CUDA编程入门
CUDA是一个并行计算框架.用于计算加速.是nvidia家的产品.广泛地应用于现在的深度学习加速.
一句话描述就是:cuda帮助我们把运算从cpu放到gpu上做,gpu多线程同时处理运算,达到加速效果.
从一个简单例子说起:
#include <iostream>
#include <math.h>
// function to add the elements of two arrays
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20; // 1M elements
float *x = new float[N];
float *y = new float[N];
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the CPU
add(N, x, y);
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
delete [] x;
delete [] y;
return 0;
}
这段代码很简单,对两个数组对应位置元素相加.数组很大,有100万个元素.
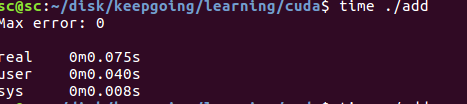
代码运行时间在0.075s.
改写代码使之运行于gpu
gpu上能够运算的函数,在cuda中我们称之为kernel.由nvcc将其编译为可以在GPU上运行的格式.
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 1>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
nvcc编译的文件的后缀为.cu
- cuda中定义kernel在函数前加上
__global声明就可以了. - 在显存上分配内存使用cudaMallocManaged
- 调用一个函数使用<<< >>>符号.比如对add的函数的调用使用`add<<<1, 1>>>(N, x, y);`,关于其中参数的意义,后文再做解释.
- 需要cudaDeviceSynchronize()让cpu等待gpu上的计算做完再执行cpu上的操作
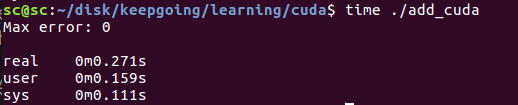
可以用nvprof做更详细的性能分析.
注意用sudo 否则可能报错.
sudo /usr/local/cuda/bin/nvprof ./add_cuda
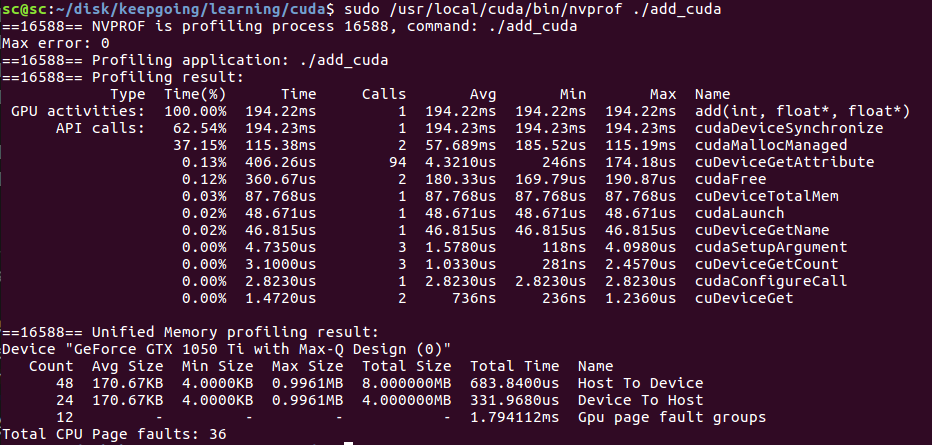
gpu上add用了194ms.
这里,我们注意到,跑在gpu反而比cpu更慢了.因为我们这段代码里`add<<<1, 1>>>(N, x, y);`并没有发挥gpu并行运算的优势,反而因为多了一些cpu与gpu的交互使得程序变慢了.
用GPU threads加速运算
重点来了
CUDA GPUS有多组Streaming Multiprocessor(SM).每个SM可以运行多个thread block. 每一个thread block有多个thread.
