57 CUDA 编程入门
0 引言
由于毕设用到了Marvin,采用的是CUDA框架作为加速器,正好借此学习一下CUDA编程的一些基本知识。
各个版本的cuda的下载链接如下。
https://developer.nvidia.com/cuda-toolkit-archive
ubuntu 下cuda与cudnn安装
https://blog.csdn.net/dihuanlai9093/article/details/79253963/
1 GPU编程
参照了该博客,写得确实是非常之好,从硬件到软件,再到代码实现,由浅入深,由理论到实践,水平确实是很高,楷模!
https://www.cnblogs.com/skyfsm/p/9673960.html
(1)异构计算:现在的计算机体系架构中,要完成CUDA并行计算,单靠GPU一人之力是不能完成计算任务的,必须借助CPU来协同配合完成一次高性能的并行计算任务。一般而言,并行部分在GPU上运行,串行部分在CPU运行,这就是异构计算。具体一点,异构计算的意思就是不同体系结构的处理器相互协作完成计算任务。CPU负责总体的程序流程,而GPU负责具体的计算任务,当GPU各个线程完成计算任务后,我们就将GPU那边计算得到的结果拷贝到CPU端,完成一次计算任务。
(2)cuda编程模型:线程模型阵列及线程号的计算
CUDA C通过kernels这样一种方式,实现对一般c的扩展。当cuda 中的kernel被调用时,它将被N个不同的threads调用N次,而非cpu编程中,每个非递归function只被调用一次。GPU CUDA的这种编程模型是基于其物理上的超多核心架构设计的,符合其并行运算的特点。CUDA的计算单元结构如下。
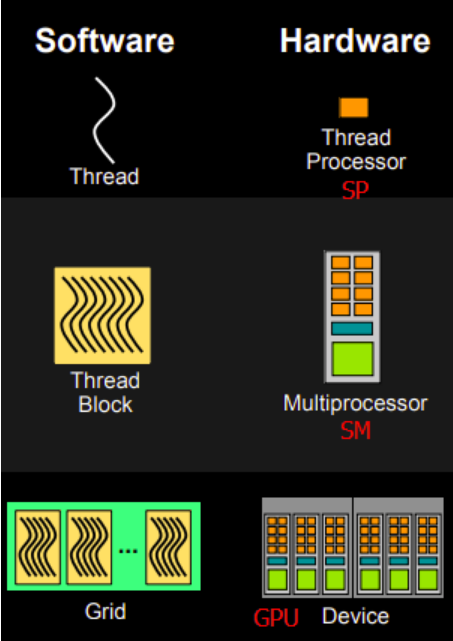

1、针对kernel的每次计算,定义一个grid,该grid包含若干个Block,每个Block又包含若干个threads,通过threadIdx访问这些Thread的索引号,即可调用这些单元。
2、threadIdx为三维向量,因此,每个block可以被定义为一维、二维或者三维向量,分别通过threadIdx.x, threadIdx.y, threadIdx.z来访问。 当前,每个block中可以包含至多1024个threads.
3、每个grid中的blocks可以组织成一维、二维或者三维的形式,每个grid中的blocks的数量决定于处理的数据的大小,或系统处理器的数量,访问grid中的block的方式是 blockIdx, 这是一个三维的变量,而block的维度通过blockDim变量来访问。
4、grid中blocks的数量以及block中threads的数量通过<<< blocks_number , threads_number>>>来定义,其中,blocks_number/threads_number的数据类型为int 或 dim3, 二维形式的可用dim3来存放,比如下面的例子。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(, );
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
(3)我的GPU的硬件信息
使用GPU device 0: GeForce GTX 1050
设备全局内存总量: 4041MB
SM的数量:5
每个线程块的共享内存大小:48 KB
每个线程块的最大线程数:1024
设备上一个线程块(Block)中可用的32位寄存器数量: 65536
每个EM的最大线程数:2048
每个EM的最大线程束数:64
设备上多处理器的数量: 5
2 linux + VSCode配置CUDA开发环境
(1)c_cpp_properties.json,其中的“includePath”相当于visual studio的 c/c++ -> 常规 -> 附加包含目录中添加的路径,可以避免代码中出现不影响执行的红色波浪线
{
"configurations": [
{
"name": "Linux",
"includePath": [
"${workspaceFolder}/**",
"${workspaceFolder}",
"/usr/include",
"/usr/include/x86_64-linux-gnu/sys",
"usr/local/cuda/include"
],
"defines": [],
"browse":{
"path":[
"/usr/include"
]
},
"compilerPath": "/usr/local/cuda/bin",
"cStandard": "c11",
"cppStandard": "c++17",
"intelliSenseMode": "gcc-x64"
}
],
"version":
}
(2)tasks.json,主要修改了“comman”,这里cuda编译用到的编译器是nvcc,同时还需要在nvcc编译指令中加入头文件地址和静态库lib文件地址。具体的编译任务中,根据错误提示添加对应的.so文件路径即可
{
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
"version": "2.0.0",
"tasks":[ // 可以有多个参数
{
"label": "build", // 编译任务名
"type": "shell", // 编译任务的类型,通常为shell/process类型
"command": "nvcc", // 编译命令
"args":[
"-g", // 该参数使编译器在编译的时候产生调试信息
"${workspaceFolder}/${fileBasename}", // 被编译文件,通常为.cpp/.c/.cc文件等
"-o", // 生成指定名称的可执行文件
"${workspaceFolder}/${fileBasenameNoExtension}",
// include path指令
"-I", "/usr/local/cuda/include",
// lib 库文件地址
"-L", "/usr/local/cuda/lib64",
"-l", "cudart",
"-l", "cublas",
"-l", "cudnn",
"-l", "curand",
"-D_MWAITXINTRIN_H_INCLUDED"
],
"group": {
"kind": "build",
"isDefault": true
}
},
{
"label": "cmakebuild",
"type": "shell",
"command": "cd build && cmake ../ && make",
"args": []
}
]
}
(3)launch.json,基本保持不变即可
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "(gdb) Launch", // 强制:就一个名字而已,但是是必须要有的
"type": "cppdbg",
"request": "launch", // 强制:launch/attach
"program": "${workspaceFolder}/${fileBasenameNoExtension}", // 可执行文件的路径
"miDebuggerPath": "/usr/bin/gdb", // 调试器的位置
"preLaunchTask":"build", // 调试前编译任务名称
"args": [], // 调试参数
"stopAtEntry": false,
"cwd": "${workspaceFolder}", // 当前工作目录
"environment": [], // 当前项目环境变量
"externalConsole": true,
"MIMode": "gdb", // 调试器模式/类型
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
]
}
]
}
3 cuda-gdb调试
https://blog.csdn.net/hxh1994/article/details/49621759
$ nvcc -g -G compute_matrix.cu -arch sm_50 -o compute_matrix
4 关键词及变量意义解析
57 CUDA 编程入门的更多相关文章
- CUDA编程入门,Dim3变量
dim3是NVIDIA的CUDA编程中一种自定义的整型向量类型,基于用于指定维度的uint3. 例如:dim3 grid(num1,num2,num3): dim3类型最终设置的是一个三维向量,三维参 ...
