Python爬虫连载2-reponse\parse简介
一、reponse解析
urlopen的返回对象
(1)geturl:返回网页地址
(2)info:请求反馈对象的meta信息
(3)getcode:返回的http code
from urllib import request
import chardet
"""
解析reponse
"""
if __name__ == "__main__":
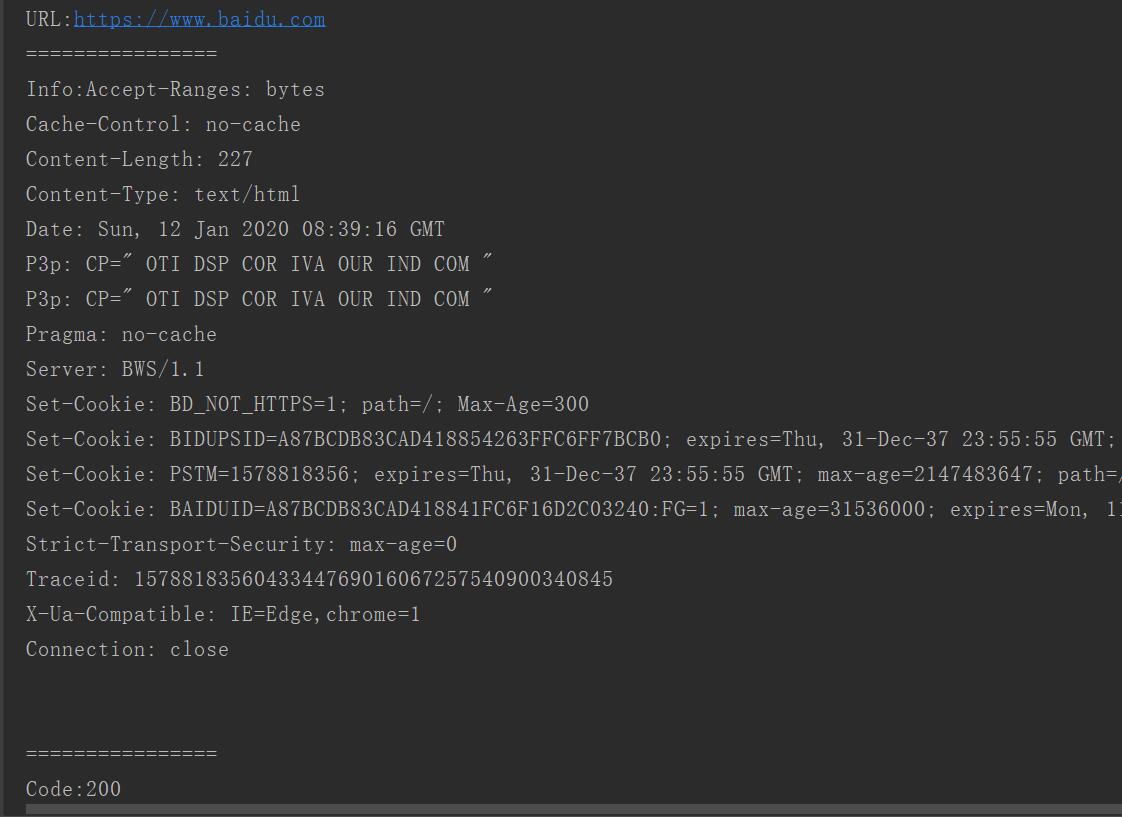
url = "https://www.baidu.com"
rsp = request.urlopen(url)
print("URL:{0}".format(rsp.geturl()))#网页地址
print("================")
print("Info:{0}".format(rsp.info()))#网页头信息
print("================")
print("Code:{0}".format(rsp.getcode()))#请求后返回的状态码
二、parse
1.request.date的使用
访问网络的两种方式
(1)get(2)post
2.url.parse用来解析url
from urllib import request,parse
import chardet
"""
解析reponse
"""
if __name__ == "__main__":
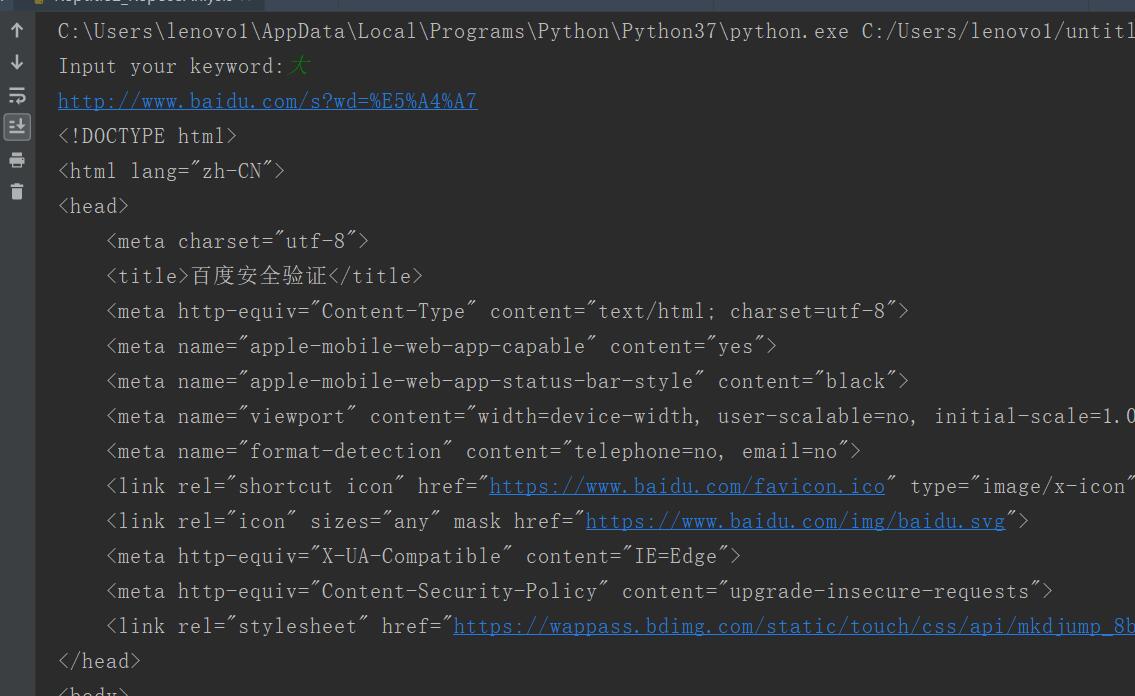
url = "http://www.baidu.com/s?"
wd = input("Input your keyword:")
#要想使用data,需要使用字典结构
qs = {
"wd":wd
}
#转换url编码
qs = parse.urlencode(qs)#对关键字进行编码
