cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning
讲课嘉宾是Song Han,个人主页 Stanford:https://stanford.edu/~songhan/;MIT:https://mtlsites.mit.edu/songhan/。
1. 深度学习面临的问题:
1)模型越来越大,很难在移动端部署,也很难网络更新。
2)训练时间越来越长,限制了研究人员的产量。
3)耗能太多,硬件成本昂贵。
解决的方法:联合设计算法和硬件。
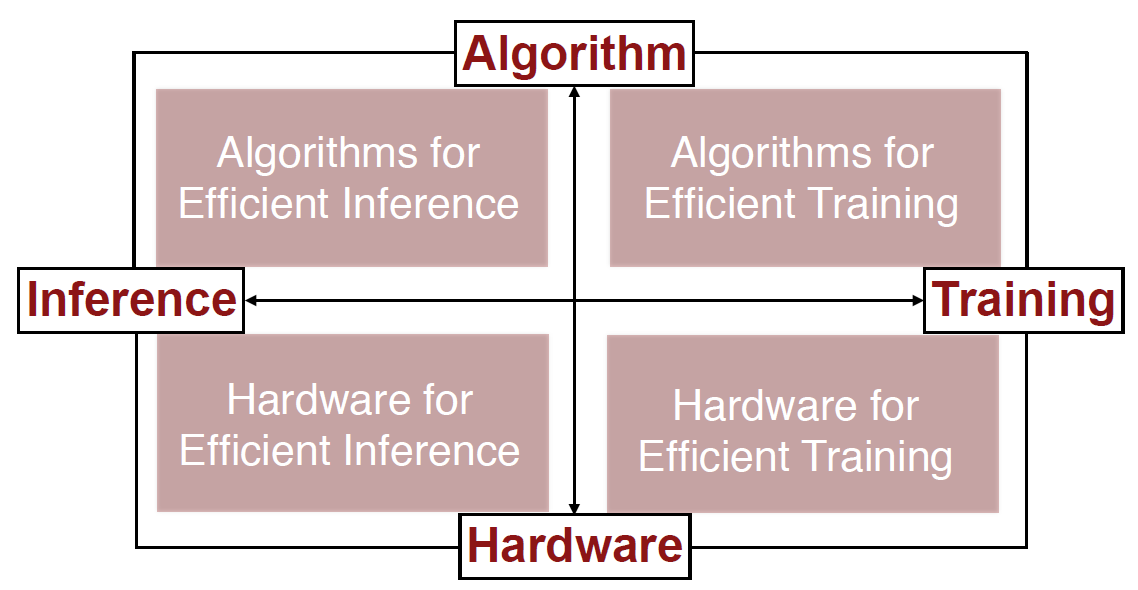
计算硬件可以分为通用和专用两大类。通用硬件又可以分为CPU和GPU。专用硬件可以分为(FPGA和ASIC,ASIC更高效,谷歌的TPU就是ASIC)。
2. Algorithms for Efficient Inference
1)Pruning,修剪掉不那么重要的神经元和连接。第一步,用原始的网络训练;第二步,修剪掉一部分网络;第三步,继续训练剩下的网络。不断重复第二步和第三步。在不损失精度的情况下,网络可以缩小到原来的十分之一(继续缩小精度会变差)。
2)Weight Sharing,权重并不需要那么精确,可以把一些近似的权重看成一样的(比如2.09、2.12、1.92、1.87可以全部看成2)。也是在原始训练基础上,用某种方式简化权重,然后不断训练调整简化权重的方式。在不损失精度的情况下,网络可以缩小到原来的八分之一。
前两种方法可以结合使用,网络可以缩小到原来的百分之几。有个名字Deep Compression。
3)Quantization,数据类型。TPU的设计主要就是优化这一部分。
4)Low Rank Approximation,把大网络拆成一系列小网络。
5)Binary(二元)/Ternary(三元) Net,很疯狂地把权重离散化成(-1,0,1)三种。
6)Winograd Transformation,一种更高效的求卷积的做法。
3. Hardware for Efficient Inference
这个方向各种硬件的共同目的是减少内存的读取(minimize memory access)。硬件需要能用压缩过的神经网络做预测。
EIE(Efficient Inference Engine)(Han et al. ISCA 2016):稀疏权重(扔掉为0的权重)、稀疏激活值(扔掉为0的激活值)、Weight Sharing(4-bit)。
4. Algorithms for Efficient Training
1)Parallelization。CPU按照摩尔定律发展,这些年单线程的性能已经提高的非常缓慢,而核的数量在不断提高。

2)Mixed Precision with FP16 and FP32,正常是用32位计算,但计算权重更新的时候用16位。
3)Model Distillation,用训练的很好的大网络的“软结果”(soft targets)作为标签提供给压缩过的小网络训练。这是Hinton的一篇论文提出的,里面解释了为什么软结果比ground truth更好。
4)DSD(Dense-Sparse-Dense Training),先对原始的稠密的网络做Pruning,训练稀疏的网络后,再Re-Dense出稠密的网络。Han说这是先学习树的枝干,再学习叶子。相比原来的稠密网络,Re-Dense出的精度更高。
5. Hardware for Efficient Training
Computation和Memory bandwidth是影响整体性能的两个因素。
Han对比Nvidia Pascal和Volta,猛吹了一波Volta。。。Volta有120个Tensor Core,非常擅长矩阵运算。
cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning的更多相关文章
- cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning 听课笔记
1. 深度学习面临的问题: 1)模型越来越大,很难在移动端部署,也很难网络更新. 2)训练时间越来越长,限制了研究人员的产量. 3)耗能太多,硬件成本昂贵. 解决的方法:联合设计算法和硬件. 计算硬件 ...
