论文笔记:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
ICML, 2015
S. Ioffe and C. Szegedy
解决什么问题(What)
- 分布不一致导致训练慢:每一层的分布会受到前层的影响,当前层分布发生变化时,后层网络需要去适应这个分布,训练时参数的变化会导致各层分布的不断变化,这个问题被定义为“internal covariate shift”,由于每一层的分布不一样,就会导致训练很慢
- 梯度消失和梯度爆炸:深度网络中微小的参数变动引起梯度上的剧变,导致训练陷入sigmoid的饱和区
- 需要使用较小的学习率:大的学习率可能会导致参数的scale变大,导致bp时梯度放大,引起梯度爆炸。另外由于分布不一致,大的学习率容易导致分布变化不稳定
- 需要小心翼翼地设置权重初始化:设置合理的初始化权重可以减小陷入sigmoid饱和区导致的梯度消失或梯度爆炸
- 需要正则:防止过拟合,提高泛化能力
为什么能解决(Why)
- 加速收敛:在每一层的输入对数据进行规范化,使每层的分布不会出现很大的差异,可以加快训练。BN因为对数据分布做了规范,能减小前层对后层的影响,后层更容易适应前层的更新。
- 减小梯度消失和梯度爆炸:对于sigmoid来说,数据规范化后大部分落在sigmoid的中间区域,可以避免优化的时候陷入“saturated regime”(sigmoid的两边),能够减小梯度消失的出现。一般化地说(不仅考虑sigmoid),BN规范化后,对于较大的权重会有较小的梯度,对于较小的权重会有较大的梯度(如下面公式所示),不容易出现梯度消失或梯度爆炸)。
\[ BN(Wu) =BN((aW)u) \]
\[ \frac{\partial BN((aW)u))}{\partial u}=\frac{\partial BN((W)u))}{\partial u} \]
\[ \frac{\partial BN((aW)u))}{\partial (aW)} = \frac{1}{a} \frac{\partial BN(Wu))}{\partial W} \] - 允许使用较大的学习率:BN使训练更适应参数的scale,大权重有小梯度,这就不怕大的学习率导致bp的梯度放大引起梯度爆炸。另外分布较为一致,较大的学习率也不会导致不稳定的学习
- 可以不需要小心翼翼地设置权重初始化:初始化对学习的影响减小了,可以不那么小心地设置初始权重。举例来说,对于一个单元的输入值,不管权重w,还是放缩后的权重kw,BN过后的值都是一样的,这个k被消掉了,对于学习来说,激活值是一样的。
- 减小对正则的需要: 对于一个给定的训练样本,网络不产生一个确定的值,它会依赖于mini-batch中的其它样本。论文的实验发现这种效应有利于网络的泛化,可以减小或者不用dropout。
BN是怎么做的(How)
- 对于一个神经元的一个mini-batch上的一批数据,做一次BN,假设batch size为m
- 先求mini-batch的均值: \[\mu\leftarrow \frac{1}{m}\sum_{m}^{i=1}x_{i}\]
- 然后求mini-batch的方差:\[\sigma ^{2}\leftarrow \frac{1}{m}\sum_{m}^{i=1}(x_{i}-\mu)^{2}\]
- 然后把每个数据归一化:\[\hat{x_i}\leftarrow \frac{x_i - \mu}{\sqrt {\sigma ^{2} + \varepsilon }}\]
- 这样就得到了均值为0,方差为1的一批数据。我们可能不希望所有的数据总是均值为0,方差为1。这可能会改变原来的网络层能表示的东西,比如把sgmoid限制在了0附近的线性区域。所有我们使用另外两个参数来转换一下,使得网络能学到更多的分布。它既可以保持原输入,也可以改变,提升了模型的容纳能力。\[y_i\leftarrow \gamma \hat{x_i}+\beta \equiv BN_{\gamma, \beta}(x_i)\]
- 对每个神经元的每个mini-batch数据做这样的BN转换,然后训练,每个BN的参数\(\gamma, \beta\)不同
