java数据结构和算法学习笔记
第一章 什么是数据结构和算法
数据结构的概述
数据结构是指 数据再计算机内存空间或磁盘空间中的组织形式
1.数据结构的特性
| 数据结构 | 优点 | 缺点 |
| 数组 | 插入快,如果知道下标可以快速存取 | 查找和删除慢 大小固定 |
| 有序数组 | 比无序数组查找快 | 插入和删除慢 大小固定 |
| 栈 | 后进先出 | 存取其他项很慢 |
| 队列 | 先进先出 | 存取其他项很慢 |
| 链表 | 插入和删除快 | 查找慢 |
| 二叉树 | 查找,插入,删除都快(如果保持平衡) | 删除算法复杂 |
| 红黑树 | 查找,插入,删除都快 树总是是平衡的 | 算法复杂 |
| 2-3-4树 | 查找,插入,删除都快 树总是平衡的 类似的数对磁盘存储有用 | 算法复杂 |
| 哈希表 | 如果key已知则存取快,插入快 | 删除慢 如果key不知存取慢 空间利用不足 |
| 堆 | 插入 删除快,对最大数据存取快 | 对其他项存取慢 |
| 图 | 实现世界建模 | 有些算法慢 且 复杂 |
算法概述
算法是完成特定任务的过程
database 数据库
record 记录
field 字段
key 关键字
java基本数据类型
int ,short, char ,byte, long ,double, float,boolean

java 数据结构的类库
java.until.*;
第二章 数组
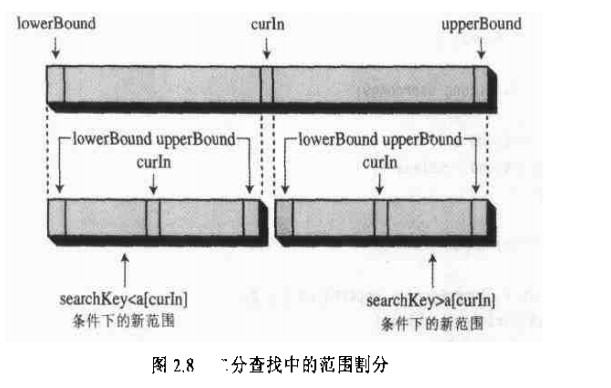
1.有序数组二分法查找
public class SortArray {
private int[] values = {2, 11, 44, 55, 357,358,400,414,505};
//查找某值得索引
private int find(int searchValue) {
//|----------------------|
//lower--> <--upper
int lowerBound = 0;
int upperBound = values.length - 1;
int current;
while (true) {
current = (lowerBound + upperBound) / 2;
//值判断
if(values[current]==searchValue){
return current;
}else if(lowerBound>upperBound){
//索引判断
return -1;//can't find 跳出循环
}else {
if(values[current]>searchValue){
//<--- upper (upper向内移动)
upperBound=current-1;
}else {
//lower---> (lower向内移动)
lowerBound=current+1;
}
}
}
}
@Test
public void test_find() {
System.out.println(find(44));
System.out.println(find(358));
System.out.println(find(111));
}
}
二分法查找与 log(N)成正比

大 O 表示法 不要常数

O(1)是优秀
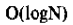 性能良好
性能良好
O(N) 性能一般
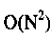 性能较差
性能较差
大O时间图(时间受数据项个数影响):
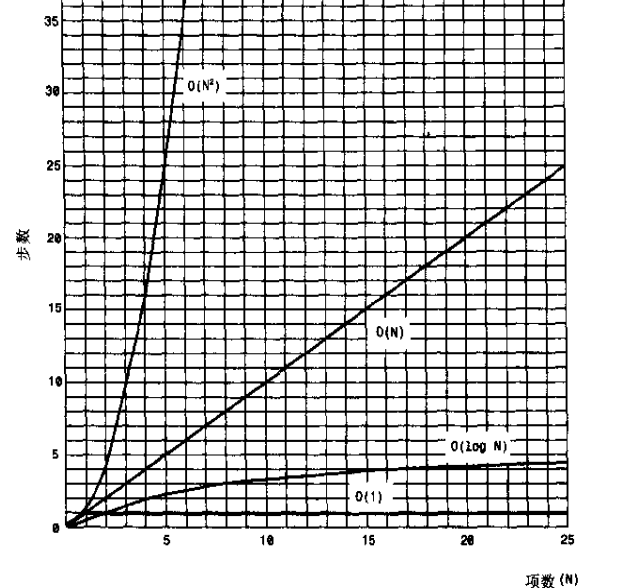
无序数组 快速插入 查找删除慢
有序数据 可以使用二分法查找
第三章 简单排序
简单排序包括
- 冒泡排序
- 选择排序
- 插入排序
一般的排序 方法 (CAS : compare and swap)
1.比较两个数据项
2.交换两个数据项,或复制其中一项
冒泡排序
冒泡排序就是 比较相邻 大的往右冒泡
1.比较两个队员
2.如果左边的大 则交换位置
3.向右移一个位置 一次比较下面两个
4.一直比较下去。。。。
(每个的左边 和其右边进行比较)

。。。。。。
。。。。。。

冒泡排序第一趟 (挑出最大值)
冒泡排序java代码
bubble [ˈbəbəl] 冒泡
public class BubbleSort {
private int[] buildIntArray(int size){
int[] arr=new int[size];
for(int i=0;i<size;i++){
arr[i]= RandomUtils.nextInt(1,100);
}
return arr;
}
/*
冒泡排序
大的值往右冒泡
*/
