JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(二)
一 前言
本文是上一篇博客JWebFileTrans:一款可以从网络上下载文件的小程序(一)的续集。此篇博客主要在上一篇的基础上加入了断点续传的功能,用户在下载中途停止下载后,下次可以读取断点文件,接着上次已经下载的部分文件继续下载。另外将程序名从JWebFileTrans更改为JDownload,并从github的utility repository中独立出来专门维护,后续会添加多线程、ftp下载等功能。JDownload的github链接请点击JDownload源代码 。
另外时隔三个月后,我按照上一篇博客里面的四个下载链接再次测试的时候发现失败了,原因在于其中有的http链接已经发生变化,比如stable目录下的hbase从1.2.4升级成1.2.5了。然后我把其中有个链接中的1.2.4改成1.2.5结果也无法下载,后来发现是改成1.2.5后的链接是对的,但是服务器会把这个链接重定向到真正的下载链接。由于JDownload在设计过程中并没有考虑到可能出现的重定向问题,所以对于此类链接暂时无法下载,但是在未来可能会考虑增加此类功能。所以大家在测试的时候选择好正确的http链接,确保此链接当前存在,并且是真正的下载链接而不是重定向的链接,这样才会测试成功。
PS: 本文是github用户junhuster,以及微博用户http://weibo.com/junhuster 的原创作品,转载请注明原作者和博客出处,谢谢。
二 断点续传功能展示
测试链接 http://www.flashget.com/apps/flashget3.7.0.1222cn.exe ,这是快车下载软件的官网下载链接,注意,如果读者也用快车链接来做实验的话,请先到快车官网检查下最新的下载链接,因为诸如软件升级改版本号等问题,就会导致本文给出的链接失效。在实验的过程中,作者在虚拟机Ubuntu linux的终端shell里面先提交一个脚本从快车官网下载,等下载到1M左右的时候,终端输入crtl-z中断程序的执行。然后再次运行另外一个脚本,这个脚本会告诉JDownload 去读取断点文件,然后接着上次未完成的下载点继续下载。下载成功后,把快车拷贝到windows 10操作系统里,然后点击测试证明下载的文件可以正确执行。实验过程的截图如下:
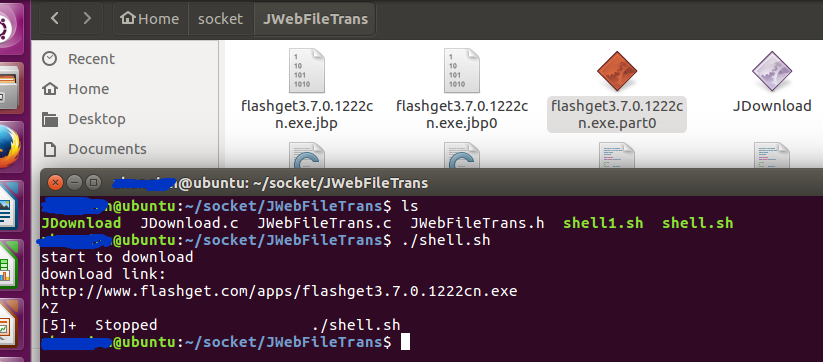
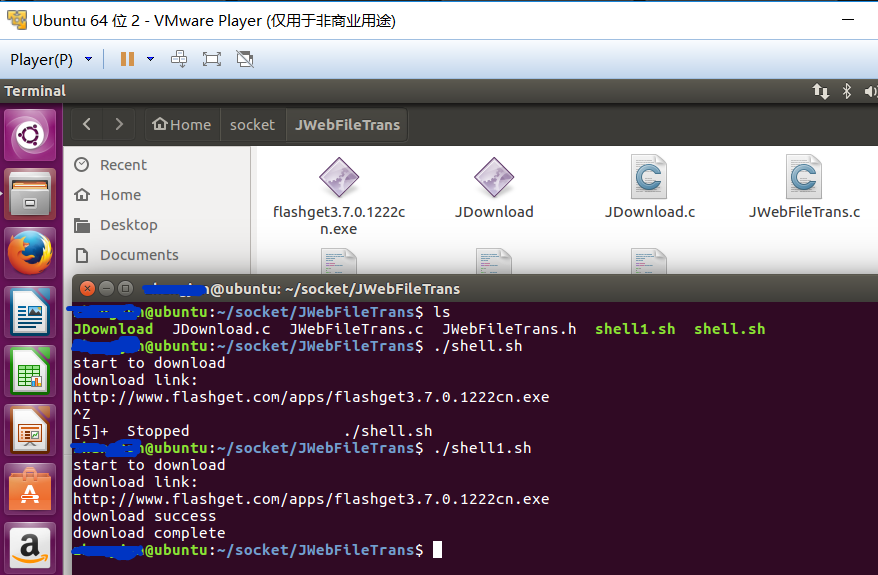
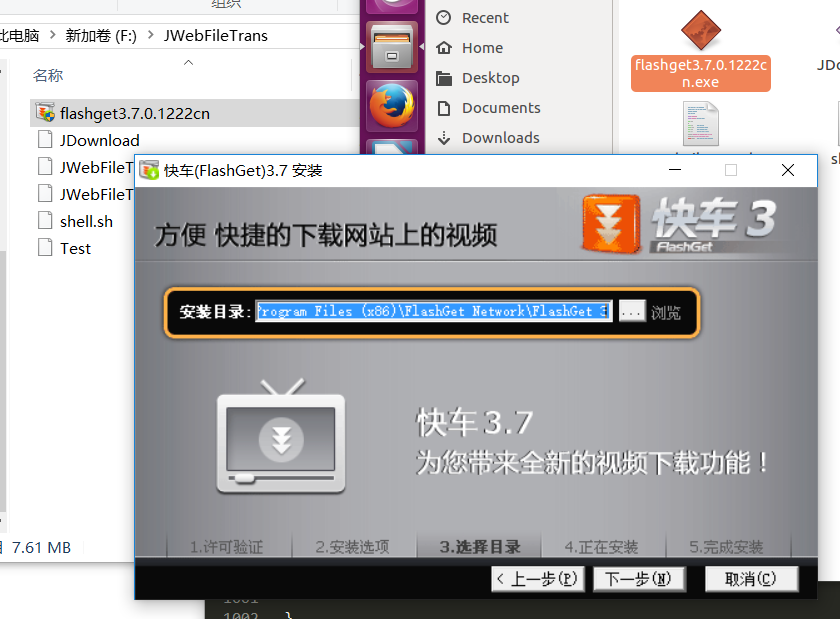
如上图,从第一张图中的终端可以看出,中途笔者执行了crtl-z中断了执行,图中后缀.jbp .jbp0是断点文件,断点续传依赖这些断点数据来继续下载,.part0是未下载完成的快车软件。在第二张图中读者可以看到作者在中断了上一次的执行后,再一次执行另外一个脚本shell1.sh,(这两个脚本请参加作者的github JDownload的test目录),开始继续上次的下载,直到完成。最后一张图是把在ubuntu中下载的快车软件复制的windows里面执行的画面,以确保下载的软件没有出现错误。显然从图中可以看出安装程序可以正常执行。
三 基本思路
关于下载的功能设计部分请读者参考作者的上一篇博客,或者直接参考github代码,链接在前言中。本文主要描述如何在上一篇博客的基础上加入断点续传的功能。
其实断点续传的功能挺简单的,无非就是记录一下上次下载的位置,然后再次下载的时候从那个位置开始就行了。从上一篇博客可以了解到,在下载一个文件的时候,我们会按照一定的规则把这个文件划分为N等分,每一次向服务器请求1/N的数据。所以显然为了支持断点续传,我们需要记录该文件被等分的数目N, 因为是续传我们还要记录上一次已经下载了多少个等分。中断下载后再一次链接时需要知道服务器的链接(或者ip),因此这些信息也是需要记录的。因此在单线程下载的时候只需要用一个文件记录这些信息就行了。然而未来要假如多线程的支持,那个时候一个文件会同时由M个线程同时下载,每一个线程下载这个文件的第i到第j个等分,对于每一个线程来说,都有可能下载中断重新续传的可能性,所以每一个线程所下载的那部分文件都需要记录一份断点信息。而且应该还有一份单独的信息记录总共文件被分成了几份来下载(例如4个线程就相当于把文件分成了四份来下载),这样下载中断后,下载就可以挨个读取所有的断点文件来续传。
由以上描述我们可以设计出如下的数据结构:
下面这个描述的是总体断点的信息情况
typedef struct break_point{
long file_size;
long num_of_part_file;
long size_of_one_piece;
long total_num_of_piece_of_whole_file;
