spark client + yarn计算
前提:完成hadoop + kerberos安全环境搭建。
安装配置spark client:
1. wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
2. 配置
指定hadoop路径
vim conf/spark-env.sh HADOOP_CONF_DIR=/xxx/soft/hadoop-2.7.3/etc/hadoop
配置环境变量:
vim /etc/profile export SPARK_HOME=/xxx/soft/spark-2.2.0-bin-hadoop2.7
分配kerberos
kadmin.local addprinc -randkey sparkclient01@JENKIN.COM
xst -k /var/kerberos/krb5kdc/keytab/sparkclient01.keytab sparkclient01@JENKIN.COM
将keytab分发给spark client
scp /var/kerberos/krb5kdc/keytab/sparkclient01.keytab hadoop1:/xxx/soft/spark-2.2.0-bin-hadoop2.7/
在hdfs上建立文件夹:( eventLog.dir )
hadoop fs -mkdir -p /jenkintest/tmp/spark01 hadoop fs -ls /jenkintest/tmp/
启动client:
cd ./bin ./spark-submit --class org.apache.spark.examples.SparkPi \
--conf spark.eventLog.dir=hdfs://jenkintest/tmp/spark01 \
--master yarn \
--deploy-mode client \
--driver-memory 4g \
--principal sparkclient01 \
--keytab /xxx/soft/spark-2.2.0-bin-hadoop2.7/sparkclient01.keytab \
--executor-memory 1g \
--executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples*.jar \
10
命令解释:
--master yarn //代表spark任务在yarn上
--master cluser //代表spark 在yarn集群上
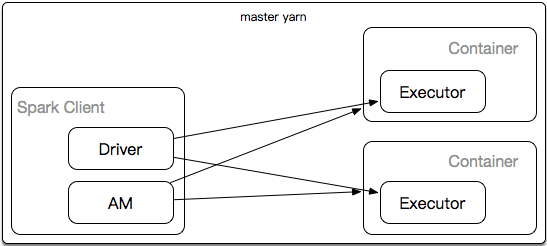
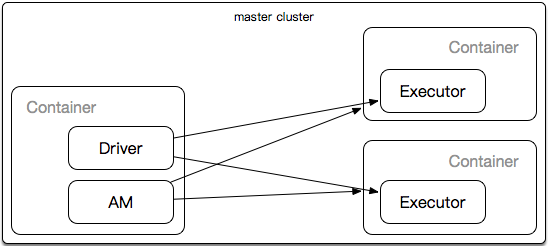
AM负责在yarn上申请资源,运行在container。
spark通过Driver控制Executor。
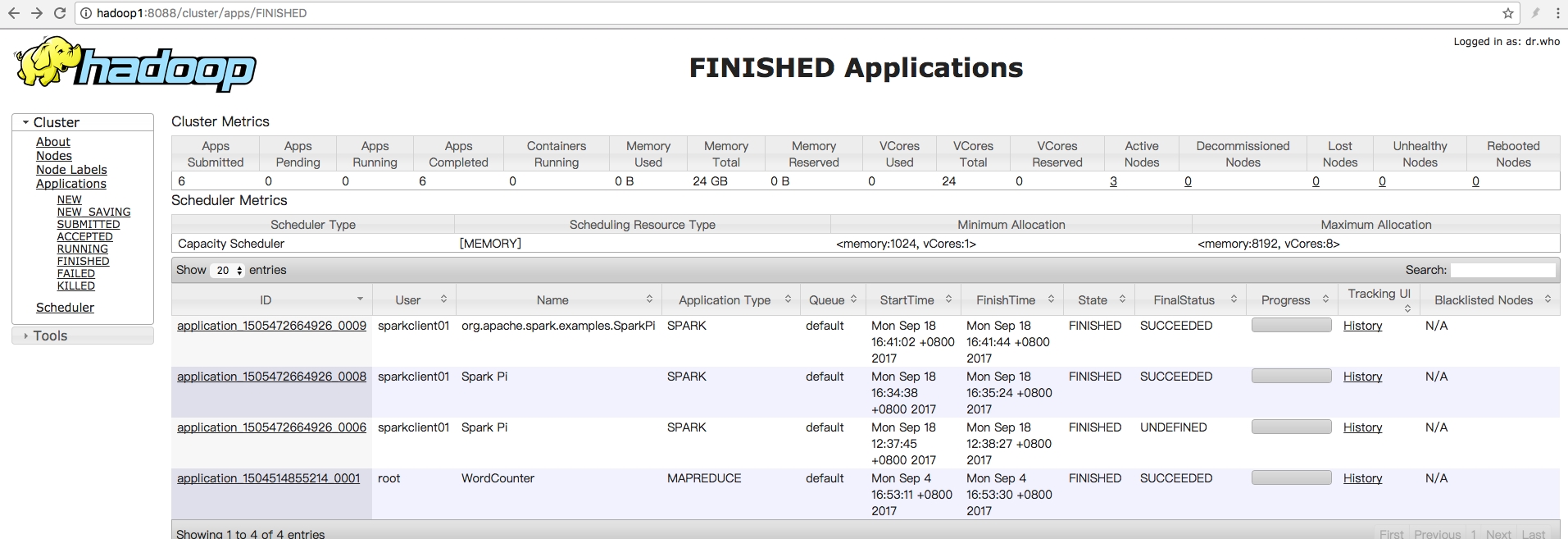
运行结果:
spark client + yarn计算的更多相关文章
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark on yarn,client模式时,执行spark-submit命令后命令行日志和YARN AM日志
[root@linux-node1 bin]# ./spark-submit \> --class com.kou.List2Hive \> --master yarn \> --d ...
