DNN论文分享 - Item2vec: Neural Item Embedding for Collaborative Filtering
前置点评: 这篇文章比较朴素,创新性不高,基本是参照了google的word2vec方法,应用到推荐场景的i2i相似度计算中,但实际效果看还有有提升的。主要做法是把item视为word,用户的行为序列视为一个集合,item间的共现为正样本,并按照item的频率分布进行负样本采样,缺点是相似度的计算还只是利用到了item共现信息,1).忽略了user行为序列信息; 2).没有建模用户对不同item的喜欢程度高低。
-------------------------------------------------
0 背景:
推荐系统中,传统的CF算法都是利用 item2item 关系计算商品间相似性。i2i数据在业界的推荐系统中起着非常重要的作用。传统的i2i的主要计算方法分两类,memory-based和model-based。
作者受nlp中运用embedding算法学习word的latent representation的启发,特别是参考了google发布的的word2vec(Skip-gram with Negative Sampling,SGNS),利用item-based CF 学习item在低维 latent space的 embedding representation,优化i2i的计算。
-------------------------------------------------
1 回顾下google的word2vec:
自然语言处理中的neural embedding尝试把 words and phrases 映射到一个低维语义和句法的向量空间中。
Skip-gram的模型架构:
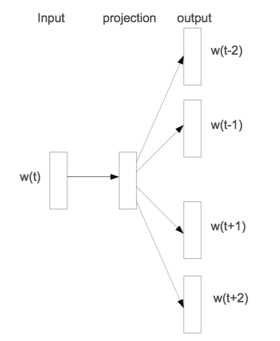
Skip-gram是利用当前词预测其上下文词。给定一个训练序列,
,...,
,模型的目标函数是最大化平均的log概率:
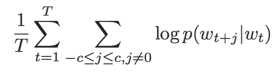
目标函数中c中context的大小。c越大,训练样本也就越大,准确率也越高,同时训练时间也会变长。
在skip-gram中, 利用softmax函数定义如下:
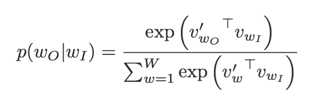
W是整个语料库的大小。上式的梯度的计算量正比如W,W通常非常大,直接计算上式是不现实的。为了解决这个问题,google提出了两个方法,一个是hierarchical softmax,另一个方法是negative sample。negative sample的思想本身源自于对Noise Contrastive Estimation的一个简化,具体的,把目标函数修正为:
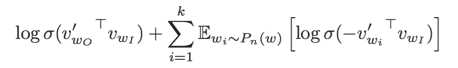
是噪声分布 ( noise distribution )。即训练目标是使用Logistic regression区分出目标词和噪音词。具体的Pn(w)方面有些trick,google使用的是unigram的3/4方,即
,好于unigram,uniform distribution。
另外,由于自然语言中很多高频词出现频率极高,但包含的信息量非常小(如'is' 'a' 'the')。为了balance低频词和高频词,利用简单的概率丢弃词:
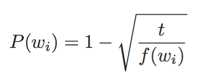
其中是
的词频,t的确定比较trick,启发式获得。实际中t大约在
附近。
-------------------------------------------------
2 Item2vec算法原理:
Item2vec中把用户浏览的商品集合等价于word2vec中的word的序列,即句子(忽略了商品序列空间信息spatial information) 。出现在同一个集合的商品对视为 positive。对于集合目标函数:
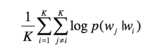
同word2vec,利用负采样,将定义为:
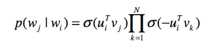
subsample的方式也是同word2vec:
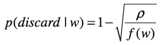
最终,利用SGD方法学习的目标函数max,得到每个商品的embedding representation,商品之间两两计算cosine相似度即为商品的相似度。
-------------------------------------------------
3 Item2vec效果:
对比的baseline方法是基于SVD方法的用户embedding得到的相似度,SVD分解的维度和item2vec的向量维度都取40,详细见paper。数据是应用在music领域的,作者利用web上音乐人的类别进行聚类,同一个颜色的节点表示相同类型的音乐人,结果对比如下:
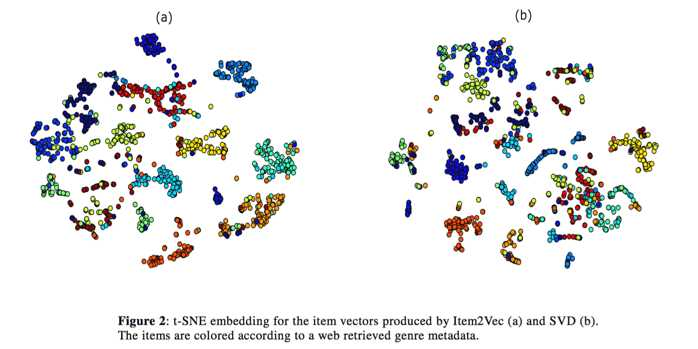
图a是item2vec的聚合效果,图b是SVD分解的聚合效果,看起来item2vec的聚合效果更好些。
原文https://arxiv.org/pdf/1603.04259v2.pdf
参考文献:
[1] Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems 2013 (pp. 3111-3119).
