBase 中,比较运算符定义在
CompareFilter.CompareOp枚举类中,但在 2.0 之后这个类就被标识为 @deprecated ,并会在 3.0 移除。所以 2.0 之后版本的 HBase 需要使用CompareOperator这个枚举类。
3.2 比较器
所有比较器均继承自 ByteArrayComparable 抽象类,常用的有以下几种:

- BinaryComparator : 使用
Bytes.compareTo(byte [],byte [])按字典序比较指定的字节数组。 - BinaryPrefixComparator : 按字典序与指定的字节数组进行比较,但只比较到这个字节数组的长度。
- RegexStringComparator : 使用给定的正则表达式与指定的字节数组进行比较。仅支持
EQUAL和NOT_EQUAL操作。 - SubStringComparator : 测试给定的子字符串是否出现在指定的字节数组中,比较不区分大小写。仅支持
EQUAL和NOT_EQUAL操作。 - NullComparator :判断给定的值是否为空。
- BitComparator :按位进行比较。
BinaryPrefixComparator 和 BinaryComparator 的区别不是很好理解,这里举例说明一下:
在进行 EQUAL 的比较时,如果比较器传入的是 abcd 的字节数组,但是待比较数据是 abcdefgh:
- 如果使用的是
BinaryPrefixComparator比较器,则比较以abcd字节数组的长度为准,即efgh不会参与比较,这时候认为abcd与abcdefgh是满足EQUAL条件的; - 如果使用的是
BinaryComparator比较器,则认为其是不相等的。
3.3 比较过滤器种类
比较过滤器共有五个(Hbase 1.x 版本和 2.x 版本相同),见下图:
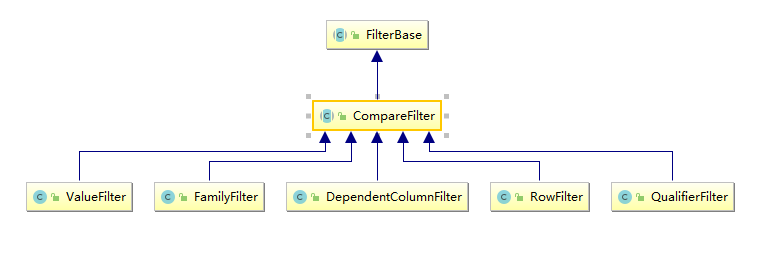
- RowFilter :基于行键来过滤数据;
- FamilyFilterr :基于列族来过滤数据;
- QualifierFilterr :基于列限定符(列名)来过滤数据;
- ValueFilterr :基于单元格 (cell) 的值来过滤数据;
- DependentColumnFilter :指定一个参考列来过滤其他列的过滤器,过滤的原则是基于参考列的时间戳来进行筛选 。
前四种过滤器的使用方法相同,均只要传递比较运算符和运算器实例即可构建,然后通过 setFilter 方法传递给 scan:
Filter filter = new RowFilter(CompareOperator.LESS_OR_EQUAL,
new BinaryComparator(Bytes.toBytes("xxx")));
scan.setFilter(filter);
DependentColumnFilter 的使用稍微复杂一点,这里单独做下说明。
3.4 DependentColumnFilter
可以把 DependentColumnFilter 理解为一个 valueFilter 和一个时间戳过滤器的组合。DependentColumnFilter 有三个带参构造器,这里选择一个参数最全的进行说明:
DependentColumnFilter(final byte [] family, final byte[] qualifier,
final boolean dropDependentColumn, final CompareOperator op,
final ByteArrayComparable valueComparator)
- family :列族
- qualifier :列限定符(列名)
- dropDependentColumn :决定参考列是否被包含在返回结果内,为 true 时表示参考列被返回,为 false 时表示被丢弃
- op :比较运算符
- valueComparator :比较器
这里举例进行说明:
DependentColumnFilter dependentColumnFilter = new DependentColumnFilter(
Bytes.toBytes("student"),
Bytes.toBytes("name"),
false,
CompareOperator.EQUAL,
new BinaryPrefixComparator(Bytes.toBytes("xiaolan")));
首先会去查找
student:name中值以xiaolan开头的所有数据获得参考数据集,这一步等同于 valueFilter 过滤器;其次再用参考数据集中所有数据的时间戳去检索其他列,获得时间戳相同的其他列的数据作为
结果数据集,这一步等同于时间戳过滤器;最后如果
dropDependentColumn为 true,则返回参考数据集+结果数据集,若为 false,则抛弃参考数据集,只返回结果数据集。
四、专用过滤器
专用过滤器通常直接继承自 FilterBase,适用于范围更小的筛选规则。
4.1 单列列值过滤器 (SingleColumnValueFilter)
基于某列(参考列)的值决定某行数据是否被过滤。其实例有以下方法:
- setFilterIfMissing(boolean filterIfMissing) :默认值为 false,即如果该行数据不包含参考列,其依然被包含在最后的结果中;设置为 true 时,则不包含;
- setLatestVersionOnly(boolean latestVersionOnly) :默认为 true,即只检索参考列的最新版本数据;设置为 false,则检索所有版本数据。
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
"student".getBytes(),
"name".getBytes(),
CompareOperator.EQUAL,
new SubstringComparator("xiaolan"));
singleColumnValueFilter.setFilterIfMissing(true);
scan.setFilter(singleColumnValueFilter);
4.2 单列列值排除器 (SingleColumnValueExcludeFilter)
SingleColumnValueExcludeFilter 继承自上面的 SingleColumnValueFilter,过滤行为与其相反。
4.3 行键前缀过滤器 (PrefixFilter)
基于 RowKey 值决定某行数据是否被过滤。
PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes("xxx"));
scan.setFilter(prefixFilter);
4.4 列名前缀过滤器 (ColumnPrefixFilter)
基于列限定符(列名)决定某行数据是否被过滤。
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter(Bytes.toBytes("xxx"));
scan.setFilter(columnPrefixFilter);
4.5 分页过滤器 (PageFilter)
可以使用这个过滤器实现对结果按行进行分页,创建 PageFilter 实例的时候需要传入每页的行数。
public PageFilter(final long pageSize) {
Preconditions.checkArgument(pageSize >= 0, "must be positive %s", pageSize);
this.pageSize = pageSize;
}
下面的代码体现了客户端实现分页查询的主要逻辑,这里对其进行一下解释说明:
客户端进行分页查询,需要传递 startRow(起始 RowKey),知道起始 startRow 后,就可以返回对应的 pageSize 行数据。这里唯一的问题就是,对于第一次查询,显然 startRow 就是表格的第一行数据,但是之后第二次、第三次查询我们并不知道 startRow,只能知道上一次查询的最后一条数据的 RowKey(简单称之为 lastRow)。
我们不能将 lastRow 作为新一次查询的 startRow 传入,因为 scan 的查询区间是[startRow,endRow) ,即前开后闭区间,这样 startRow 在新的查询也会被返回,这条数据就重复了。
同时在不使用第三方数据库存储 RowKey 的情况下,我们是无法通过知道 lastRow 的下一个 RowKey 的,因为 RowKey 的设计可能是连续的也有可能是不连续的。
由于 Hbase 的 RowKey 是按照字典序进行排序的。这种情况下,就可以在 lastRow 后面加上 0 ,作为 startRow 传入,因为按照字典序的规则,某个值加上 0 后的新值,在字典序上一定是这个值的下一个值,对于 HBase 来说下一个 RowKey 在字典序上一定也是等于或者大于这个新值的。
所以最后传入 lastRow+0,如果等于这个值的 RowKey 存在就从这个值开始 scan,否则从字典序的下一个 RowKey 开始 scan。
25 个字母以及数字字符,字典排序如下:
'0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... < 'z'
分页查询主要实现逻辑:
byte[] POSTFIX = new byte[] { 0x00 };
Filter filter = new PageFilter(15);
int totalRows = 0;
byte[] lastRow = null;
while (true) {
Scan scan = new Scan();
scan.setFilter(filter);
if (lastRow != null) {
// 如果不是首行 则 lastRow + 0
byte[] startRow = Bytes.add(lastRow, POSTFIX);
System.out.println("start row: " +
Bytes.toStringBinary(startRow));
scan.withStartRow(startRow);
}
ResultScanner scanner = table.getScanner(scan);
int localRows = 0;
Result result;
while ((result = scanner.next()) != null) {
System.out.println(localRows++ + ": " + result);
totalRows++;
lastRow = result.getRow();
}
scanner.close();
//最后一页,查询结束
if (localRows == 0) break;
}
System.out.println("total rows: " + totalRows);
需要注意的是在多台 Regin Services 上执行分页过滤的时候,由于并行执行的过滤器不能共享它们的状态和边界,所以有可能每个过滤器都会在完成扫描前获取了 PageCount 行的结果,这种情况下会返回比分页条数更多的数据,分页过滤器就有失效的可能。
4.6 时间戳过滤器 (TimestampsFilter)
List<Long> list = new ArrayList<>();
list.add(1554975573000L);
TimestampsFilter timestampsFilter = new TimestampsFilter(list);
scan.setFilter(timestampsFilter);
4.7 首次行键过滤器 (FirstKeyOnlyFilter)
FirstKeyOnlyFilter 只扫描每行的第一列,扫描完第一列后就结束对当前行的扫描,并跳转到下一行。相比于全表扫描,其性能更好,通常用于行数统计的场景,因为如果某一行存在,则行中必然至少有一列。
FirstKeyOnlyFilter firstKeyOnlyFilter = new FirstKeyOnlyFilter();
scan.set(firstKeyOnlyFilter);
五、包装过滤器
包装过滤器就是通过包装其他过滤器以实现某些拓展的功能。
5.1 SkipFilter过滤器
SkipFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,则拓展过滤整行数据。下面是一个使用示例:
// 定义 ValueFilter 过滤器
Filter filter1 = new ValueFilter(CompareOperator.NOT_EQUAL,
new BinaryComparator(Bytes.toBytes("xxx")));
// 使用 SkipFilter 进行包装
Filter filter2 = new SkipFilter(filter1);
5.2 WhileMatchFilter过滤器
WhileMatchFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,WhileMatchFilter 则结束本次扫描,返回已经扫描到的结果。下面是其使用示例:
Filter filter1 = new RowFilter(CompareOperator.NOT_EQUAL,
new BinaryComparator(Bytes.toBytes("rowKey4")));
Scan scan = new Scan();
scan.setFilter(filter1);
ResultScanner scanner1 = table.getScanner(scan);
for (Result result : scanner1) {
for (Cell cell : result.listCells()) {
System.out.println(cell);
}
}
scanner1.close();
System.out.println("--------------------");
// 使用 WhileMatchFilter 进行包装
Filter filter2 = new WhileMatchFilter(filter1);
scan.setFilter(filter2);
ResultScanner scanner2 = table.getScanner(scan);
for (Result result : scanner1) {
for (Cell cell : result.listCells()) {
System.out.println(cell);
}
}
scanner2.close();
rowKey0/student:name/1555035006994/Put/vlen=8/seqid=0
rowKey1/student:name/1555035007019/Put/vlen=8/seqid=0
rowKey2/student:name/1555035007025/Put/vlen=8/seqid=0
rowKey3/student:name/1555035007037/Put/vlen=8/seqid=0
rowKey5/student:name/1555035007051/Put/vlen=8/seqid=0
rowKey6/student:name/1555035007057/Put/vlen=8/seqid=0
rowKey7/student:name/1555035007062/Put/vlen=8/seqid=0
rowKey8/student:name/1555035007068/Put/vlen=8/seqid=0
rowKey9/student:name/1555035007073/Put/vlen=8/seqid=0
--------------------
rowKey0/student:name/1555035006994/Put/vlen=8/seqid=0
rowKey1/student:name/1555035007019/Put/vlen=8/seqid=0
rowKey2/student:name/1555035007025/Put/vlen=8/seqid=0
rowKey3/student:name/1555035007037/Put/vlen=8/seqid=0
可以看到被包装后,只返回了 rowKey4 之前的数据。
六、FilterList
以上都是讲解单个过滤器的作用,当需要多个过滤器共同作用于一次查询的时候,就需要使用 FilterList。FilterList 支持通过构造器或者 addFilter 方法传入多个过滤器。
// 构造器传入
public FilterList(final Operator operator, final List<Filter> filters)
public FilterList(final List<Filter> filters)
public FilterList(final Filter... filters)
// 方法传入
public void addFilter(List<Filter> filters)
public void addFilter(Filter filter)
多个过滤器组合的结果由 operator 参数定义 ,其可选参数定义在 Operator 枚举类中。只有 MUST_PASS_ALL 和 MUST_PASS_ONE 两个可选的值:
- MUST_PASS_ALL :相当于 AND,必须所有的过滤器都通过才认为通过;
- MUST_PASS_ONE :相当于 OR,只有要一个过滤器通过则认为通过。
@InterfaceAudience.Public
public enum Operator {
/** !AND */
MUST_PASS_ALL,
/** !OR */
MUST_PASS_ONE
}
使用示例如下:
List<Filter> filters = new ArrayList<Filter>();
Filter filter1 = new RowFilter(CompareOperator.GREATER_OR_EQUAL,
new BinaryComparator(Bytes.toBytes("XXX")));
filters.add(filter1);
Filter filter2 = new RowFilter(CompareOperator.LESS_OR_EQUAL,
new BinaryComparator(Bytes.toBytes("YYY")));
filters.add(filter2);
Filter filter3 = new QualifierFilter(CompareOperator.EQUAL,
new RegexStringComparator("ZZZ"));
filters.add(filter3);
FilterList filterList = new FilterList(filters);
Scan scan = new Scan();
scan.setFilter(filterList);
参考资料
HBase: The Definitive Guide _> Chapter 4. Client API: Advanced Features
入门大数据---Hbase 过滤器详解的更多相关文章
- 入门大数据---Hbase协处理器详解
一.简述 Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立"二级索引",难以执 行求和.计数.排序等操作.比如,在旧版本的(<0.92)Hbase 中,统计数 ...
