Spark入门(四)--Spark的map、flatMap、mapToPair
spark的RDD操作
在上一节Spark经典的单词统计中,了解了几个RDD操作,包括flatMap,map,reduceByKey,以及后面简化的方案,countByValue。那么这一节将介绍更多常用的RDD操作,并且为每一种RDD我们分解来看其运作的情况。
spark的flatMap
flatMap,有着一对多的表现,输入一输出多。并且会将每一个输入对应的多个输出整合成一个大的集合,当然不用担心这个集合会超出内存的范围,因为spark会自觉地将过多的内容溢写到磁盘。当然如果对运行的机器的内存有着足够的信心,也可以将内容存储到内存中。
为了更好地理解flatMap,我们将举一个例子来说明。当然和往常一样,会准备好例子对应的数据文本,文本名称为uv.txt,该文本和示例程序可以从github上下载。以下会用三种语言:scala、java、python去描述,同时在java中会对比采用java和java8来实现各个例子。其中java和scala程序在github能直接下载,而python则暂时不提供,后续会补上。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object SparkFlatMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkFlatMap")
val sc = new SparkContext(conf)
//设置数据路径
val textData = sc.textFile("./uv.txt")
//输出处理前总行数
println("before:"+textData.count()+"行")
//输出处理前第一行数据
println("first line:"+textData.first())
//进行flatMap处理
val flatData = textData.flatMap(line => line.split(" "))
//输出处理后总行数
println("after:"+flatData.count())
//输出处理后第一行数据
println("first line:"+flatData.first())
//将结果保存在flatResultScala文件夹中
flatData.saveAsTextFile("./flatResultScala")
}
}
复制代码java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import java.util.Arrays;
import java.util.Iterator;
public class SparkFlatMapJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkFlatMapJava");
JavaSparkContext sc = new JavaSparkContext(conf);
//java实现
flatMapJava(sc);
//java8实现
flatMapJava8(sc);
}
public static void flatMapJava(JavaSparkContext sc){
//设置数据路径
JavaRDD<String> textData = sc.textFile("./uv.txt");
//输出处理前总行数
System.out.println("before:"+textData.count()+"行");
//输出处理前第一行数据
System.out.println("first line:"+textData.first()+"行");
//进行flatMap处理
JavaRDD<String> flatData = textData.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//输出处理后总行数
System.out.println("after:"+flatData.count()+"行");
//输出处理后第一行数据
System.out.println("first line:"+flatData.first()+"行");
//将结果保存在flatResultScala文件夹中
flatData.saveAsTextFile("./flatResultJava");
}
public static void flatMapJava8(JavaSparkContext sc){
sc.textFile("./uv.txt")
.flatMap(line -> Arrays.asList(line.split(" ")).iterator())
.saveAsTextFile("./flatResultJava8");
}
}
复制代码python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("FlatMapPython")
sc = SparkContext(conf=conf)
textData = sc.textFile("./uv.txt")
print("before:"+str(textData.count())+"行")
print("first line"+textData.first())
flatData = textData.flatMap(lambda line:line.split(" "))
print("after:"+str(flatData.count())+"行")
print("first line"+flatData.first())
flatData.saveAsTextFile("./resultFlatMap")
复制代码运行任意程序,得到相同结果
before:86400行
first line:2015-08-24_00:00:00 55311 buy
after:259200
first line:2015-08-24_00:00:00
复制代码查看文件
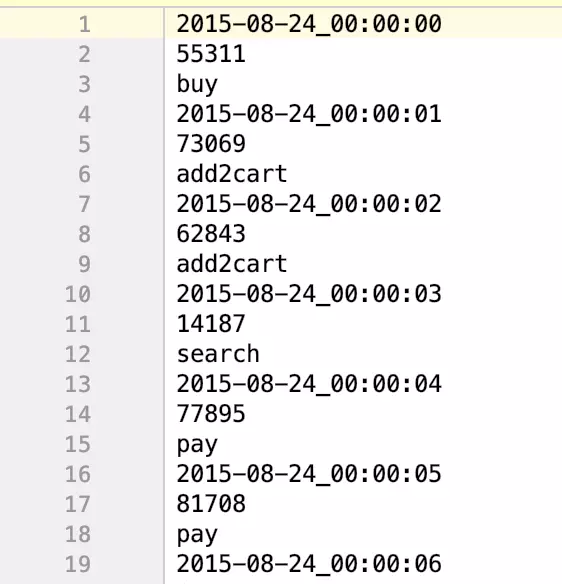
很显然每一行都按照空格拆分成了三行,因此总行数是拆分前的三倍,第一行的内容只剩下原第一行的第一个数据,时间。这样flatMap的作用就很明显了。
spark的map
用同样的方法来展示map操作,与flatMap不同的是,map通常是一对一,即输入一个,对应输出一个。但是输出的结果可以是一个元组,一个元组则可能包含多个数据,但是一个元组是一个整体,因此算是一个元素。这里注意到在输出的结果是元组时,scala和python能够很正常处理,而在java中则有一点不同。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object SparkMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkFlatMap")
val sc = new SparkContext(conf)
val textData = sc.textFile("./uv.txt")
//得到一个最后一个操作值,前面的时间和次数舍弃
val mapData1 = textData.map(line => line.split(" ")(2))
println(mapData1.count())
println(mapData1.first())
mapData1.saveAsTextFile("./resultMapScala")
//得到一个最后两个值,前面的时间舍弃
val mapData2 = textData.map(line => (line.split(" ")(1),line.split(" ")(2)))
println(mapData2.count())
println(mapData2.first())
//将所有值存到元组中去
val mapData3 = textData.map(line => (line.split(" ")(1),line.split(" ")(1),line.split(" ")(2)))
println(mapData3.count())
println(mapData3.first())
}
}
复制代码java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.codehaus.janino.Java;
import scala.Tuple2;
import scala.Tuple3;