如下图所示:
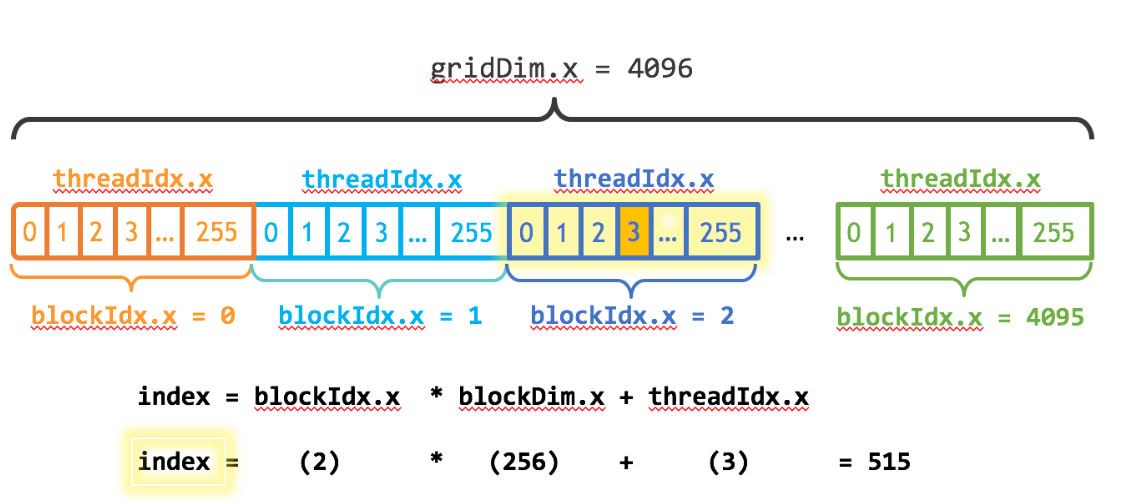
注意几个关键变量:
- blockDim.x 表明了一个thread block内含有多少个thread
- threadIdx.x 表明了当前thread在该thread blcok内的index
- blockIdx.x 表明了当前是第几个thread block
我们要做的就是把计算分配到所有的thread上去.这些thread上并行地做运算,从而达到加速的目的.
前面我们说到在cuda内调用一个函数(称之为kernel)的用法为<<<p1,p2>>>,比如`add<<<1, 1>>>(N, x, y);` 第一个参数的含义即为thread block的数量,第二个参数的含义为block内参与运算的thread数量.
现在来改写一下代码:
#include <iostream>
#include <math.h>
#include <stdio.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
printf("index=%d,stride=%d\n",index,stride);
for (int i = index; i < n; i+=stride)
{
y[i] = x[i] + y[i];
if(index == 0)
{
printf("i=%d,blockIdx.x=%d,thread.x=%d\n",i,blockIdx.x,threadIdx.x);
}
}
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 256>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
注意add的写法,我们把0,256,512...放到thread1计算,把1,257,...放到thread2计算,依次类推.调用的时候,add<<<1, 256>>>(N, x, y);表明我们只把计算分配到了thread block1内的256个thread去做.
编译这个程序(注意把代码里的printf注释掉,因为要统计程序运行时间):nvcc add_block.cu -o add_cuda_blcok -I/usr/local/cuda-9.0/include/ -L/usr/local/cuda-9.0/lib64

可以看到add的gpu时间仅仅用了2.87ms
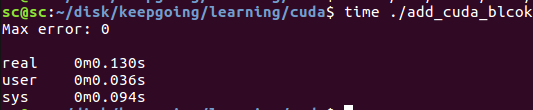
程序的整体运行时间为0.13s,主要是cudaMallocManaged,cudaDeviceSynchronize之类的操作耗费了比较多的时间.
再一次改写代码
这一次我们用更多的thread block.
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i+=stride)
{
y[i] = x[i] + y[i];
//printf("i=%d,blockIdx.x=%d\n",i,blockIdx.x);
}
}
编译:nvcc add_grid.cu -o add_cuda_grid -I/usr/local/cuda-9.0/include/ -L/usr/local/cuda-9.0/lib64
统计性能:

可以看出来,gpu上add所用的时间进一步缩小到1.8ms
参考:https://devblogs.nvidia.com/even-easier-introduction-cuda/
CUDA编程入门的更多相关文章
- CUDA编程入门,Dim3变量
dim3是NVIDIA的CUDA编程中一种自定义的整型向量类型,基于用于指定维度的uint3. 例如:dim3 grid(num1,num2,num3): dim3类型最终设置的是一个三维向量,三维参 ...
- 57 CUDA 编程入门
0 引言 由于毕设用到了Marvin,采用的是CUDA框架作为加速器,正好借此学习一下CUDA编程的一些基本知识. 各个版本的cuda的下载链接如下. https://developer.nvidia ...