public void bubble(int[] arr){
int out,in,temp;
//第一趟 最大的已经冒泡到最右边, 所以第二趟不用再排。 减掉 out--
for(out=arr.length-1;out>0;out--){
//从左到右依次冒泡 所以 从0 依次比较
for(in=0;in<out;in++){
//往右冒泡 若左边大于右边 冒泡
if(arr[in]>arr[in+1]){
temp=arr[in+1];
arr[in+1]=arr[in];
arr[in]=temp;
}
}
}
}
@Test
public void testSort(){
int []arr=buildIntArray(9);
System.out.println(Arrays.toString(arr));
bubble(arr);
System.out.println(Arrays.toString(arr));
}
}
冒泡排序的 时间级别
第一趟 需要比较 n-1次
第二趟 需要比较 n-2次
第三趟 需要比较 n-3次
。。。。。
=n(n-1)/2;
约为 N的平方
所以冒泡排序的时间复杂度 为 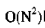
选择排序
选择排序改进了冒泡排序
选择排序: 就是查找选择最小值 放在最左边,这样左边的就排好序了
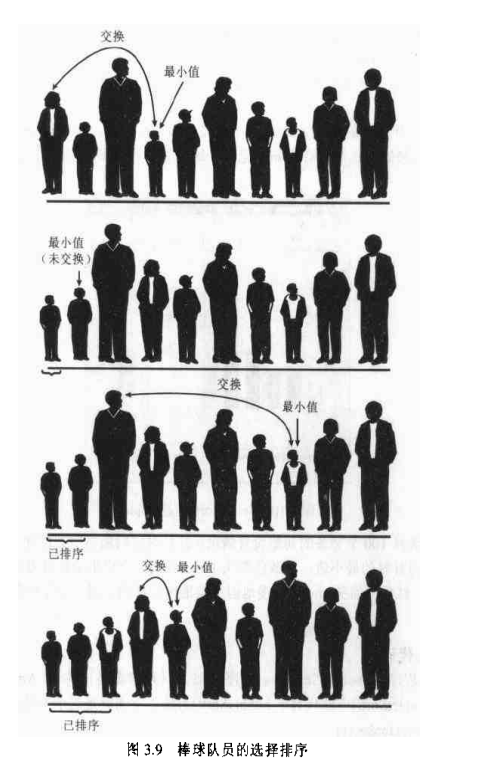
选择排序java代码
public class SelectSort {
private int[] buildIntArray(int size) {
int[] arr = new int[size];
for (int i = 0; i < size; i++) {
arr[i] = RandomUtils.nextInt(1,100);
}
return arr;
}
/*
选择排序
选出最小的放在左边
*/
private void select(int[] arr) {
int out, in, temp;
//左边是排好序的 不用排了 所以out++
for (out = 0; out < arr.length - 1; out++) {
//out 左边是排好了的 比较 out以后的
for (in = out + 1; in < arr.length; in++) {
//out是左边的值,in是右边的值 因为 in=out+1
//如果 右边的值小 把它交换到左边
if (arr[in] < arr[out]) {
temp = arr[in];
arr[in] = arr[out];
arr[out] = temp;
}
}
}
}
@Test
public void testSort() {
int[] arr = buildIntArray(9);
System.out.println(Arrays.toString(arr));
select(arr);
System.out.println(Arrays.toString(arr));
}
}
选择 排序 时间复杂度 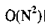
但是选择排序的速度快于冒泡排序 因为它进行的交换次数少;
插入排序
插入排序 一般情况下 比冒泡排序快一倍 ,比选择排序还要快一点
采用 局部有序 的方法
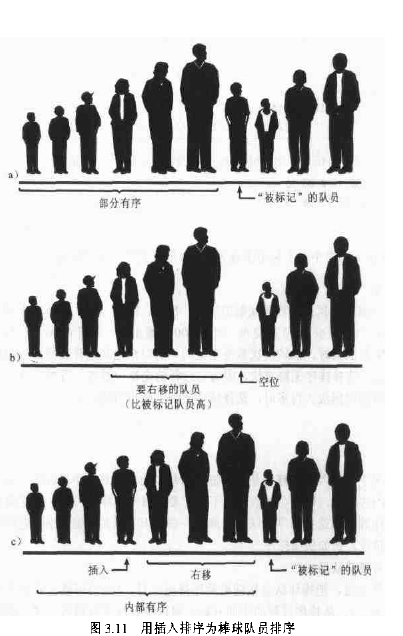
java代码
public class InsertSort {
private int[] buildIntArray(int size) {
int[] arr = new int[size];
for (int i = 0; i < size; i++) {
arr[i] = RandomUtils.nextInt(0,100);
}
return arr;
}
public void insert(int[] arr){
int in,out;
//外围的 循环次数 逐渐增加, 因为 左边排好的个数逐渐增加
for(out=1;out<arr.length;out++){
int temp=arr[out];//被标记的值,要排序的值
in=out;//和左边已经排好的值 进行比较
//从最大值 依次向左 逐个比较
// 如果 左边的最大值 大于 temp ,再往左 找个小的值 和 temp比较
//while 没我大 排到后面去
while (in>0&&arr[in-1]>=temp){
arr[in]=arr[in-1];
--in;
}
arr[in]=temp;
}
}
@Test
public void testSort() {
int[] arr = buildIntArray(9);