public class SparkMapJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkFlatMapJava");
JavaSparkContext sc = new JavaSparkContext(conf);
//java实现
mapJava(sc);
//java8实现
mapJava8(sc);
}
public static void mapJava(JavaSparkContext sc){
JavaRDD<String> txtData = sc.textFile("./uv.txt");
//保留最后一个值
JavaRDD<String> mapData1 = txtData.map(new Function<String, String>() {
@Override
public String call(String s) throws Exception {
return s.split(" ")[2];
}
});
System.out.println(mapData1.count());
System.out.println(mapData1.first());
//保留最后两个值
JavaRDD<Tuple2<String,String>> mapData2 = txtData.map(new Function<String, Tuple2<String,String>>() {
@Override
public Tuple2<String,String> call(String s) throws Exception {
return new Tuple2<>(s.split(" ")[1],s.split(" ")[2]);
}
});
System.out.println(mapData2.count());
System.out.println(mapData2.first());
//保留最后三个值
JavaRDD<Tuple3<String,String,String>> mapData3 = txtData.map(new Function<String, Tuple3<String,String,String>>() {
@Override
public Tuple3<String,String,String> call(String s) throws Exception {
return new Tuple3<>(s.split(" ")[0],s.split(" ")[1],s.split(" ")[2]);
}
});
System.out.println(mapData2.count());
System.out.println(mapData2.first());
}
public static void mapJava8(JavaSparkContext sc){
JavaRDD<String> mapData1 = sc.textFile("./uv.txt").map(line -> line.split(" ")[2]);
System.out.println(mapData1.count());
System.out.println(mapData1.first());
JavaRDD<Tuple2<String,String>> mapData2 = sc.textFile("./uv.txt").map(line -> new Tuple2<String, String>(line.split(" ")[1],line.split(" ")[2]));
System.out.println(mapData2.count());
System.out.println(mapData2.first());
JavaRDD<Tuple3<String,String,String>> mapData3 = sc.textFile("./uv.txt").map(line -> new Tuple3<String, String, String>(line.split(" ")[0],line.split(" ")[1],line.split(" ")[2]));
System.out.println(mapData3.count());
System.out.println(mapData3.first());
}
}
复制代码python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("FlatMapPython")
sc = SparkContext(conf=conf)
textData = sc.textFile("./uv.txt")
mapData1 = textData.map(lambda line : line.split(" ")[2])
print(mapData1.count())
print(mapData1.first())
mapData2 = textData.map(lambda line : (line.split(" ")[1],line.split(" ")[2]))
print(mapData2.count())
print(mapData2.first())
mapData3 = textData.map(lambda line : (line.split(" ")[0],line.split(" ")[1],line.split(" ")[2]))
print(mapData3.count())
print(mapData3.first())
复制代码运行任意程序,得到相同结果
86400
buy
86400
(55311,buy)
86400
(55311,55311,buy)
复制代码Java中独有的mapToPair
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class SparkMapToPair {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkFlatMapJava");
JavaSparkContext sc = new JavaSparkContext(conf);
mapToPairJava(sc);
mapToPairJava8(sc);
}
public static void mapToPairJava(JavaSparkContext sc){
JavaPairRDD<String,String> pairRDD = sc.textFile("./uv.txt").mapToPair(new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String s) throws Exception {
return new Tuple2<>(s.split(" ")[1],s.split(" ")[2]);
}
});
System.out.println(pairRDD.count());
System.out.println(pairRDD.first());
}
public static void mapToPairJava8(JavaSparkContext sc){
JavaPairRDD<String,String> pairRDD = sc.textFile("./uv.txt").mapToPair(line -> new Tuple2<>(line.split(" ")[1],line.split(" ")[2]));
System.out.println(pairRDD.count());
System.out.println(pairRDD.first());
}
}
复制代码运行得到结果
86400
(55311,buy)
复制代码显然我们发现这个结果,和用map处理保留后两个的结果是一致的。灵活使用map、flatMap、mapToPair将非常重要,后面还将有运用多种操作去处理复杂的数据。以上所有程序的代码都能够在GitHub上下载
转自:https://juejin.im/post/5c77e383f265da2d8f474e29
Spark入门(四)--Spark的map、flatMap、mapToPair的更多相关文章
- 一、spark入门之spark shell:wordcount
1.安装完spark,进入spark中bin目录: bin/spark-shell scala> val textFile = sc.textFile("/Users/admin/ ...