char server_ip[+];
int server_port;
}break_point;
各个字段的含义是:
- file_size: 文件大小,以字节为单位
- num_of_part_file: 文件被分为多少份来下载,比如四个线程来下载就是四份
- size_of_one_piece: 前文说过,一个大文件被分为很多小的等分,这个字段就表示每一个等分的大小,也是以字节为单位
- total_num_of_piece_of_whole_file: 文件总共有多少等分
- server_ip: 服务器ip地址
- server_port: 服务器端口号
下面这个是描述的是每一个线程下载的那部分文件对应的断点信息,当前实际上只有一个线程,未来会加入多线程的支持
typedef struct break_point_part
{
long start_num_of_piece_of_this_part_file;
long end_num_of_piece_of_this_part_file;
long size_of_last_incomplete_piece;
long alread_download_num_of_piece;
}break_point_of_part;
各个字段的含义是:
- start_num_of_piece_of_this_part_file: 该部分文件对应的起始等分数,也即前文提到的第i个等分
- end_num_of_piece_of_this_part_file: 分到的结束等分数,也即前文提到的第j个等分
- size_of_last_incomplete_piece: 文件不一定能够完全均分,最后一份取余数
- alread_download_num_of_piece:已经下载了的等分数目
假如,我们一开始启用了四个线程来下载,那么就会生成一份break_point信息,四份break_point_of_part信息。
在一开始的时候我们向服务器查询要下载的文件的大小,然后根据自己代码中每一次下载分片的大小,将文件记为N等分,这N等分将分给M个线程,每一个线程下载其中的N/M个等分。根据这些信息就可以创建出相应的断点文件。然后每一个线程在每一次下载成功后就更新一下对应的断点文件,主要是更新已经下载的等分数目。在中断下载后,再一次下载的时候,程序首先会读取break_point断点文件,得到总共有多少个break_point_of_part断点文件,然后挨个读取break_point_of_part断点文件,解析之,然后继续上次未完成的地方继续下载。
由上所述,我们可以设计出如下几个函数:
int Http_create_breakpoint_file(char *file_name, FILE **fp_breakpoint, long file_size, long num_of_part_file, long size_of_one_piece,
long total_num_of_piece_of_whole_file,
char *server_ip, int server_port);
int Http_create_breakpoint_part_file(char *file_name, FILE **fp_breakpoint_part, int part_num, long start_num_of_piece_of_this_part_file,
long end_num_of_piece_of_this_part_file,
long size_of_last_incompelet_piece,
long alread_download_num_of_piece);
int Update_breakpoint_part_file(FILE *fp_breakpoint_part, int num_of_piece_tobe_added);
int Delete_breakpoint_file(char *file_name, FILE *fp);
四 代码实现
下载部分的代码请参考上一篇博客或者github源代码。这里主要描述断点相关函数。
首先是Http_create_breakpoint_file:
int Http_create_breakpoint_file(char *file_name, FILE **fp_breakpoint, long file_size, long num_of_part_file, long size_of_one_piece,
long total_num_of_piece_of_whole_file,
char *server_ip, int server_port){
/**
** check argument error
*/
