Apache Spark源码走读之8 -- Spark on Yarn
欢迎转载,转载请注明出处,徽沪一郎。
概要
Hadoop2中的Yarn是一个分布式计算资源的管理平台,由于其有极好的模型抽象,非常有可能成为分布式计算资源管理的事实标准。其主要职责将是分布式计算集群的管理,集群中计算资源的管理与分配。
Yarn为应用程序开发提供了比较好的实现标准,Spark支持Yarn部署,本文将就Spark如何实现在Yarn平台上的部署作比较详尽的分析。
Spark Standalone部署模式回顾
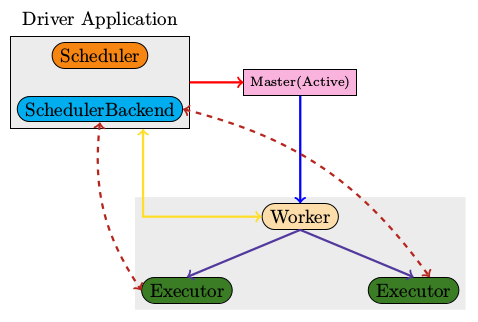
上图是Spark Standalone Cluster中计算模块的简要示意,从中可以看出整个Cluster主要由四种不同的JVM组成
- Master 负责管理整个Cluster,Driver Application和Worker都需要注册到Master
- Worker 负责某一个node上计算资源的管理,如启动相应的Executor
- Executor RDD中每一个Stage的具体执行是在Executor上完成
- Driver Application driver中的schedulerbackend会因为部署模式的不同而不同
换个角度来说,Master对资源的管理是在进程级别,而SchedulerBackend则是在线程的级别。
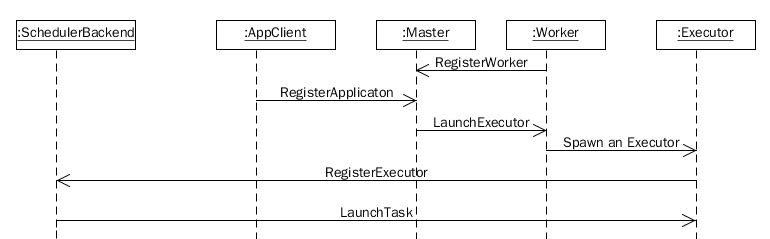
启动时序图
YARN的基本架构和工作流程
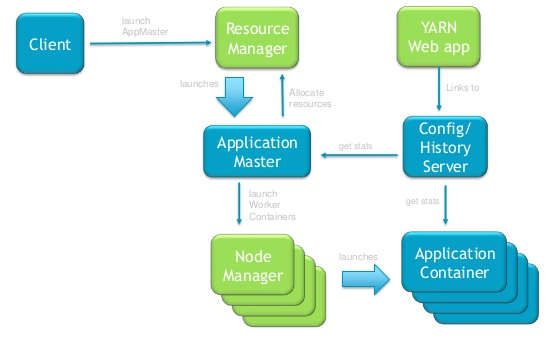
YARN的基本架构如上图所示,由三大功能模块组成,分别是1) RM (ResourceManager) 2) NM (Node Manager) 3) AM(Application Master)
作业提交
- 用户通过Client向ResourceManager提交Application, ResourceManager根据用户请求分配合适的Container,然后在指定的NodeManager上运行Container以启动ApplicationMaster
- ApplicationMaster启动完成后,向ResourceManager注册自己
- 对于用户的Task,ApplicationMaster需要首先跟ResourceManager进行协商以获取运行用户Task所需要的Container,在获取成功后,ApplicationMaster将任务发送给指定的NodeManager
- NodeManager启动相应的Container,并运行用户Task
实例
上述说了一大堆,说白了在编写YARN Application时,主要是实现Client和ApplicatonMaster。实例请参考github上的simple-yarn-app.
Spark on Yarn
结合Spark Standalone的部署模式和YARN编程模型的要求,做了一张表来显示Spark Standalone和Spark on Yarn的对比。
| Standalone | YARN | Notes |
|---|---|---|
| Client | Client | standalone请参考spark.deploy目录 |
| Master | ApplicationMaster | |
| Worker | ExecutorRunnable | |
| Scheduler | YarnClusterScheduler | |
| SchedulerBackend | YarnClusterSchedulerBackend |
作上述表格的目的就是要搞清楚为什么需要做这些更改,与之前Standalone模式间的对应关系是什么。代码走读时,分析的重点是ApplicationMaster, YarnClusterSchedulerBackend和YarnClusterScheduler
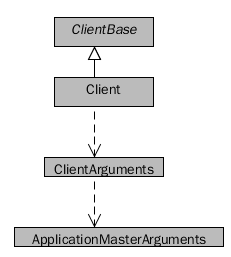
一般来说,在Client中会显示的指定启动ApplicationMaster的类名,如下面的代码所示
ContainerLaunchContext amContainer =
Records.newRecord(ContainerLaunchContext.class);
amContainer.setCommands(
Collections.singletonList(
"$JAVA_HOME/bin/java" +
" -Xmx256M" +
" com.hortonworks.simpleyarnapp.ApplicationMaster" +
" " + command +
" " + String.valueOf(n) +
" 1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout" +
" 2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr"
)
);
但在yarn.Client中并没有直接指定ApplicationMaster的类名,是通过ClientArguments进行了封装,真正指定启动类的名称的地方在ClientArguments中。构造函数中指定了amClass的默认值是org.apache.spark.deploy.yarn.ApplicationMaster
实例说明
将SparkPi部署到Yarn上,下述是具体指令。
$ SPARK_JAR=./assembly/target/scala-2.10/spark-assembly-0.9.1-hadoop2.0.5-alpha.jar \
./bin/spark-class org.apache.spark.deploy.yarn.Client \
--jar examples/target/scala-2.10/spark-examples-assembly-0.9.1.jar \
--class org.apache.spark.examples.SparkPi \
--args yarn-standalone \
--num-workers 3 \
--master-memory 4g \
--worker-memory 2g \
--worker-cores 1
从输出的日志可以看出, Client在提交的时候,AM指定的是org.apache.spark.deploy.yarn.ApplicationMaster