- 二、spark入门之spark shell:文本中发现5个最常用的word
scala> val textFile = sc.textFile("/Users/admin/spark-1.5.1-bin-hadoop2.4/README.md") s ...
- Spark入门:Spark运行架构(Python版)
此文为个人学习笔记如需系统学习请访问http://dblab.xmu.edu.cn/blog/1709-2/ 基本概念 * RDD:是弹性分布式数据集(Resilient Distributed ...
- Spark 学习笔记之 map/flatMap/filter/mapPartitions/mapPartitionsWithIndex/sample
map/flatMap/filter/mapPartitions/mapPartitionsWithIndex/sample:
- Spark 入门
Spark 入门 目录 一. 1. 2. 3. 二. 三. 1. 2. 3. (1) (2) (3) 4. 5. 四. 1. 2. 3. 4. 5. 五. Spark Shell使用 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .SparkSQL的发展历程 1.1 Hive and Shark SparkSQL的前身是 ...
- spark 入门学习 核心api
spark入门教程(3)--Spark 核心API开发 原创 2016年04月13日 20:52:28 标签: spark / 分布式 / 大数据 / 教程 / 应用 4999 本教程源于2016年3 ...
随机推荐
- Java枚举的作用和用法
从没有枚举的时代说起 在枚举出现之前,如果想要表示一组特定的离散值,往往使用一些常量.例如: [Java] 纯文本查看 复制代码 ? 01 02 03 04 05 06 07 08 09 10 11 ...
- Nginx笔记:支持对用户提交URL和服务的URL不一致时,保持对POST提交的支持
用户访问的URL和服务的URL不一致,需要对URL修改,同时使用的是POST提交方式 location ~* ^/portalproxy/([-]*)/portal$ { #rewrite '^/po ...
- Floyd算法-dp问题
求结点对之间有负数的距离.限制条件:不允许有包含负权值的边组成的回路. 例子: 1.初始化 其中distance矩阵表示i,j两结点之间的距离. path矩阵,以第一行为例,表示0->0值为n表 ...
- Allure介绍
以下内容基于pytest的框架进行展示: 什么是Allure Allure是一个独立的报告插件,生成美观易读的报告,目前支持语言:Java, PHP, Ruby, Python, Scala, C#. ...
- H2O theme for Jekyll
正如我在微博上所说的,使用Jekyll半年以来一直没有令我满意的主题模板,所以开始计划自己写一套好看又好用的主题模板.设计之初就明确了极简主义,风格采用扁平化了,通过卡片式设计来进行区块分明的布局,参 ...
- 基于物理的渲染——间接光照
在前面的文章中我们已经给出了基于物理的渲染方程: 并介绍了直接光照的实现.然而在自然界中,一个物体不会单独存在,光源会照射到其他的物体上,反射的光会有一部分反射到物体上.为了模拟这种环境光照的形式,我 ...
- JAVA:初识Java · Xer97
1. 什么是Java Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承.指针等概念,因此Java语言具有功能强大和简单易用两个特征. Java语言作为静 ...
- 疯狂补贴的4G+ 会是又一个资费陷阱吗?
会是又一个资费陷阱吗?" title="疯狂补贴的4G+ 会是又一个资费陷阱吗?"> 常言说得好,防火防盗防运营商--具有垄断性质的中国移动.联通.电信三大基础 ...
- PHP正则表达式-修饰符
我们在PHP正则表达式的学习中会碰到修饰符,那么关于PHP正则表达式修饰符的理解以及使用我们需要注意什么呢?那么我们来具体的看看它的概念以及相关内容.在学习PHP正则表达式修饰符之前先来理解下贪婪模式 ...
- Hadoop环境搭建问题总结
最近抽空搭建了Hadoop完全分布式环境,期间遇到了很多问题,大部分问题还是可以在网上搜到的,这里说下自己遇到的两个没有找到结果的问题吧. 1.启动时报:没有那个文件或目录 原因:三台机器的用户名不一 ...