基于Scrapy框架的Python新闻爬虫
概述
详细
一、开发背景
Python作为数据处理方面的一把好手,近年来的热度不断增长。网络爬虫可以说是Python最具代表性的应用之一,那么通过网络爬虫来学习Python以及网络和数据处理的相关内容可以说是再合适不过了。
Scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。相比于传统的爬虫来说,基于scrapy框架的爬虫更加结构化,同时也更加高效,能完成更加复杂的爬取任务。
二、爬虫效果
1、标题

2、内容

3、评论
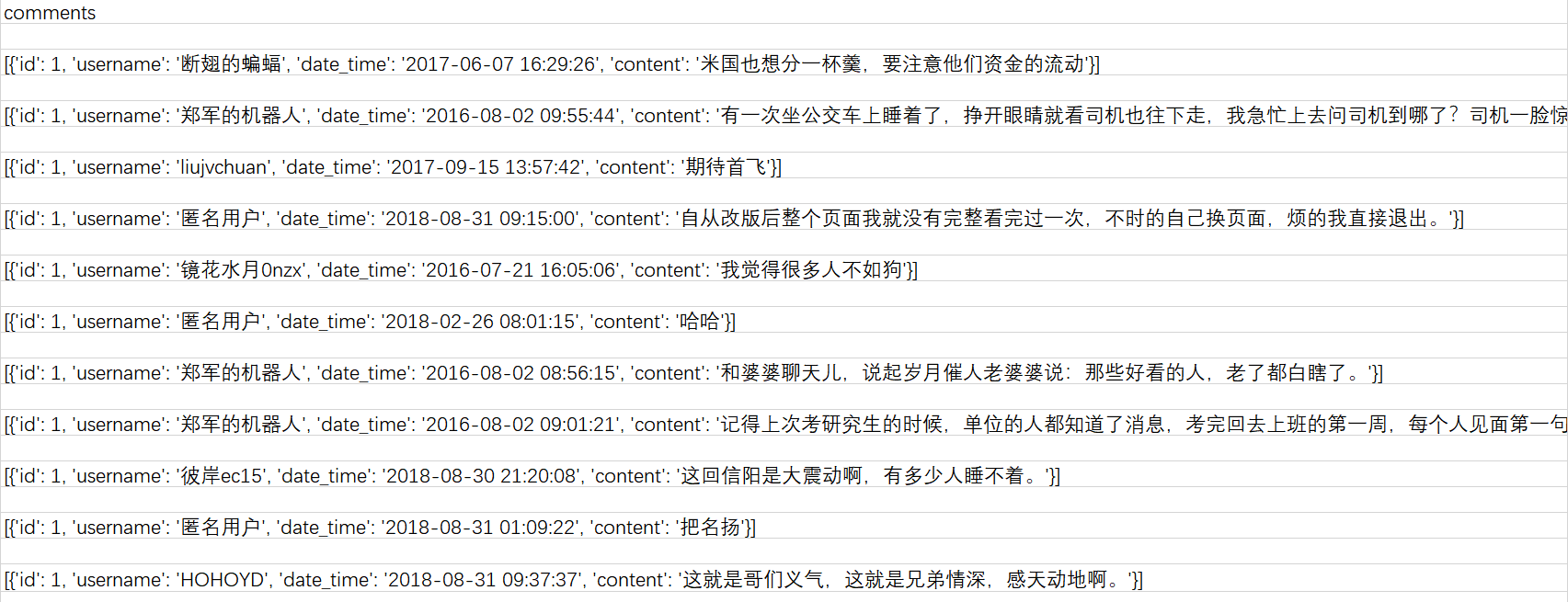
4、日期,热度和ID
5、程序运行图
三、具体开发
1、任务需求
1. 爬取网易,搜狐,凤凰和澎湃新闻网站的文章及评论
2. 新闻网页数目不少于10万页
3. 每个新闻网页及其评论能在1天内更新
2、功能设计
1. 设计一个网络爬虫,能够爬取指定网站的全部页面,并提取其中的文章及评论内容
2. 定时运行网络爬虫,实现每日更新数据
3、系统架构
首先简单介绍下scrapy框架,这是一个爬虫框架
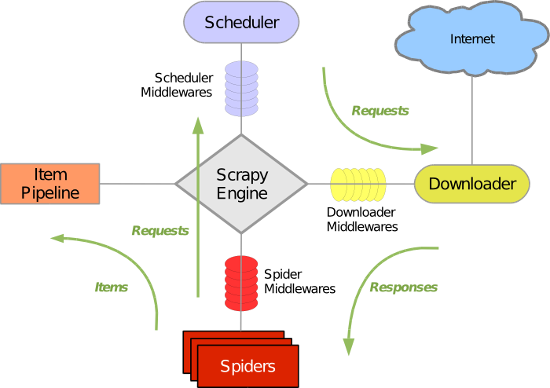
绿线是数据流向,
(1)首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,
(2)下载之后会交给 Spider 进行分析,这里的spider就是爬虫的核心功能代码
(3)Spider分析出来的结果有两种:一种是需要进一步抓取的链接,它们会通过middleware传回 Scheduler ;另一种是需要保存的数据,送入Item Pipeline ,进行处理和存储
(4)最后将所有数据输出并保存为文件
4、实际项目
(1)项目结构
可以看到,NewsSpider-master是完整项目文件夹,下面存放有对应各个网站的爬虫启动脚本debug_xx.py,scrapyspider文件夹存放scrapy框架所需的相关文件,spiders文件夹存放实际的爬虫代码
(2)爬虫引擎
以网易新闻的爬虫news_163.py为例,简要说明部分核心代码:
①定义一个爬虫类:
class news163_Spider(CrawlSpider):