- CUDA编程入门笔记
1.线程块(block)是独立执行的,在执行的过程中线程块之间互不干扰,因此它们的执行顺序是随机的 2.同一线程块中的线程可以通过访问共享内存(shared memory)或者通过同步函数__sync ...
- CUDA编程入门
CUDA是一个并行计算框架.用于计算加速.是nvidia家的产品.广泛地应用于现在的深度学习加速. 一句话描述就是:cuda帮助我们把运算从cpu放到gpu上做,gpu多线程同时处理运算,达到加速效果 ...
- CUDA编程学习相关
1. CUDA编程之快速入门:https://www.cnblogs.com/skyfsm/p/9673960.html 2. CUDA编程入门极简教程:https://blog.csdn.net/x ...
- CUDA编程之快速入门
CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架构.做图像视觉领域的同学多多少少都会接触到CUDA,毕竟要做性能速度优化,CUDA是个很重要 ...
- CUDA C编程入门
最近想用cuda来加速三维重建的算法,就先入门了一下cuda. CUDA C 编程 cuda c时对c/c++进行拓展后形成的变种,兼容c/c++语法,文件类型为'.cu',编译器为nvcc.cuda ...
- CUDA编程之快速入门【转】
https://www.cnblogs.com/skyfsm/p/9673960.html CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架 ...
- 【浅墨著作】《OpenCV3编程入门》内容简单介绍&勘误&配套源码下载
经过近一年的沉淀和总结,<OpenCV3编程入门>一书最终和大家见面了. 近期有为数不少的小伙伴们发邮件给浅墨建议最好在博客里面贴出这本书的文件夹,方便大家更好的了解这本书的内容.事实上近 ...
- 转载自~浮云比翼:Step by Step:Linux C多线程编程入门(基本API及多线程的同步与互斥)
Step by Step:Linux C多线程编程入门(基本API及多线程的同步与互斥) 介绍:什么是线程,线程的优点是什么 线程在Unix系统下,通常被称为轻量级的进程,线程虽然不是进程,但却可 ...
随机推荐
- ansible-继续普通用户权限运行
ansible 远程以普通用户执行命令 1. ansible 10.0.0.1 -m raw -a "date" -u www 2.在ansible的主机配置文件中指定ssh_ ...
- 洛谷P1935 [国家集训队]圈地计划
题目大意: 有个\(n*m\)的网格图 每个点可以选择\(A\),获得\(A[i][j]\)或选\(B\)获得\(B[i][j]\)的收益 相邻点有\(k\)个不同可以获得\(C[i][j]\)的收益 ...
- rest_framework框架实现之(认证)
一认证 我们可以想想,我们要访问一个页面,需不需要对其进行认证,希望进入页面的时候看到哪些内容,一般是根据用户的不同而不同 首先,我们先设计一个表,如何知道对方通过了验证,我们可以考虑给其加一个tok ...
- 快速给一个表插入数据 用bulk_create()
- 学习android文档
follow lesson, 一. 创建一helloworld,运行.fragment_main.xml里默认是relativeLayout和Textview 二. 创建第一个图形界面,主要是说fra ...
- iOS 如何计算UIWebView的ContentSize
首选要等UIWebView加载内容后,然后在它的回调方法里将webview的高度Height设置足够小,就设置为1吧,因为这样才能用 sizeThatFits才能计算出webview得内容大小 - ( ...
- msf反弹shell
今天回顾了一下msf反弹shell的操作,在这里做一下记录和分享.( ̄︶ ̄)↗ 反弹shell的两种方法 第一种Msfvenom实例: 1.msfconsole #启动msf 2.msfvenom - ...
- react map循环数据 死循环
项目条件:react es6 antidesign 已在commonState中获取到list,但是在循环map填充DOM的时候陷入死循环. 原因:因为是子组件 ,在父组件请求数据的时候 有个时差过程 ...
- Centos 能ping通域名和公网ip但是网站不能够打开,服务器拒绝了请求。打开80端口解决。
博客搬迁,给你带来的不便,敬请谅解! http://www.suanliutudousi.com/2017/10/29/centos-%E8%83%BDping%E9%80%9A%E5%9F%9F%E ...
- JDK8新特性之函数式接口
什么是函数式接口 先来看看传统的创建线程是怎么写的 Thread t1 = new Thread(new Runnable() { @Override public void run() { Syst ...