- 入门大数据---Kafka生产者详解
一.生产者发送消息的过程 首先介绍一下 Kafka 生产者发送消息的过程: Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发 ...
- 入门大数据---Kafka消费者详解
一.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响.Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经 ...
- HBase 学习之路(七)——HBase过滤器详解
一.HBase过滤器简介 Hbase提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predica ...
- HBase 系列(七)——HBase 过滤器详解
一.HBase过滤器简介 Hbase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predic ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 入门大数据---Hbase是什么?
一.Hbase是什么? Hbase属于NoSql的一种. NoSql数据库分为如下几类: Key-Value类型数据库 这类数据库主要会使用到一个哈希表,这个表有一个特定的键和一个指针指向特定的数据. ...
- 入门大数据---Hbase的SQL中间层_Phoenix
一.Phoenix简介 Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据.在 Phoenix 之前,如果你要访问 HBase,只能 ...
- Java+大数据开发——HDFS详解
1. HDFS 介绍 • 什么是HDFS 首先,它是一个文件系统,用于存储文件,通过统一的命名空间--目录树来定位文件. 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角 ...
随机推荐
- .net core 上传大文件
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Thr ...
- 开心一下-实现一个基于Java的中文编程语言2
https://mp.weixin.qq.com/s/VmCTvh0c7X9DjIgIMycdlw 上一篇所提到的只是使用中文写Java,而不能算作一门新的语言.作为一门中文语言,需要语言提供的关 ...
- 【Hadoop高级】Hadoop HA、hdfs安全模式
Hadoop HA Safemode(安全模式) During start up the NameNode loads the file system state from the fsimage a ...
- 我眼中的华为公有云AI平台--ModelArts
前言 AWS Sagemaker has been a great deal for most data scientists who would want to accomplish a truly ...
- ASP.NET中IHttpHandler与IHttpModule的区别(带样例说明)
IHttpModule相对来说,是一个网页的添加 IHttpHandler相对来说,却是网页的替换 先建一个HandlerDemo的类 using System; using System.Colle ...
- Java实现 蓝桥杯VIP 算法训练 校门外的树
问题描述 某校大门外长度为L的马路上有一排树,每两棵相邻的树之间的间隔都是1米.我们可以把马路看成一个数轴,马路的一端在数轴0的位置,另一端在L的位置:数轴上的每个整数点,即0,1,2,--,L,都种 ...
- Java实现背包问题
1 问题描述 给定n个重量为w1,w2,w3,-,wn,价值为v1,v2,-,vn的物品和一个承重为W的背包,求这些物品中最有价值的子集(PS:每一个物品要么选一次,要么不选),并且要能够装到背包. ...
- Java实现回文判断
1 问题描述 给定一个字符串,如何判断这个字符串是否是回文串? 所谓回文串,是指正读和反读都一样的字符串,如madam.我爱我等. 2 解决方案 解决上述问题,有两种方法可供参考: (1)从字符串两头 ...
- java实现第五届蓝桥杯锦标赛
锦标赛 这题小编能力有限,还望大佬解决 题目描述 如果要在n个数据中挑选出第一大和第二大的数据(要求输出数据所在位置和值),使用什么方法比较的次数最少?我们可以从体育锦标赛中受到启发. 如图[1.pn ...
- PAT 反转链表
给定一个常数 K 以及一个单链表 L,请编写程序将 L 中每 K 个结点反转.例如:给定 L 为 1→2→3→4→5→6,K 为 3,则输出应该为 3→2→1→6→5→4:如果 K 为 4,则输出应该 ...