- Spark通过YARN提交任务不成功(包含YARN cluster和YARN client)
无论用YARN cluster和YARN client来跑,均会出现如下问题. [spark@master spark-1.6.1-bin-hadoop2.6]$ jps 2049 NameNode ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- Apache Spark源码走读之8 -- Spark on Yarn
欢迎转载,转载请注明出处,徽沪一郎. 概要 Hadoop2中的Yarn是一个分布式计算资源的管理平台,由于其有极好的模型抽象,非常有可能成为分布式计算资源管理的事实标准.其主要职责将是分布式计算集群的 ...
- Spark on Yarn
Spark on Yarn 1. Spark on Yarn模式优点 与其他计算框架共享集群资源(eg.Spark框架与MapReduce框架同时运行,如果不用Yarn进行资源分配,MapReduce ...
- Spark on Yarn遇到的问题及解决思路
原文:http://www.aboutyun.com/thread-9425-1-1.html 问题导读1.Connection Refused可能原因是什么?2.如何判断内存溢出,该如何解决?扩展: ...
- Spark On YARN内存分配
本文转自:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool 此文解决了Spark ...
- Spark 1.0.0 横空出世 Spark on Yarn 部署(Hadoop 2.4)
就在昨天,北京时间5月30日20点多.Spark 1.0.0最终公布了:Spark 1.0.0 released 依据官网描写叙述,Spark 1.0.0支持SQL编写:Spark SQL Progr ...
随机推荐
- 【BZOJ2905】背单词 fail树+DFS序+线段树
[BZOJ2905]背单词 Description 给定一张包含N个单词的表,每个单词有个价值W.要求从中选出一个子序列使得其中的每个单词是后一个单词的子串,最大化子序列中W的和. Input 第一行 ...
- Android自定义控件之圆形进度条ImageView
From:http://blog.csdn.net/xiadik/article/details/41648181package com.wangran.beautiful_girl_show.vie ...
- Spring boot:logback文件配置
resources文件夹下:新建logback-spring.xml文件. 文件内容like: <?xml version="1.0" encoding="UTF- ...
- 2017-2018-2 20165330实验二《Java面向对象程序设计》实验报告
实验内容 初步掌握单元测试和TDD 理解并掌握面向对象三要素:封装.继承.多态 初步掌握UML建模 熟悉S.O.L.I.D原则 了解设计模式 实验步骤 (一)单元测试 三种代码 伪代码:从意图层面来解 ...
- 2017 Multi-University Training Contest - Team 1—HDU6033&&HDU6034
HDU6033 Add More Zero 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6033 题目意思:给一个m,求一个数k使得10^k最接近2 ...
- AJAX Form Submit Framework 原生js post json
https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest/Using_XMLHttpRequest <!doctype ht ...
- Accuracy, Precision, Resolution & Sensitivity
Instrument manufacturers usually supply specifications for their equipment that define its accuracy, ...
- Python代码样例列表
扫描左上角二维码,关注公众账号 数字货币量化投资,回复“1279”,获取以下600个Python经典例子源码 ├─algorithm│ Python用户推荐系统曼哈顿算法实现.py│ ...
- maven 之nexus仓库管理_私服配置
1.下载nexus私服 下载地址:http://www.sonatype.org/downloads/nexus-latest.war 2.解压 解压以下压缩包 3.配置环境变量 *\nexus-2. ...
- weblogic中eclipse远程调试
1. weblogic 配置文件修改 修改文件: weblogic/weblogic103/user_projects/domains/xxxx/bin/setDomainEnv.sh(windows ...