- 在测试阶段,由于我们不适用mini-batch,那么如何使用均值和方差来归一化呢,论文中给出的方法是使用所有mini-batch 的均值和方差来估计出两个统计量(用移动平均的计算方法来平均,指数加权平均是常用的一种移动平均的方法)来作为每个测试样本BN时的均值和方差。指数加权平均在ng的深度学习课程中有学习过,我有记录相应的课程笔记。
\[E[x]\leftarrow E_B[\mu_B]\]
\[Var[x]\leftarrow \frac{m}{m-1}E_B[\sigma ^{2}_B]\]
\[y = \frac{x-E(x)}{\sqrt{Var[x]+\varepsilon }}\gamma+\beta\]
激活前还是激活后做BN(Where)
- 对于一个神经元的运算$ x = Wu+b $ 和 $ z = g(x) $,g为激活函数
- 可以对u做BN,也可以对x做BN
- 但是u可能是另一个非线性函数的输出,它的分布容易受到训练的影响而改变
- 而\(Wu+b\)更可能有一致的,非稀疏的分布,对它归一化更可能产生稳定的分布
实验小结
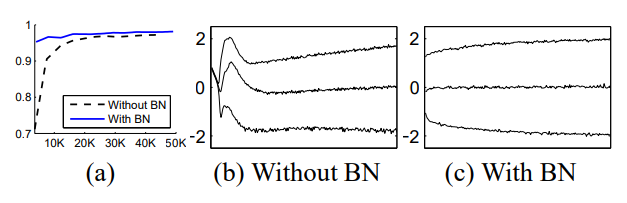
mnist:用了BN后,收敛更快,准确率更高,随着训练的进行,分布更加平稳
- ImageNet单网络分类:
- Inception:学习率为0.0015,对Inceptionv1做了一些结构修改(比如2个3x3卷积替代5x5卷积)。
- BN:在上面的基础上加入了BN,提升了Inception的收敛速度和准确率
- BNx5:做了一些加速BN的策略变动,其中学习率扩大为原BN的5倍,即0.0075,相比于BN,收敛更快,准确率更高
- BNx30:在BNx5的基础上,学习率扩大为原BN的30倍,即0.045,相比于BNX5,准确率更高
- BNx5-sigmoid:虽然不如以上结果好,但是相比于不用BN,准确率更高

ImageNet集成网络分类:使用带BN的集成的Inception,在ImageNet的validation上达到了最好的表现
其它:CNN中的BN
- 在CNN中对一个mini-batch中的一个feature map的所有单元做BN
- 假设原来一个mini-batch中的大小为m,做BN时,一批数据的大小为m
- 现在在CNN中,假设一个feature map中大小为p*q,则做BN时一批数据的大小为m*p*q
其它:Internal Covariate shift(ICS)
统计学习基于这样一个假设,希望源空间和目标空间的分布是一致的,covariate shift是分布不一致假设之下的一个分支问题,指的是条件概率一致,但是边缘概率不同,如下公式所示
\[P_{source}(Y|X=x)=P_{target}(Y|X=x)\]
\[P_{source}(X)\neq P_{target}(X)\]
神经网络各层的分布是不同的,但是同一样本的label是一致,这就是符合了covariate shift的定义,因为不止对于输入,而对于中间层的输入都有这个问题,所有在前面加个“internal covariate shift”,定义这个各层之间分布不一致的问题。BN可以减小ICS带来的影响,但是不是解决ICS的办法,因为这并没有保证各层的分布一致,只是规范化了均值和方差。
一点点小感受
- 通常来说BN和dropout都是很有用的trick,值得多多尝试
- 但是之前做实验的时候,发现加了BN效果反而下降了,还有dropout也是,加了后没提升
- 一些trick在你的数据和任务上并不一定总是work的,还是实践至上,要多跑实验,尝试各种配置
论文笔记:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift的更多相关文章
- Deep Learning 27:Batch normalization理解——读论文“Batch normalization: Accelerating deep network training by reducing internal covariate shift ”——ICML 2015
这篇经典论文,甚至可以说是2015年最牛的一篇论文,早就有很多人解读,不需要自己着摸,但是看了论文原文Batch normalization: Accelerating deep network tr ...