- 韩松毕业论文笔记-第六章-EFFICIENT METHODS AND HARDWARE FOR DEEP LEARNING
难得跟了一次热点,从看到论文到现在已经过了快三周了,又安排了其他方向,觉得再不写又像之前读过的N多篇一样被遗忘在角落,还是先写吧,虽然有些地方还没琢磨透,但是paper总是这样吧,毕竟没有亲手实现一下 ...
- cs231n spring 2017 lecture7 Training Neural Networks II 听课笔记
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture7 Training Neural Networks II
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture13 Generative Models 听课笔记
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
- cs231n spring 2017 lecture11 Detection and Segmentation 听课笔记
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种"Unpooling"." ...
- cs231n spring 2017 lecture9 CNN Architectures 听课笔记
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 Python/Numpy基础 (1)
本文使根据CS231n的讲义整理而成(http://cs231n.github.io/python-numpy-tutorial/),以下内容基于Python3. 1. 基本数据类型:可以用 prin ...
- cs231n spring 2017 lecture13 Generative Models
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
随机推荐
- 35. docker swarm dockerStack 部署 投票应用
1. 编写 docker-compose.yml # docker-compose.yml version: "3" services: redis: image: redis:a ...
- 85.常用的返回QuerySet对象的方法使用详解:defer,only
defer(),only(): 这两个方法都会返回一个"QuerySet"对象,并且这个"QuerySet"中装的是模型,不像values()和values_l ...
- Python列表中去重的多种方法
怎么快速的对列表进行去重呢,去重之后原来的顺序会不会改变呢? 去重之后顺序会改变 set去重 列表去重改变原列表的顺序了 l1 = [1,4,4,2,3,4,5,6,1] l2 = list(set( ...
- 详解Cisco ACS AAA认证-1(转)
转自:http://www.360doc.com/content/12/0611/17/8797027_217495523.shtml作者:luobo2012 近来,有些同学会问到关于AAA认证的问题 ...
- flutter实现promise中resolve(RxJava中emiter.onSucess("result"))功能
BehaviorSubject openCameraController = BehaviorSubject(); BridgeChannel _openCamera() { print('- - - ...
- 常用DOS命令(1) color,dir,copy,shutdown,mkdir(md),rmdir(rd),attrib,cd
1. color color [attr] 设置默认的控制台前景和背景颜色. attr 指定控制台输出的颜色属性.颜色属性由两个十六进制数字指定 -- 第一个对应于背景,第二个对应于前 ...
- 实现迭代器(\_\_next\_\_和\_\_iter\_\_)
目录 实现迭代器(__next__和__iter__) 一.简单示例 二.StopIteration异常版 三.模拟range 四.斐波那契数列 实现迭代器(__next__和__iter__) 一. ...
- mongodb 批量改变某一列类型 比如 String改为double,insert into select 批量插入 批量修改
//type:2代表String 1.String变Double db.集合.find({"列":{$type:2}}).forEach(function(x){ x.列=pars ...
- Java连载72-String类详解、多个构造方法
一.String类 1.String类是不可以变类,也就是说String对象声明后 2.java.lang.String:是字符串类型 (1)字符串一旦创建不可再改变,“abc”字符串对象一旦创建,不 ...
- Gson使用指南(一)
注:此系列基于Gson 2.4. 一.Gson的基本用法 Gson提供了fromJson() 和toJson() 两个直接用于解析和生成的方法,前者实现反序列化,后者实现了序列化.同时每个方法都提供了 ...