if(file_name==NULL || fp_breakpoint==NULL){ printf("Http_create_breakpoint_file: argument error\n");
exit();
} char *break_point_file_name=(char *)malloc((strlen(file_name)++)*sizeof(char));
if(NULL==break_point_file_name){ printf("Http_create_breakpoint_file: malloc failed\n");
exit(); }
strcpy(break_point_file_name,file_name);
strcat(break_point_file_name,".jbp"); if(access(break_point_file_name,F_OK)==){
int ret=remove(break_point_file_name);
if(ret!=){
perror("Http_create_breakpoint_file,remove,\n");
exit();
}
} *fp_breakpoint=fopen(break_point_file_name,"w+");
if(NULL==*fp_breakpoint){
printf("Http_create_breakpoint_file: fopen failed\n");
exit();
} unsigned char *break_point_buffer=(unsigned char *)malloc(sizeof(break_point)+);
if(NULL==break_point_buffer){
printf("Http_create_breakpoint_file: malloc failed\n");
exit();
} ((break_point *)break_point_buffer)->file_size=file_size;
((break_point *)break_point_buffer)->num_of_part_file=number_of_part_file;
((break_point *)break_point_buffer)->size_of_one_piece=size_of_one_piece;
((break_point *)break_point_buffer)->total_num_of_piece_of_whole_file=total_num_of_piece_of_whole_file;
((break_point *)break_point_buffer)->server_port=server_port; memcpy(((break_point *)break_point_buffer)->server_ip, server_ip, strlen(server_ip));
((break_point *)break_point_buffer)->server_ip[strlen(server_ip)]='\0'; int ret_fwrite=fwrite(break_point_buffer,sizeof(break_point),,*fp_breakpoint);
fflush(*fp_breakpoint); if(ret_fwrite!=){
printf("Http_create_breakpoint_file: fwrite failed \n");
exit();
} if(break_point_file_name!=NULL){
free(break_point_file_name);
} return ;
}
然后是Http_create_breakpoint_part_file:
int Http_create_breakpoint_part_file(char *file_name, FILE **fp_breakpoint_part, int part_num, long start_num_of_piece_of_this_part_file,
long end_num_of_piece_of_this_part_file,
long size_of_last_incomplete_piece,
long alread_download_num_of_piece){
if(file_name==NULL || fp_breakpoint_part==NULL || part_num<){
printf("Http_create_breakpoint_part_file, argument error\n");
exit();
} char buffer_for_part_num[];
sprintf(buffer_for_part_num, "%d",part_num);
