HiBench成长笔记——(6) HiBench测试结果分析
| Scan |  |
| Join | 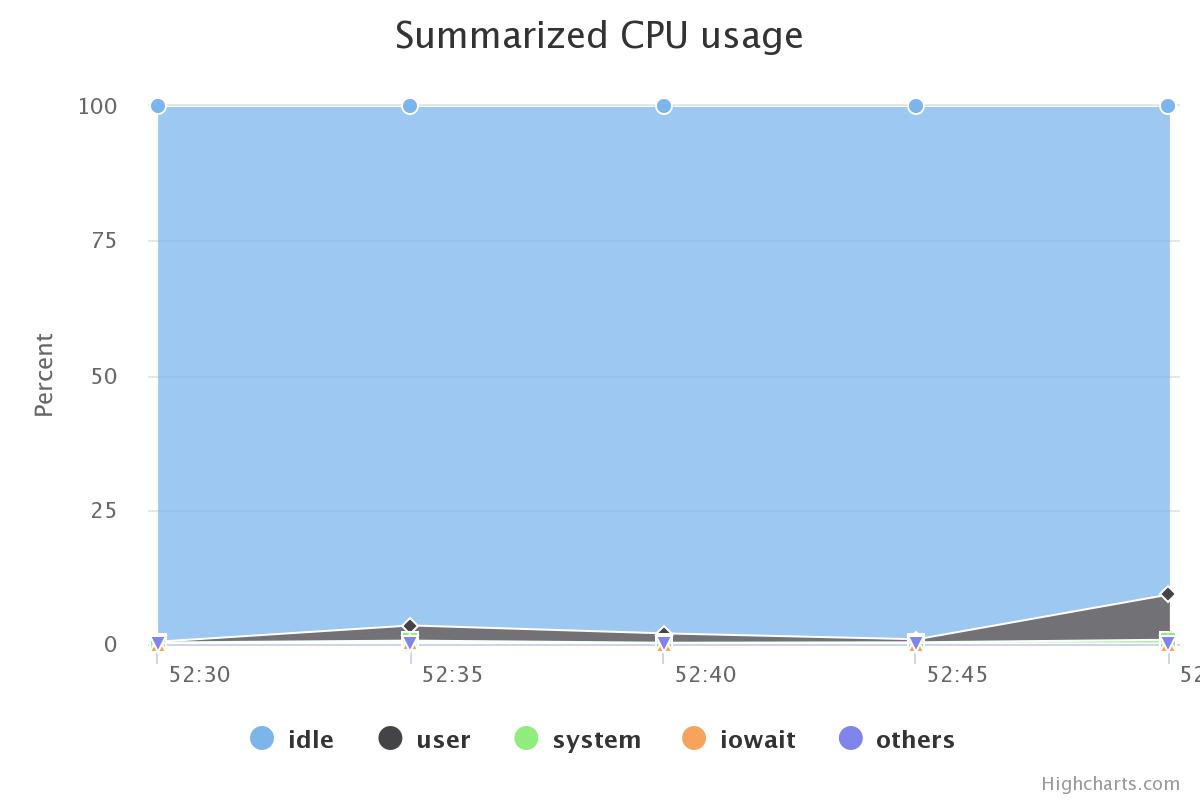 |
| Aggregation |  |
| Scan |  |
| Join |  |
| Aggregation | 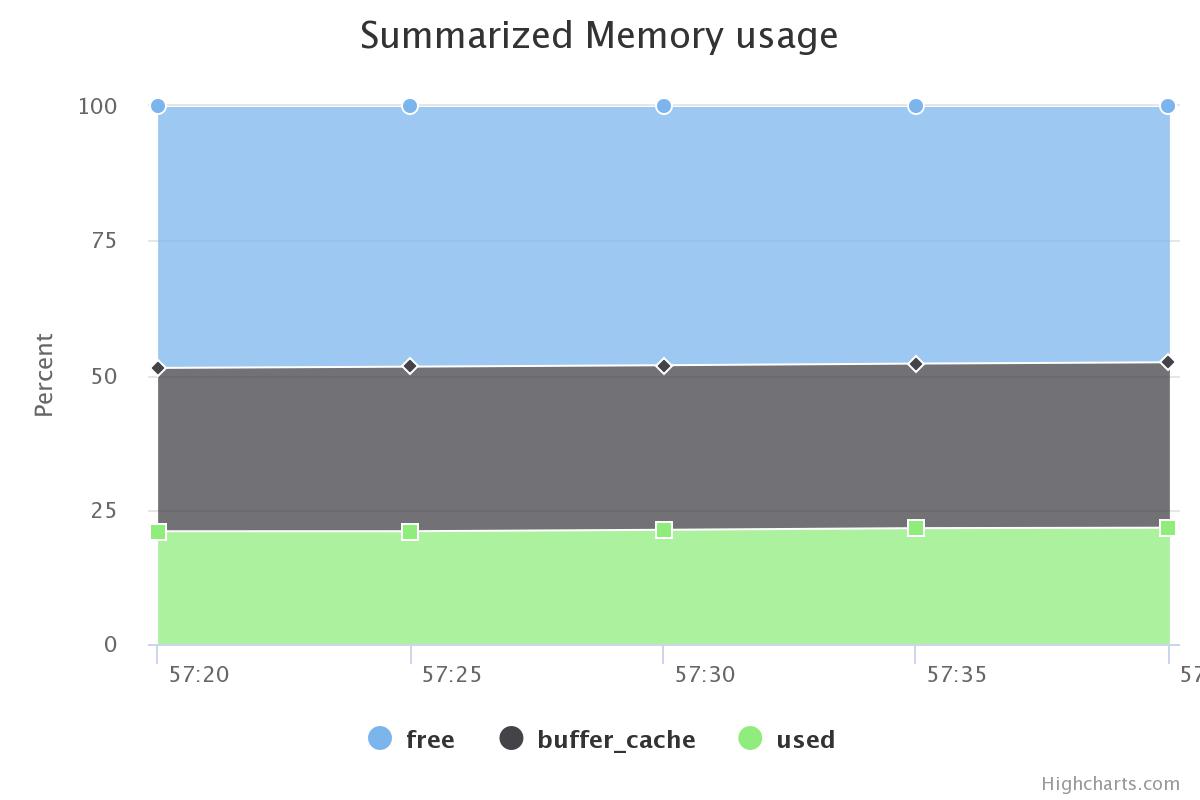 |
| Scan |  |
| Join |  |
| Aggregation |  |
| Scan |  |