System.out.println(Arrays.toString(arr));
insert(arr);
System.out.println(Arrays.toString(arr));
}
}
插入排序的时间复杂度也是 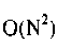
第四章 栈和队列
受限访问 ,更加抽象 作为构思算法的辅助工具
栈(stack)
后进先出
栈只允许访问一个数据项,即最后插入的数据项。移除第一个数据项后 ,才可以访问第二个数据项。
- 用栈来检测 源程序中的 小括号,大括号 是否匹配
- 用栈来辅助遍历树的节点
- 微处理器运用栈的体系架构
用数组实现一个简单的栈
peek [pēk] :窥视
public class StackA {
private int[] arr;
private int max;
private int top;
public StackA(int max) {
this.max = max;
this.arr=new int[max];
this.top=-1;
}
public void push(int v){
arr[++top]=v;
}
public int pop(){
return arr[top--];
}
/*
Look at the obj at the top of stack without remove it
*/
public int peek(){
return arr[top];
}
public boolean isEmpty(){
return top==-1;
}
public boolean isFull(){
return top==max-1;
}
}
测试
public void test(){
StackA stackA=new StackA(7);
stackA.push(1);
stackA.push(2);
stackA.push(3);
stackA.push(4);
stackA.push(5);
while (!stackA.isEmpty()){
System.out.println(stackA.pop());
}
}
写个demo检测 输入内容的 括号是否正确
bracket [ˈbrakit] : 括号
public class Bracket {
private String input;
public Bracket(String input) {
this.input = input;
}
public void check() {
if (StringUtils.isNotBlank(input)) {
StackA stackA = new StackA(input.length());
for (int i = 0; i < input.length(); i++) {
char c = input.charAt(i);
switch (c) {
case '{':
case '[':
case '(':
stackA.push(c);
break;
case '}':
case ']':
case ')':
if (!stackA.isEmpty()) {
char store = (char) stackA.pop();
if ((c == '}' && store != '{')
|| (c == ']' && store != '[')
|| (c == ')' && store != '(')
) {
System.out.println("Error " + c + " at " + i);
return;
}
} else {
System.out.println("Error " + c + " at " + i);
return;
}
break;
default:
break;
}
}
if (!stackA.isEmpty()) {
System.out.println("Error no bracket match with " + (char) stackA.peek());
}
}
}
}
测试
public void test(){
Bracket bracket=new Bracket("test(just test}");
bracket.check();
bracket=new Bracket("test :just test {");
bracket.check();
}
运行结果

java数据结构和算法学习笔记的更多相关文章
- 《Java数据结构与算法》笔记-CH4-2用栈实现字符串反转
import java.io.BufferedReader; import java.io.InputStreamReader; //用栈来实现一个字符串逆序算法 /** * 数据结构:栈 */ cl ...