DNN论文分享 - Item2vec: Neural Item Embedding for Collaborative Filtering的更多相关文章
- [论文分享] DHP: Differentiable Meta Pruning via HyperNetworks
[论文分享] DHP: Differentiable Meta Pruning via HyperNetworks authors: Yawei Li1, Shuhang Gu, etc. comme ...
- 论文分享NO.1(by_xiaojian)
论文分享第一期-2019.03.14: 1. Non-local Neural Networks 2018 CVPR的论文 2. Self-Attention Generative Adversar ...
- 论文笔记 : NCF( Neural Collaborative Filtering)
ABSTRACT 主要点为用MLP来替换传统CF算法中的内积操作来表示用户和物品之间的交互关系. INTRODUCTION NeuCF设计了一个基于神经网络结构的CF模型.文章使用的数据为隐式数据,想 ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文分享NO.4(by_xiaojian)
论文分享第四期-2019.04.16 Residual Attention Network for Image Classification,CVPR 2017,RAN 核心:将注意力机制与ResNe ...
- 论文分享NO.3(by_xiaojian)
论文分享第三期-2019.03.29 Fully convolutional networks for semantic segmentation,CVPR 2015,FCN 一.全连接层与全局平均池 ...
- 论文分享NO.2(by_xiaojian)
论文分享第二期-2019.03.26 NIPS2015,Spatial Transformer Networks,STN,空间变换网络
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
- [阿里DIN] 从论文源码学习 之 embedding层如何自动更新
[阿里DIN] 从论文源码学习 之 embedding层如何自动更新 目录 [阿里DIN] 从论文源码学习 之 embedding层如何自动更新 0x00 摘要 0x01 DIN源码 1.1 问题 1 ...
随机推荐
- shell脚本删除N天前的目录-----附linux和mac上date命令的不同
背景: 每日构建的东西.按日期放到不同的目录里. 现在天的构建放到2015-06-01里,明天的就放到2015-06-02里,依次类推.时间久了.须要一个脚本删除N天前的目录.(本例中N=7.即删除一 ...
- Simple prefix compression
题目 看懂题目的意思 直接模拟就能够了 好像不用递归就能够了. . 尽管这周学的是递归 还是偷了一些懒 直接模拟 在说这个题目的意思 本来能够写的非常清楚的下标 题目非要把两个字符串的表示方法写的这 ...
- 配置SQL Server on Linux(1)
1. 背景 SQL Server一般是在安装过程中进行相关的配置,安装完成之后,再去修改有一些配置就比较麻烦,比如更改SQL Server实例级别的排序规则.但在Linux下,安装过程并没有很多可以配 ...
- iBATIS使用$和#的一些理解
我们在使用iBATIS时会经常用到#这个符号. 比如: sql 代码 select * from member where id =#id# 然后,我们会在程序中给id这个变量传递一个值,iBATIS ...
- MVC+EF 入门教程(一)
一.前言 本人小白,写这篇博客是为了记录今天一天所学的知识,可能表达不是那么的准确和清楚,欢迎在留言区写下您的建议,欢迎纠错.希望这篇文章对你有所帮助学习 .Net MVC有所帮助.废话不多说了,我们 ...
- ios应用版本号设置规则
版本号的格式:v<主版本号>.<副版本号>.<发布号> 版本号的初始值:v1.0.0 管理规则: 主版本号(Major version) 1. 产品的主体构件进行 ...
- iOS OC应用异常捕获,崩溃退出前返回信息给后台
第三方的了,有友盟,腾讯的bugly 查了一下网上类似的代码很多,在借鉴前辈的代码后,组合了一下: 1.捕获异常信息 2.获得当前日期,版本,系统 3.获得出bug的视图控制器转为字符串 4.将前3条 ...
- iOS 通过UIControl,自定义控件
如:自定义一个可以点击的 图文 #import <UIKit/UIKit.h> @interface UD_Button : UIControl @property(nonatomic,s ...
- boost::algorithm(字符串算法库)
没什么说的,需要 #include<boost/algorithm/string.hpp> 1.大小写转换 std::string s("test string"); ...
- ListView用法总结C#
ListView是个较为复杂的控件 网上教程写的很乱,C#中文资料太匮乏了,小白叔叔觉得有必要自己出一份了. http://blog.sina.com.cn/s/blog_43eb83b901 ...