fullurl = url + qs#百度搜索传入的地址是基础地址加上关键字的编码形式
print(fullurl)
rsp = request.urlopen(fullurl)
html = rsp.read()
html = html.decode()#解码
#使用get取值保证不会出错
print(html)
三、源码
Reptile2_ReposeAnlysis.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile2_ReposeAnlysis.py
2.CSDN:https://blog.csdn.net/weixin_44630050(心悦君兮君不知-睿)
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料
Python爬虫连载2-reponse\parse简介的更多相关文章
- Python爬虫连载1-urllib.request和chardet包使用方式
一.参考资料 1.<Python网络数据采集>图灵工业出版社 2.<精通Python爬虫框架Scrapy>人民邮电出版社 3.[Scrapy官方教程](http://scrap ...
- Python爬虫连载10-Requests模块、Proxy代理
一.Request模块 1.HTTP for Humans,更简洁更友好 2.继承了urllib所有的特征 3.底层使用的是urllib3 4.开源地址:https://github.com/req ...
- Python爬虫连载9-JS加密之“盐”、ajax请求
一.JS加密之“盐” 1.salt属性“盐":多用于密码学,比如我们的银行卡是六位密码,但是实际上在银行的系统里,我们输入密码后,会给原始的密码添加若干字符,形成更加难以破解的密码.这个过 ...