# 网易新闻爬虫名称
name = "163news"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
#网易全网
allowed_domains = [
"163.com"
]
#新闻版
start_urls = [
'http://news.163.com/'
]
#正则表达式表示可以继续访问的url规则,http://news.163.com/\d\d\d\d\d(/([\w\._+-])*)*$
rules = [
Rule(LinkExtractor(
allow=(
('http://news\.163\.com/.*$')
),
deny = ('http://.*.163.com/photo.*$')
),
callback="parse_item",
follow=True)
]
②网页内容分析模块
根据不同内容的Xpath路径从页面中提取内容,由于网站在不同时间的页面结构不同,因此按照不同页面版式划分成几个if判断句块;
def parse_item(self, response):
# response是当前url的响应
article = Selector(response)
article_url = response.url
global count
# 分析网页类型
# 比较新的网易新闻 http://news.163.com/05-17/
if get_category(article) == 1:
articleXpath = '//*[@id="epContentLeft"]'
if article.xpath(articleXpath):
titleXpath = '//*[@id="epContentLeft"]/h1/text()'
dateXpath = '//*[@id="epContentLeft"]/div[1]/text()'
contentXpath = '//*[@id="endText"]'
news_infoXpath ='//*[@id="post_comment_area"]/script[3]/text()' # 标题
if article.xpath(titleXpath):