int part_num_str_len=strlen(buffer_for_part_num);
char *break_point_part_file_name=(char *)malloc((strlen(file_name)++part_num_str_len+)*sizeof(char));
if(break_point_part_file_name==NULL){
printf("Http_create_breakpoint_part_file,malloc failed\n");
exit();
} strcpy(break_point_part_file_name,file_name);
strcat(break_point_part_file_name,".jbp");
strcat(break_point_part_file_name,buffer_for_part_num); if(access(break_point_part_file_name,F_OK)==){
int ret=remove(break_point_part_file_name);
if(ret!=){
perror("Http_create_breakpoint_part_file,remove");
exit();
}
} *fp_breakpoint_part=fopen(break_point_part_file_name, "w+");
if(*fp_breakpoint_part==NULL){
printf("Http_create_breakpoint_part_file,fopen failed\n");
exit();
} break_point_of_part bpt;
bpt.start_num_of_piece_of_this_part_file=start_num_of_piece_of_this_part_file;
bpt.end_num_of_piece_of_this_part_file=end_num_of_piece_of_this_part_file;
bpt.size_of_last_incomplete_piece=size_of_last_incomplete_piece;
bpt.alread_download_num_of_piece=alread_download_num_of_piece; int ret=fwrite(&bpt, sizeof(break_point_of_part), , *fp_breakpoint_part);
if(ret!=){
printf("Http_create_breakpoint_part_file,fwrite, break_point_of_part,error\n");
exit();
} fflush(*fp_breakpoint_part); if(break_point_part_file_name!=NULL){
free(break_point_part_file_name);
} return ; }
接下来是int Update_breakpoint_part_file:
int Update_breakpoint_part_file(FILE *fp_breakpoint_part, int num_of_piece_tobe_added){
if(fp_breakpoint_part==NULL || num_of_piece_tobe_added<){
printf("Update_breakpoint_part_file,argument error\n");
exit();
}
break_point_of_part *bpt=(break_point_of_part *)malloc(sizeof(break_point_of_part));
if(bpt==NULL){
printf("Update_breakpoint_part_file,malloc failed\n");
exit();
}
fseek(fp_breakpoint_part, , SEEK_SET);
int ret_fread=fread(bpt, sizeof(break_point_of_part), , fp_breakpoint_part);
int start_num=bpt->start_num_of_piece_of_this_part_file;
int end_num=bpt->end_num_of_piece_of_this_part_file;
bpt->alread_download_num_of_piece=bpt->alread_download_num_of_piece+num_of_piece_tobe_added;