| Join |  |
| Aggregation |  |
| Scan |  |
| Join | 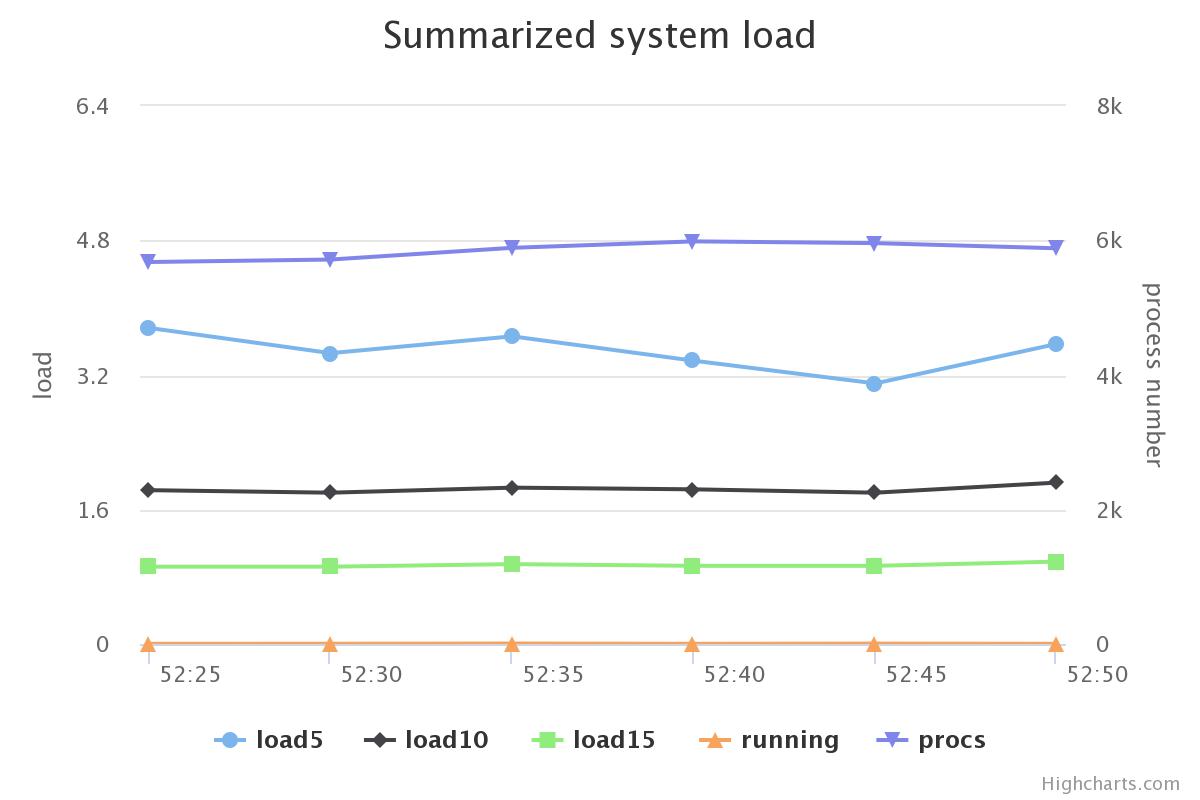 |
| Aggregation |  |
HiBench成长笔记——(6) HiBench测试结果分析的更多相关文章
- HiBench成长笔记——(3) HiBench测试Spark
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 创建并修改配置文件conf/spa ...