- Python爬虫连载8-JS加密(一)
一.JS加密 1.有的反爬虫策略采用js对需要传输的数据进行加密处理. 2.经过加密,传输的就是密文 3.加密函数或者过程一定是在浏览器完成,也就是一定会把代码(js代码)暴露给使用者 4.通多阅读加 ...
- Python爬虫连载7-cookie的保存与读取、SSL讲解
一.cookie的保存与读取 1.cookie的保存-FileCookie.Jar from urllib import request,parse from http import cookieja ...
- Python爬虫入门:Urllib parse库使用详解(二)
文字转载:https://www.jianshu.com/p/e4a9e64082ef,转载内容仅供学习 如有侵权,请联系删除 获取url参数 urlparse 和 parse_qs ParseRes ...
- Python爬虫连载3-Post解析、Request类
一.访问网络的两种方法 1.get:利用参数给服务器传递信息:参数为dict,然后parse解码 2.post:一般向服务器传递参数使用:post是把信息自动加密处理:如果想要使用post信息,需要使 ...
- Python爬虫连载6-cookie深入使用实例化实现自动登录
一.使用cookie登录 1.直接把cookie复制下去,然后手动放到请求头 2.http模块包含一些关于cookie的模块,通过他们我们可以自动使用cookie (1)cookieJar 管理存储c ...
- Python爬虫连载5-Proxy、Cookie解析
一.ProxyHandler处理(代理服务器) 1.使用代理IP,是爬虫的常用手段 2.获取代理服务器的地址: www.xicidaili.com www.goubanjia.com 3.代理用来隐藏 ...
随机推荐
- 微服务中springboot启动问题
log4j:WARN No appenders could be found for logger (org.springframework.web.context.support.StandardS ...
- 洛谷 P3133 [USACO16JAN]Radio Contact G
题目传送门 解题思路: f[i][j]表示FJ走了i步,Bessie走了j步的最小消耗值.方程比较好推. 横纵坐标要搞清楚,因为这东西WA了半小时. AC代码: #include<iostrea ...
- 19 03 13 关于 scrapy 框架的 对环球网的整体爬取(存储于 mongodb 数据库里)
关于 spinder 在这个框架里面 和不用数据库 相同 # -*- coding: utf-8 -*- import scrapy from yang_guan.items import ...
- 网卡绑定多个ip
现在我的树莓派上的wlan0的IP是192.168.31.237,之前通过双绞线连接时候eth0的ip是192.168.31.50 . 我就想啊,能不能把wlan0的ip设置成50.......... ...
- Lombok认知
Lombok的简介 Lombok是一款Java开发插件,公司项目到处使用,整体效果很棒,代码更干净.Java开发人员可以节省出重复构建,诸如hashCode和equals这样的方法以及各种业务对象模型 ...
- SpringMVC:提交日期类型报400错误解决方法
方法1:可以使用@ControllerAdvice增强Controller @ControllerAdvice public class BaseControllerAdvice { // 初始化绑定 ...
- mysql安装--window版
一.下载 二.解压 三.配置 四.环境变量 五.安装MySQL服务 六.启动MySQL服务 七.停止MySQL 一.下载 第一步:打开网址,https://www.mysql.com,点击downlo ...
- 面向对象-main函数
面向对象-main函数 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写main函数测试代码 /** * * @author 尹正杰 * */ public class ...
- Java工程师面试题
1. J2EE 是什么?它包括哪些技术?解答:从整体上讲,J2EE 是使用 Java 技术开发企业级应用的工业标准,它是 Java 技术不断适应和促进企业级应用过程中的产物.适用于企业级应用的 J2E ...
- 当DIV内出现滚动条,fixed实效怎么办?
sticky 盒位置根据正常流计算(这称为正常流动中的位置),然后相对于该元素在流中的 flow root(BFC)和 containing block(最近的块级祖先元素)定位.在所有情况下( ...