if((bpt->alread_download_num_of_piece)<=(bpt->end_num_of_piece_of_this_part_file-bpt->start_num_of_piece_of_this_part_file++)){
fseek(fp_breakpoint_part, , SEEK_SET);
int ret=fwrite(bpt, sizeof(break_point_of_part), , fp_breakpoint_part);
if(ret!=){
printf("Update_breakpoint_part_file,fwrite failed\n");
exit();
}
fflush(fp_breakpoint_part);
}else{
printf("Update_breakpoint_part_file, num_of_piece_tobe_added not correct\n");
exit();
}
}
最后是Delete_breakpoint_file,文件下载成功后,这些断点文件应该删除
int Delete_breakpoint_file(char *file_name,FILE *fp){
if(file_name==NULL || fp==NULL){
printf("Delete_breakpoint_file, argument error\n");
exit();
}
break_point *bp=(break_point *)malloc(sizeof(break_point));
fseek(fp, , SEEK_SET);
int ret=fread(bp, sizeof(break_point), , fp);
if(ret!=){
printf("Delete_breakpoint_file,fread failed\n");
exit();
}
int num=bp->num_of_part_file;
char *buffer=(char *)malloc((strlen(file_name)++));
for(int i=;i<num;i++){
char buffer_part[];
sprintf(buffer_part, "%d",i);
strcpy(buffer,file_name);
strcat(buffer,".jbp");
strcat(buffer,buffer_part);
if(access(buffer, F_OK)==){
if(remove(buffer)!=){
perror("Delete_breakpoint_file,remove .jbp_num");
exit();
}
}
}
fclose(fp);
strcpy(buffer, file_name);
strcat(buffer, ".jbp");
if(access(buffer, F_OK)==){
if(remove(buffer)!=){
perror("Delete_breakpoint_file,remove .jbp");
exit();
}
}
if(buffer!=NULL){
free(buffer);
}
return ;
}
注意,每一次重新续传读取断点文件的时候模式不要设错了,笔者之前每次读取断点文件以“w+”模式打开,结果每次下载完后,文件都是错误的,原因是w+模式打开文件,会把文件清零,这样自然就出错了。
五 结束语
自此整篇文章就结束了,更详细的信息请访问笔者的github链接。
联系方式:https://github.com/junhuster/
http://weibo.com/junhuster/
JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(二)的更多相关文章
- JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(三),多线程断点下载
一 前言 本篇博客是<JWebFileTrans(JDownload):一款可以从网络上下载文件的小程序>系列博客的第三篇,本篇博客的内容主要是在前两篇的基础上增加多线程的功能.简言之,本 ...
- JDownload: 一款可以从网络上下载文件的小程序第四篇(整体架构描述)
一 前言 时间过得真快,距离本系列博客第一篇的发布已经过去9个月了,本文是该系列的第四篇博客,将对JDownload做一个整体的描述与介绍.恩,先让笔者把记忆拉回到2017年年初,那会笔者在看Unix ...
- JWebFileTrans: 一款可以从网络上下载文件的小程序(一)
一 摘要 JWebFileTrans是一款基于socket的网络文件传输小程序,目前支持从HTTP站点下载文件,后续会增加ftp站点下载.断点续传.多线程下载等功能.其代码已开源到github上面,下 ...