- HiBench成长笔记——(5) HiBench-Spark-SQL-Scan源码分析
run.sh #!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributo ...
- HiBench成长笔记——(4) HiBench测试Spark SQL
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 和 https://www.cnb ...
- HiBench成长笔记——(1) HiBench概述
测试分类 HiBench共计19个测试方向,可大致分为6个测试类别:分别是micro,ml(机器学习),sql,graph,websearch和streaming. 2.1 micro Benchma ...
- HiBench成长笔记——(11) 分析源码run.sh
#!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor licen ...
- HiBench成长笔记——(10) 分析源码execute_with_log.py
#!/usr/bin/env python2 # Licensed to the Apache Software Foundation (ASF) under one or more # contri ...
- HiBench成长笔记——(9) 分析源码monitor.py
monitor.py 是主监控程序,将监控数据写入日志,并统计监控数据生成HTML统计展示页面: #!/usr/bin/env python2 # Licensed to the Apache Sof ...
- HiBench成长笔记——(8) 分析源码workload_functions.sh
workload_functions.sh 是测试程序的入口,粘连了监控程序 monitor.py 和 主运行程序: #!/bin/bash # Licensed to the Apache Soft ...
- HiBench成长笔记——(2) CentOS部署安装HiBench
安装Scala 使用spark-shell命令进入shell模式,查看spark版本和Scala版本: 下载Scala2.10.5 wget https://downloads.lightbend.c ...
随机推荐
- mybatis=<>的写法
第一种写法(1): 原符号 < <= > >= & ' "替换符号 < <= > >= & ' " ...
- oracle连接种类
等连接:连接条件使用等号 非等连接:连接条件使用等号以外的其它符号 内连接:根据指定的连接条件进行连接查询,满足连接条件的数据才会出现在结果集 外连接:在内连接的基础上,将某个连接表不符合连接条件的记 ...
- cin和cout输⼊输出
写再最前面:摘录于柳神的笔记: 就如同 scanf 和 printf 在 stdio.h 头⽂件中⼀样, cin 和 cout 在头⽂件 iostream ⾥⾯,看名字就知 道, io 是输⼊输出 ...
- System.arraycopy方法解释
数组拷贝 public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int lengt ...
- [HEOI 2013]SAO
Description 题库连接 给你一个 \(n\) 个节点的有向树,问你这棵树的拓扑序个数,对大质数取模.多测,测试组数 \(T\). \(1\leq n\leq 1000, 1\leq T\le ...
- Java解析Json字符串--数组或列表
Json示例: [ { "age": 25, "gender": "female", "grades": "三 ...
- treap(堆树)
# 2018-09-27 17:35:58 我实现的这个treap不能算是堆.有问题 最近对堆这种结构有点感兴趣,然后想用指针的方式实现一个堆而不是利用数组这种结构,于是自己想到了一个用二叉树结构实现 ...
- table左边固定-底部横向滚动条-demo
图: 代码: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www. ...
- package.json中一些配置项的含义
{ "name": "webpack-demo", "version": "1.0.0", "de ...
- The Google File System中文版
译者:alex 摘要 我们设计并实现了Google GFS文件系统,一个面向大规模数据密集型应用的.可伸缩的分布式文件系统.GFS虽然运行在廉价的普遍硬件设备上,但是它依然了提供灾难冗余的能力,为大量 ...