走近RDD
RDD(Resilient Distributed Datasets)弹性分布式数据集。RDD可以看成是一个简单的"数组",对其进行操作也只需要调用有限的"数组"中的方法即可,但它与一般数组的区别在于:RDD是分布式存储,可以跟好的利用现有的云数据平台,并在内存中进行。此处的弹性指的是数据的存储方式,及数据在节点中进行存储的时候,既可以使用内存也可以使用磁盘。此外,RDD还具有很强的容错性,在spark运行计算的过程中,不会因为某个节点错误而使得整个任务失败;不通节点中并发运行的数据,如果在某个节点发生错误时,RDD会自动将其在不同的节点中重试。
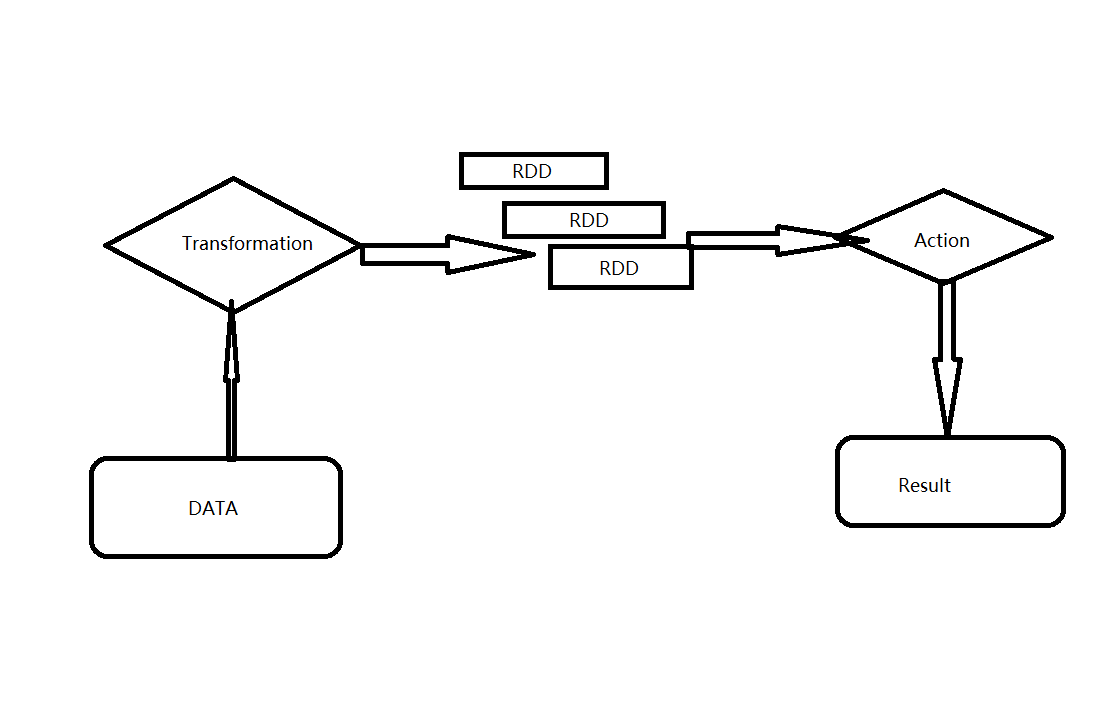
RDD一大特性是延迟计算,即一个完整的RDD运行任务被分成2部分:Transformation和Action。
Transformation用于对RDD的创建。在spark中,RDD只能使用Transformation来创建,同时Transformation还提供了大量的操作方法。RDD还可以利用Transformation来生成新的RDD,这样可以在有限的内存空间中生成竟可能多的数据对象。无论发生了多少次Transformation,此时,在RDD中真正数据计算运行的操作Action都没真正的开始运行。

Action是数据的执行部分,其也提供了大量的方法去执行数据的计算操作部分。

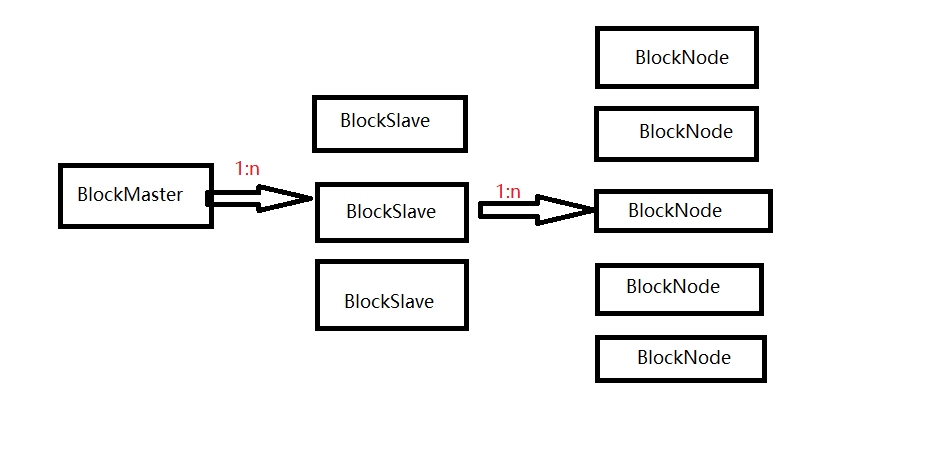
RDD可以将其看成一个分布在不同节点中的分布式数据集,并将数据以数据块(Block)的形式存储在各个节点的计算机中。每个BlockMaster管理着若干个BlockSlave,而每个BlockSlave又管理着若干个BlockNode。当BlockSlave获得了每个Node节点的地址,又会反向向BlockMaster注册每个Node的基本信息,这样就形成了分层管理。
RDD依赖

import org.apache.spark.{SparkConf, SparkContext}
object test {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("test")
val sc=new SparkContext(conf)
val arr=sc.parallelize(Array(,,,,,,,))//parallelize将内存数据读入Spark系统中,作为整体数据集
val result=arr.aggregate()(math.max(_,_),_+_)//_+_ 对传递的第一个方法的结果集进行进一步处理
println(result)
}
}
结果为8
import org.apache.spark.{SparkConf, SparkContext}
object test {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("test")
val sc=new SparkContext(conf)
val arr=sc.parallelize(Array("abd","hello world","hello sb"))//parallelize将内存数据读入Spark系统中,作为整体数据集
val result=arr.aggregate("")((value,word)=>value+word,_+_)//_+_ 对传递的第一个方法的结果集进行进一步处理
println(result)
}
}
结果为abdhello worldhello sb
3、cache是将数据内容计算并保存在计算节点的内存中
4、cartesion是用于对不同的数组进行笛卡尔操作,要求是数组的长度必须相同
import org.apache.spark.{SparkConf, SparkContext}
object test {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("test")
val sc=new SparkContext(conf)
val arr1=sc.parallelize(Array(,,,))//parallelize将内存数据读入Spark系统中,作为整体数据集
val arr2=sc.parallelize(Array(,,,))
val res=arr1.cartesian(arr2)
res.foreach(print)