- C# 中从网络上下载文件保存到本地文件
下面是C#中常用的从Internet上下载文件保存到本地的一些方法,没有太多的技巧. 1.通过 WebClient 类下载文件 WebClient webClient = new WebClien ...
- 从网络上下载文件到sd卡上
String SDPATH = Environment.getExternalStorageDirectory() + "/"; String path = SDPATH + &q ...
- 微信小程序基础之在微信上显示和体验小程序?
随着小程序正式上线,用户现在可以通过二维码.搜索等方式体验到开发者们开发的小程序了. 用户只要将微信更新至最新版本,体验过小程序后,便可在发现页面看到小程序TAB,但微信并不会通过这个地方向用户推荐小 ...
- Android开发 ---从互联网上下载文件,回调函数,图片压缩、倒转
Android开发 ---从互联网上下载文件,回调函数,图片压缩.倒转 效果图: 描述: 当点击“下载网络图像”按钮时,系统会将图二中的照片在互联网上找到,并显示在图像框中 注意:这个例子并没有将图 ...
- 图片的URL上传至阿里云OSS操作(微信小程序二维码返回的二进制上传到OSS)
当我们从网络中获取一个URL的图片我们要存储到本地或者是私有的云时,我们可以这样操作 把url中的图片文件下载到本地(或者上传到私有云中) public String uploadUrlToOss ...
- 通过cmd命令到ftp上下载文件
通过cmd命令到ftp上下载文件 点击"开始"菜单.然后输入"cmd"点"enter"键,出现cmd命令执行框 2 输入"ftp& ...
随机推荐
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- SQL server 数据库(视图、事物、分离附加、备份还原))
ql Server系列:视图.事物.备份还原.分离附加 视图是数据库中的一种虚拟表,与真实的表一样,视图包含一系列带有名称的行和列数据.行和列数据用来自定义视图的查询所引用的表,并且在引用视图时动态 ...
- CSS限制字数,超出部份显示点点点...
最近项目中需要用CSS实现限制字数,超出部份显示点点点...,只需要一下代码即可: width:400px;/*要显示文字的宽度*/ text-overflow :ellipsis; /*让截断的文字 ...
- 【方法】如何限定IP访问Oracle数据库
[方法]如何限定IP访问Oracle数据库 1.1 BLOG文档结构图 1.2 前言部分 1.2.1 导读和注意事项 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知 ...
- [LeetCode] Decode String 题解
题目 题目 s = "3[a]2[bc]", return "aaabcbc". s = "3[a2[c]]", return " ...
- 检测Windows程序的内存和资源泄漏之原生语言环境
最近接连收到大客户的反馈,我们开发的一个软件,姑且称之为App-E吧,在项目规模特别大的情况下,长时间使用会逐渐耗尽内存,运行越来越缓慢,软件最终崩溃.由于App-E是使用混合语言开发的,主界面使用C ...
- 获取JVM的dump文件
获取JVM的dump文件的两种方式 1. JVM启动时增加两个参数: #出现 OOME 时生成堆 dump: -XX:+HeapDumpOnOutOfMemoryError #生成堆文件地址: -XX ...
- [cookie篇]从cookie-parser中间件说起
当我们在写web的时候,难免会要使用到cookie,由于node.js有了express这个web框架,我们就可以方便地去建站.在使用express时,经常会使用到cookie-parser这个插件. ...
- js复制内容到剪切板,兼容pc和手机端,支持Safari浏览器
最近,一些项目中用到监听用户复制.剪切的操作. 案例1.在PC端,当用户获得一个京东卡的使用券,当用户使用ctrl + C复制得到的使用券时,将使用券的代号复制到粘贴板,以便于用户ctrl+v进行 ...
- 老李推荐:第14章4节《MonkeyRunner源码剖析》 HierarchyViewer实现原理-装备ViewServer-端口转发 3
formAdbRequest我们在之前已经分析过,做的事情就是组建好ADB协议的命令以待发送给ADB服务器,在我们558行中最终组建好的ADB协议命令将会如下: “host-serial:xxx:fo ...