- CUDA编程入门笔记
1.线程块(block)是独立执行的,在执行的过程中线程块之间互不干扰,因此它们的执行顺序是随机的 2.同一线程块中的线程可以通过访问共享内存(shared memory)或者通过同步函数__sync ...
- CUDA编程学习相关
1. CUDA编程之快速入门:https://www.cnblogs.com/skyfsm/p/9673960.html 2. CUDA编程入门极简教程:https://blog.csdn.net/x ...
- CUDA编程之快速入门
CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架构.做图像视觉领域的同学多多少少都会接触到CUDA,毕竟要做性能速度优化,CUDA是个很重要 ...
- CUDA C编程入门
最近想用cuda来加速三维重建的算法,就先入门了一下cuda. CUDA C 编程 cuda c时对c/c++进行拓展后形成的变种,兼容c/c++语法,文件类型为'.cu',编译器为nvcc.cuda ...
- CUDA编程之快速入门【转】
https://www.cnblogs.com/skyfsm/p/9673960.html CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架 ...
- CUDA从入门到精通
http://blog.csdn.net/augusdi/article/details/12833235 CUDA从入门到精通(零):写在前面 在老板的要求下.本博主从2012年上高性能计算课程開始 ...
- CUDA编程-(1)Tesla服务器Kepler架构和万年的HelloWorld
结合CUDA范例精解以及CUDA并行编程.由于正在学习CUDA,CUDA用的比较多,因此翻译一些个人认为重点的章节和句子,作为学习,程序将通过NVIDIA K40服务器得出结果.如果想通过本书进行CU ...
随机推荐
- 新大陆NB-IoT模块烧写详细过程
NB-IOT 模块板设置 1. NB-IOT 模块板如下 2.将模块上红色开关 1. 2 向下拨, 3. 4 开关向上拨,如下 3.将黑色开关向左侧拨至 M3 芯片处,如下 4.将模块上启动/下载开关 ...
- [译]HTML&CSS Lesson7: 设置背景和渐变色
背景对网站的设计有重大的影响.它有利于建立网站的整体感觉,设置分组,分配优先级,对网站的可用性也有相当大的影响. 在CSS中,元素的背景可以是一个纯色,一张图,一个渐变色或者它们的组合.在我们决定如何 ...
- 《即时消息技术剖析与实战》学习笔记11——IM系统如何保证服务高可用:流量控制和熔断机制
IM 系统的不可用主要有以下两个原因: 一是无法预测突发流量,即使进行了服务拆分.自动扩容,但流量增长过快时,服务已经不可用了: 二是业务中依赖的这些接口.资源不可用或变慢时,比如发消息可能需要依赖& ...
- disruptor 多生产者多消费者实战 四
一.创建event类 Order public class Order { private String id; private String name; private double price; ...
- C++ 标准模板库(STL)-stack
主要介绍一下C++11版本中标准模板库中栈的用法,希望可以帮到需要用的人. #include <iostream> #include <stack> #include < ...
- Python数据科学手册(1) IPython:超越Python
1.1 shell还是Notebook Jupyter Notebook 是 IPython shell 基于浏览器的图形界面,提供了一系列丰富的动态展示功能.Jupyter Notebook 不仅可 ...
- 大型Java进阶专题(四) 设计模式之工厂模式
前言 今天开始我们专题的第三课了,开始对设计模式进行讲解,本章节介绍:了解设计模式的由来,介绍设计模式能帮我们解决那些问题以及剖析工厂模式的历史由来及应用场景.本章节参考资料书籍<Sprin ...
- 微博立场检测 60分Baseline
AI研习社最近举办了一个比赛--微博立场检测,实际上就是一个NLP文本分类的比赛 Baseline-FastText 我的Baseline方法用的是pkuseg分词+FastText,最好成绩是60, ...
- 公共卫生GIS共享服务平台
1 系统详细设计 1.1 GIS共享服务管理 1.1.1 概述 GIS共享服务管理是本系统的重要组成部分,它实现了对各类地图数据.业务资源数据的集成统一管理,提供了一个平台级的管理解决方案,能够往 ...
- webStorm ctrl+L 跳转到指定行line eclipes快捷键
webStorm ctrl+L 跳转到指定行line eclipes快捷键