}
}
结果:(1,4)(1,3)(1,2)(1,1)(2,4)(2,3)(2,2)(2,1)(3,4)(3,3)(3,2)(3,1)(4,4)(4,3)(4,2)(4,1)
5、Coalesce是将已经存储的数据重新分片后再进行存储(repartition与Coalesce类似)
import org.apache.spark.{SparkConf, SparkContext}
object test {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("test")
val sc=new SparkContext(conf)
val arr1=sc.parallelize(Array(,,,,,))//parallelize将内存数据读入Spark系统中,作为整体数据集
val arr2=arr1.coalesce(,true)
val res1=arr1.aggregate()(math.max(_,_),_+_)
println(res1)
val res2=arr2.aggregate()(math.max(_,_),_+_)
println(res2)
}
}
结果为6 11
6、countByValue是计算数据集中某个数据出现的个数,并将其以map的形式返回
7、countByKey是计算数据集中元数据键值对key出现的个数
import org.apache.spark.{SparkConf, SparkContext}
object test {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("test")
val sc=new SparkContext(conf)
val arr1=sc.parallelize(Array((,"a"),(,'b'),(,'c'),(,'d'),(,'a')))//parallelize将内存数据读入Spark系统中,作为整体数据集
val res1=arr1.countByValue()
res1.foreach(println)
val res2=arr1.countByKey()
res2.foreach(println)
}
}
//结果:((1,c),1)
((,a),)
((,a),)
((,d),)
((,b),)
(,)
(,)
8、filter是对数据集进行过滤
9、flatMap是对RDD中的数据进行整体操作的一个特殊方法,其在定义时就是针对数据集进行操作
10、map可以对RDD中的数据集进行逐个操作,其与flatmap不同得是,flatmap是将数据集中的数据作为一个整体去处理,之后再对其中的数据做计算,而map则直接对数据集中的数据做单独的处理
11、groupBy是将传入的数据进行分组
12、keyBy是为数据集中的每个个体数据添加一个key,从而形成键值对
13、reduce同时对2个数据进行处理,主要是对传入的数据进行合并处理
14、sortBy是对已有的RDD进行重新排序
import org.apache.spark.{SparkConf, SparkContext}
object test {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("test")
val sc=new SparkContext(conf)
val arr1=sc.parallelize(Array((,"a"),(,"c"),(,"b"),(,"x"),(,"f")))//parallelize将内存数据读入Spark系统中,作为整体数据集
val res1=arr1.sortBy(word=>word._1,true)
val res2=arr1.sortBy(word=>word._2,true)
res1.foreach(println)
res2.foreach(println)
}
}
15、zip可以将若干个RDD压缩成一个新的RDD
走近RDD的更多相关文章
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- Spark笔记:复杂RDD的API的理解(下)
本篇接着谈谈那些稍微复杂的API. 1) flatMapValues:针对Pair RDD中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录 这个方法我最开始接 ...