- 《Java数据结构与算法》笔记-CH4-3用栈实现分隔符匹配
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; /** * 利 ...
- 《Java数据结构与算法》笔记-CH3简单排序
class ArrayBub { private long[] arr; private int nElement; public ArrayBub(int size) { arr = new lon ...
- 《Java数据结构与算法》笔记-CH1
/** * 数据结构的特性 ************************************************************************************** ...
- 《Java数据结构与算法》笔记-CH5-链表-4用链表实现堆栈
//用链表实现堆栈 /** * 节点类 */ class LinkS { private long data; public LinkS next; public LinkS(long d) { th ...
- 《Java数据结构与算法》笔记-CH5-链表-3双端链表
/** * 双端链表的实现 */ class LinkA { public long dData; public LinkA next; public LinkA(long d) { dData = ...
- 《Java数据结构与算法》笔记-CH5-链表-2单链表,增加根据关键字查找和删除
/** * Link节点 有数据项和next指向下一个Link引用 */ class Link { private int iData;// 数据 private double dData;// 数据 ...
- 《Java数据结构与算法》笔记-CH5-链表-1单链表
/** * Link节点 * 有数据项和next指向下一个Link引用 */ class Link { private int iData;//数据 private double dData;//数据 ...
- 《java数据结构与算法》笔记-CH4-8栈结构实现后缀表达式计算结果
/** * 中缀表达式转换成后缀表达式: 从输入(中缀表达式)中读取的字符,规则: 操作数: 写至输出 左括号: 推其入栈 右括号: 栈非空时重复以下步骤--> * 若项不为(,则写至输出: 若 ...
随机推荐
- TIMER_PWM_CAPTURE
- bootstrap导航条相关知识
在导航条(navbar)中有一个背景色.而且导航条可以是纯链接(类似导航),也可以是表单,还有就是表单和导航一起结合等多种形式. 为导航条添加标题.二级菜单及状态 <div class=&quo ...
- 关于如何在服务器上搭建tomcat并发布自己的web项目
最近在学习如何在服务起上搭建tomcat,并发布自己的项目,自己是花了一下午的时间才把里面的东西弄明白,各种百度,各种请教大神,真的是备受折磨啊.好了废话不多说,直接进入主题. 1:众所周知,tomc ...
- [GO]等待时间的使用
package main import ( "time" "fmt" ) func main() { <-time.After(*time.Second) ...
- ibatis源码学习2_初始化和配置文件解析
问题在详细介绍ibatis初始化过程之前,让我们先来思考几个问题. 1. ibatis初始化的目标是什么?上文中提到过,ibatis初始化的核心目标是构造SqlMapClientImpl对象,主要是其 ...
- [修正] Firemonkey 中英文混排折行,省略字符,首字避开标点
问题:FMX 在移动平台的文字显示并非由该平台的原生 API 来显示,而是由 FMX.TextLayout.GPU 来处理,也许是官方没留意到中文字符的问题,造成在中英文混排折行时,有些问题. 修正: ...
- Oracle觸發器調用procedure寄信
最近寫了一直Web Service給很多不同站的客戶端呼叫,并直接寄信通知程式中的異常. 直接在oracle中設置某張表的trigger(after insert),當有新的異常資料寫入時候,寄給相關 ...
- [LINK]List of .NET Dependency Injection Containers (IOC)
http://www.hanselman.com/blog/ListOfNETDependencyInjectionContainersIOC.aspx I'm trying to expand my ...
- Docker 1.3.3/1.4.0 发布下载,Linux 容器引擎
Docker 1.3.3 发布,下载地址: https://github.com/docker/docker/archive/v1.3.3.zip 改进记录包括: Security Fix path ...
- HttpWebRequest(System.Net)模拟HTTP发送POST
相关参考网上很多,但需要理解并转成自己的情况 public static string HttpWebRequestPost(string url, string param) { HttpWebRe ...