- Batch normalization:accelerating deep network training by reducing internal covariate shift的笔记
说实话,这篇paper看了很久,,到现在对里面的一些东西还不是很好的理解. 下面是我的理解,当同行看到的话,留言交流交流啊!!!!! 这篇文章的中心点:围绕着如何降低 internal covari ...
- 图像分类(二)GoogLenet Inception_v2:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception V2网络中的代表是加入了BN(Batch Normalization)层,并且使用 2个 3*3卷积替代 1个5*5卷积的改进版,如下图所示: 其特点如下: 学习VGG用2个 3* ...
- Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift(BN)
internal covariate shift(ics):训练深度神经网络是复杂的,因为在训练过程中,每层的输入分布会随着之前层的参数变化而发生变化.所以训练需要更小的学习速度和careful参数初 ...
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
1. 摘要 训练深层的神经网络非常困难,因为在训练的过程中,随着前面层数参数的改变,每层输入的分布也会随之改变.这需要我们设置较小的学习率并且谨慎地对参数进行初始化,因此训练过程比较缓慢. 作者将这种 ...
- Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanish ...
- 论文笔记之:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation xx
- 【转载】论文笔记系列-Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
一. 引出主题¶ 深度学习领域一直存在一个比较严重的问题——“灾难性遗忘”,即一旦使用新的数据集去训练已有的模型,该模型将会失去对原数据集识别的能力.为解决这一问题,本文提出了树卷积神经网络,通过先将 ...
- 【网络优化】Batch Normalization(inception V2) 论文解析(转)
前言 懒癌翻了,这篇不想写overview了,公式也比较多,今天有(zhao)点(jie)累(kou),不想一点点写latex啦,读论文的时候感觉文章不错,虽然看似很多数学公式,其实都是比较基础的公式 ...
随机推荐
- string类(三、string.format格式字符串)
参考连接: http://www.cnblogs.com/luluping/archive/2009/04/30/1446665.html http://blog.csdn.net/samsone/a ...
- STL 源代码剖析 算法 stl_algo.h -- inplace_merge
本文为senlie原创.转载请保留此地址:http://blog.csdn.net/zhengsenlie inplace_merge(应用于有序区间) ----------------------- ...
- iOS开发之-- textview 光标起始位置偏移
使用textview的时候,会发生光标偏移的情况,其实是因为iOS7里导航栏,状态栏等有个边缘延伸的效果在. 把边缘延伸关掉就好了.代码如下 //取消iOS7的边缘延伸效果(例如导航栏,状态栏等等) ...
- [Docker]——container和主机(host)之间的文件拷贝
1. 从 container 到 主机(host) 使用 docker cp 命令 docker cp <containerId>:/file/path/within/container ...
- 160419、CSS3实现32种基本图形
CSS3可以实现很多漂亮的图形,我收集了32种图形,在下面列出.直接用CSS3画出这些图形,要比贴图性能更好,体验更加,是一种非常好的网页美观方式. 这32种图形分别为圆形,椭圆形,三角形,倒三角形, ...
- Java switch 详解
switch 语句由一个控制表达式和多个case标签组成. switch 控制表达式支持的类型有byte.short.char.int.enum(Java 5).String(Java 7). swi ...
- Spring的泛型依赖注入
Spring 4.x 中可以为子类注入子类对应的泛型类型的成员变量的引用,(这样子类和子类对应的泛型类自动建立关系)具体说明: 泛型注入:就是Bean1和Bean2注入了泛型,并且Bean1和Bean ...
- js 一些基础知识
数据类型: 作用域 每个函数都有自己的执行环境,执行环境定义了变量有权访问的其他数据,决定了他们各自的行为. 每个执行环境都有一个与之关联的变量对象(variable object),环境中定义的所有 ...
- CSDN BI Flume
https://so.csdn.net/so/search/s.do?q=bytebuf&t=%20&u=
- PHP 创建中文目录的情况
因为一个作业需要创建一些中文的目录,其实主要还是考虑一下编码问题. 首先确认下系统环境是什么编码,如果是gbk或者GB2312那就需要转下码,还有些特殊字符,就需要有个特殊的写法. iconv('UT ...