- Spark笔记:复杂RDD的API的理解(上)
本篇接着讲解RDD的API,讲解那些不是很容易理解的API,同时本篇文章还将展示如何将外部的函数引入到RDD的API里使用,最后通过对RDD的API深入学习,我们还讲讲一些和RDD开发相关的scala ...
- Spark笔记:RDD基本操作(下)
上一篇里我提到可以把RDD当作一个数组,这样我们在学习spark的API时候很多问题就能很好理解了.上篇文章里的API也都是基于RDD是数组的数据模型而进行操作的. Spark是一个计算框架,是对ma ...
- Spark笔记:RDD基本操作(上)
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- Spark核心——RDD
Spark中最核心的概念为RDD(Resilient Distributed DataSets)中文为:弹性分布式数据集,RDD为对分布式内存对象的 抽象它表示一个被分区不可变且能并行操作的数据集:R ...
- 【原】Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Spark Rdd coalesce()方法和repartition()方法
在Spark的Rdd中,Rdd是分区的. 有时候需要重新设置Rdd的分区数量,比如Rdd的分区中,Rdd分区比较多,但是每个Rdd的数据量比较小,需要设置一个比较合理的分区.或者需要把Rdd的分区数量 ...
- RDD/Dataset/DataFrame互转
1.RDD -> Dataset val ds = rdd.toDS() 2.RDD -> DataFrame val df = spark.read.json(rdd) 3.Datase ...
随机推荐
- windows下配置cygwin和dig的环境变量
配置cygwin和dig的环境变量 打开"控制面板"("开始">"设置">"控制面板"),然后双击" ...
- [js高手之路] es6系列教程 - 函数的默认参数详解
在ES6之前,我们一般用短路表达式处理默认参数 function show( a, b ){ var a = a || 10; var b = b || 20; console.log( a, b ) ...
- 模板 mú bǎn
链式前向星 #include<string.h> #define MAX 10000 struct node { int to,nex,wei; }edge[MAX*+]; ],cnt; ...
- 【head first python】2.共享你的代码 函数模块
#coding:utf-8 #注释代码! #添加两个注释,一个描述模块,一个描述函数 '''这是nester.py模块,提供了一个名为print_lol()的函数, 这个函数的作用是打印列表,其中可能 ...
- python基础===filter在python3中的用法
l = range(0,20) def f(x): if x%2 == 0: return True print(list(filter(f,l))) #和python2的区别在于,要加一个list
- 优先级队列Priority_queue
定义 拥有权值观点的queue,,一个是返回最高优先级对象,一个是在底端添加新的对象.这种数据结构就是优先级队列(Priority Queue) . 实现 利用max_heap完成,以vector表现 ...
- Nginx反向代理和负载均衡的配置
1.反向代理配置 反向代理也称"动静分离",nginx不自己处理图片的相关请求,而是把图片的请求转发给其他服务器来处理. 修改nginx部署目录下conf子目录的nginx.con ...
- 页面引入css用link和import的区别
假设有一个css文件a.css,文件里的内容如下: p { font-size: 18px; } 现在分别使用两种方式引入a.css: 1.使用html的link标签 <link rel=&qu ...
- cat命令汇总整理
Cat命令:一般用作打开文件,查看文件内容(可以一次查看多个文件),参数有如下几个: -a 或 –all,显示全部 -b 或--number-nonblank 对非空输出行编号 -n 或 --numb ...
- git 简易使用说明
背景 代码用git管理,所以需要大家熟悉git工具的一些操作 目前我们自动化在develop分支上进行编写 前言 安装git,https://git-scm.com/ 可视化工具推荐,sourcetr ...