13/12/29 23:33:25 INFO Client: Command for starting the Spark ApplicationMaster: $JAVA_HOME/bin/java -server -Xmx4096m -Djava.io.tmpdir=$PWD/tmp org.apache.spark.deploy.yarn.ApplicationMaster --class org.apache.spark.examples.SparkPi --jar examples/target/scala-2.9.3/spark-examples-assembly-0.8.1-incubating.jar --args 'yarn-standalone' --worker-memory 2048 --worker-cores 1 --num-workers 3 1> /stdout 2> /stderr
小结
spark在提交时,所做的资源申请是一次性完成的,也就是说对某一个具体的Application,它所需要的Executor个数是一开始就是计算好,整个Cluster如果此时能够满足需求则提交,否则进行等待。而且如果有新的结点加入整个cluster,已经运行着的程序并不能使用这些新的资源。缺少rebalance的机制,这点上storm倒是有。
参考资料
- Launch Spark On YARN http://spark.apache.org/docs/0.9.1/running-on-yarn.html
- Getting started Writing YARN Application http://hortonworks.com/blog/getting-started-writing-yarn-applications/
- 《Hadoop技术内幕 深入解析YARN架构设计与实现原理》 董西成著
- YARN应用开发流程 http://my.oschina.net/u/1434348/blog/193374 强烈推荐!!!
Apache Spark源码走读之8 -- Spark on Yarn的更多相关文章
- Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎. 概要 之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码 ...
- Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读. 拟牛顿法 数学原理 代码实现 L-BFGS算法中使 ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
- Apache Spark源码走读之1 -- Spark论文阅读笔记
欢迎转载,转载请注明出处,徽沪一郎. 楔子 源码阅读是一件非常容易的事,也是一件非常难的事.容易的是代码就在那里,一打开就可以看到.难的是要通过代码明白作者当初为什么要这样设计,设计之初要解决的主要问 ...
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- spark 源码分析之十--Spark RPC剖析之TransportResponseHandler、TransportRequestHandler和TransportChannelHandler剖析
spark 源码分析之十--Spark RPC剖析之TransportResponseHandler.TransportRequestHandler和TransportChannelHandler剖析 ...
- spark 源码分析之十一--Spark RPC剖析之TransportClient、TransportServer剖析
TransportClient类说明 先来看,官方文档给出的说明: Client for fetching consecutive chunks of a pre-negotiated stream. ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码
欢迎转载,转载请注明出处,徽沪一郎. 概要 上篇博文讲述了如何通过修改源码来查看调用堆栈,尽管也很实用,但每修改一次都需要编译,花费的时间不少,效率不高,而且属于侵入性的修改,不优雅.本篇讲述如何使用 ...
随机推荐
- mysql 指定端口
mysql -P3307 -uemove -h180. -p #-P是指定端口
- -- Warning: Skipping the data of table mysql.event. Specify the --events option explicitly.
[root@DB ~]# mysqldump -uroot -p123 --flush-logs --all-databases >fullbackup_sunday_11_PM.sql -- ...
- 创建型模式之Strategy模式
应用场景 实现某一个功能有多种算法或者策略,我们可以根据环境或者条件的不同选择不同的算法或者策略来完成该功能.如编写排序算法,可以将这些算法写到一个类中,在该类中提供多个方法,每一个方法对应一个具体的 ...
- Stringbuffer与Stringbuilder源码学习和对比
>>String/StringBuffer/StringBuilder的异同 (1)相同点观察源码会发现,三个类都是被final修饰的,是不可被继承的.(2)不同点String的对象是不可 ...
- Man简单介绍
转自:http://os.51cto.com/art/201312/425525.htm Linux系统提供了相对比较丰富的帮助手册(man),man是manual的缩写,在日常linux系统管理中经 ...
- SURF算法与源码分析、上
如果说SIFT算法中使用DOG对LOG进行了简化,提高了搜索特征点的速度,那么SURF算法则是对DoH的简化与近似.虽然SIFT算法已经被认为是最有效的,也是最常用的特征点提取的算法,但如果不借助于硬 ...
- Java正则表达式, 提取双引号中间的部分
String str="this is \"Tom\" and \"Eric\", this is \"Bruce lee\", ...
- loadrunner解决“服务器正在运行中”方法
问题现象: 这个问题在上家公司遇见过,今天无意中找到了解决办法: 解决方法: 打开任务管理器: 找到这个进程:ThumbProcess.exe,关掉这个进程即可解决. 今天运行lr的vugen报错 解 ...
- packge-info.java
packge-info.java是一个Java文件,可以添加到任何的Java源码包中.packge-info.java的目标是提供一个包级的文档说明或者是包级的注释. packge-info.java ...
- mysql之对索引的操作
1. 为什么使用索引? 数据库对象索引与书的目录非常类似,主要是为了提高从表中检索数据的速度.由于数据储存在数据库表中,所以索引是创建在数据库表对象之上的,由表中的一个字段或多个字段生成的键组成,这些 ...