news_item = newsItem()
news_item['url'] = article_url
get_title(article, titleXpath, news_item)
# 日期
if article.xpath(dateXpath):
get_date(article, dateXpath, news_item)
# 内容
if article.xpath(contentXpath):
get_content(article, contentXpath, news_item)
count = count + 1
news_item['id'] = count
# 评论
try:
comment_url = get_comment_url(article, news_infoXpath)
# 评论处理
comments = get_comment(comment_url, news_item)[1]
news_item['comments'] = comments
except:
news_item['comments'] = ' '
news_item['heat'] = 0
yield news_item
根据正则表达式匹配页面内容中的日期信息:
'''通用日期处理函数'''
def get_date(article, dateXpath, news_item):
# 时间
try:
article_date = article.xpath(dateXpath).extract()[0]
pattern = re.compile("(\d.*\d)") # 正则匹配新闻时间
article_datetime = pattern.findall(article_date)[0]
#article_datetime = datetime.datetime.strptime(article_datetime, "%Y-%m-%d %H:%M:%S")
news_item['date'] = article_datetime
except:
news_item['date'] = '2010-10-01 17:00:00'
其他函数:
'''网站分类函数'''
def get_category(article): '''字符过滤函数'''
def str_replace(content): '''通用正文处理函数'''
def get_content(article, contentXpath, news_item): '''评论信息提取函数'''
def get_comment_url(article, news_infoXpath): '''评论处理函数'''
def get_comment(comment_url, news_item):
(3)运行爬虫并格式化存储
①在settings.py中进行配置
import sys
# 这里改成爬虫项目的绝对路径,防止出现路径搜索的bug
sys.path.append('E:\Python\以前的项目\\NewsSpider-master\scrapyspider') # 爬虫名称
BOT_NAME = 'scrapyspider' # 设置是否服从网站的爬虫规则
ROBOTSTXT_OBEY = True # 同时并发请求数,越大则爬取越快同时负载也大
CONCURRENT_REQUESTS = 32 #禁止cookies,防止被ban
COOKIES_ENABLED = False # 输出的编码格式,由于Excel默认是ANSI编码,所以这里保持一致
# 如果有其他编码需求如utf-8等可自行更改
FEED_EXPORT_ENCODING = 'ANSI' # 增加爬取延迟,降低被爬网站服务器压力
DOWNLOAD_DELAY = 0.01 # 爬取的新闻条数上限
CLOSESPIDER_ITEMCOUNT = 500 # 下载超时设定,超过10秒没响应则放弃当前URL
DOWNLOAD_TIMEOUT = 100
ITEM_PIPELINES = {
'scrapyspider.pipelines.ScrapyspiderPipeline': 300,# pipeline中的类名
}
②运行爬虫并保存新闻内容
爬取下来的新闻内容及评论需要格式化存储,如果在IDE中运行debug脚本,则效果如下:
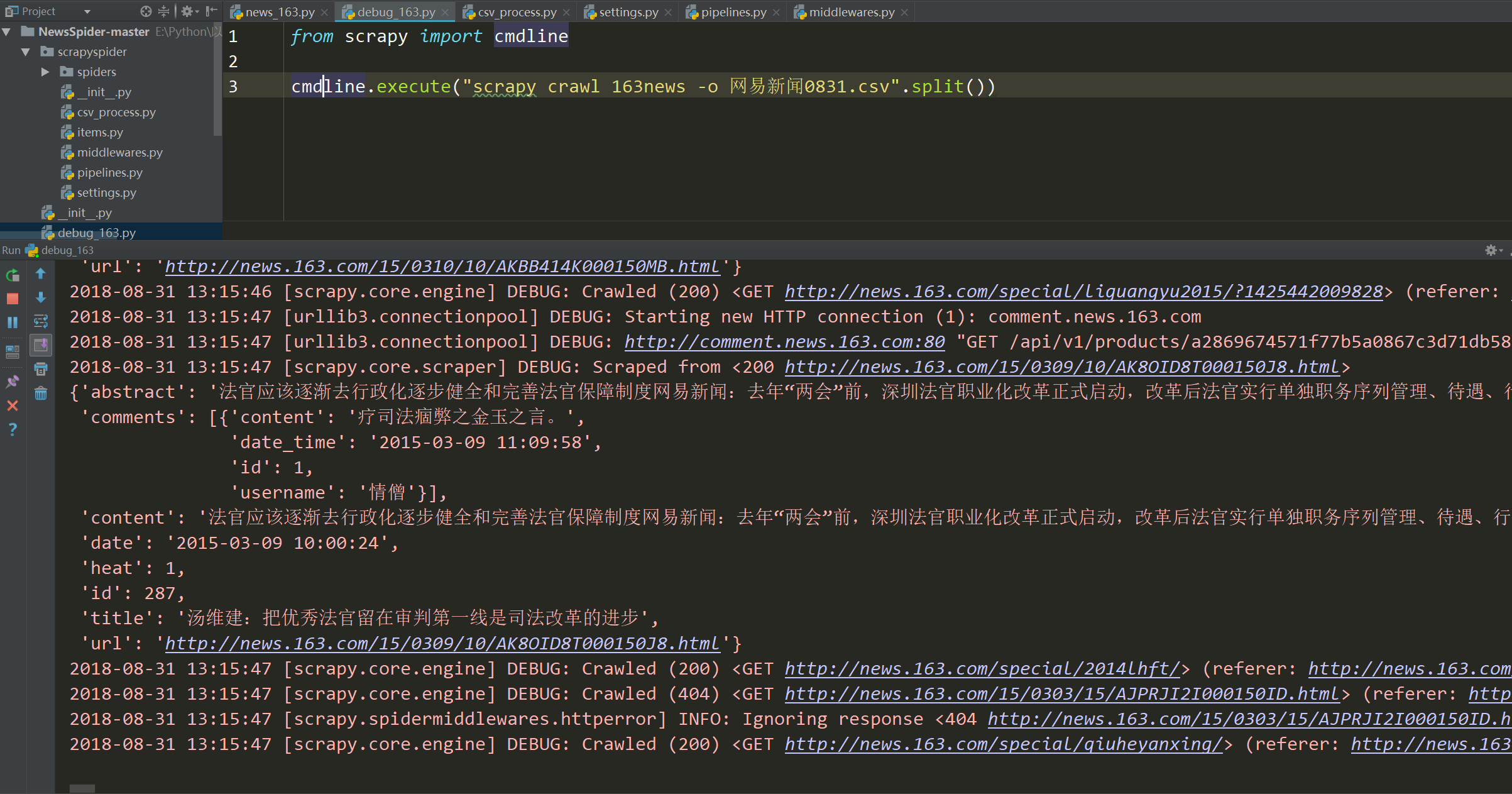
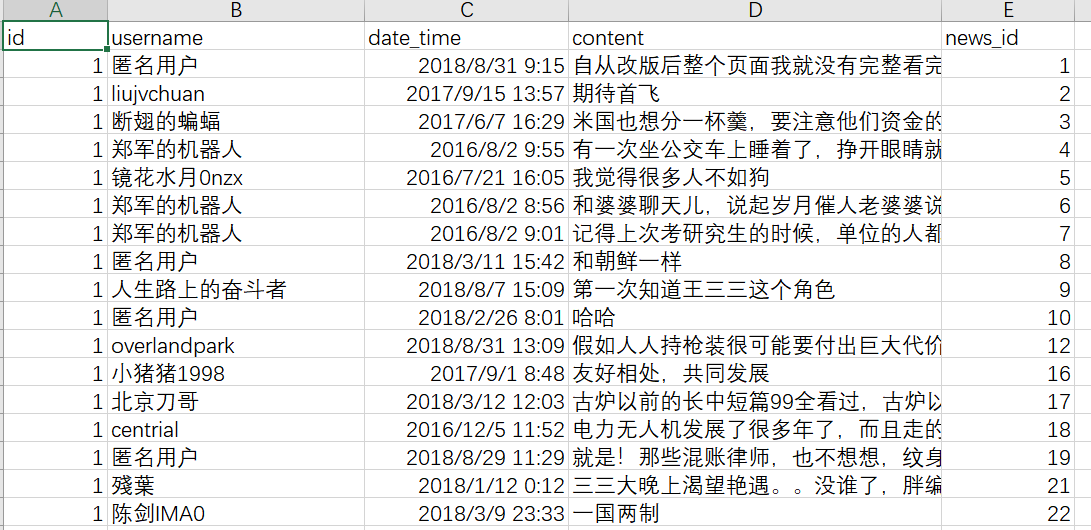
爬取后会保存为.csv文件,使用Excel打开即可查看:
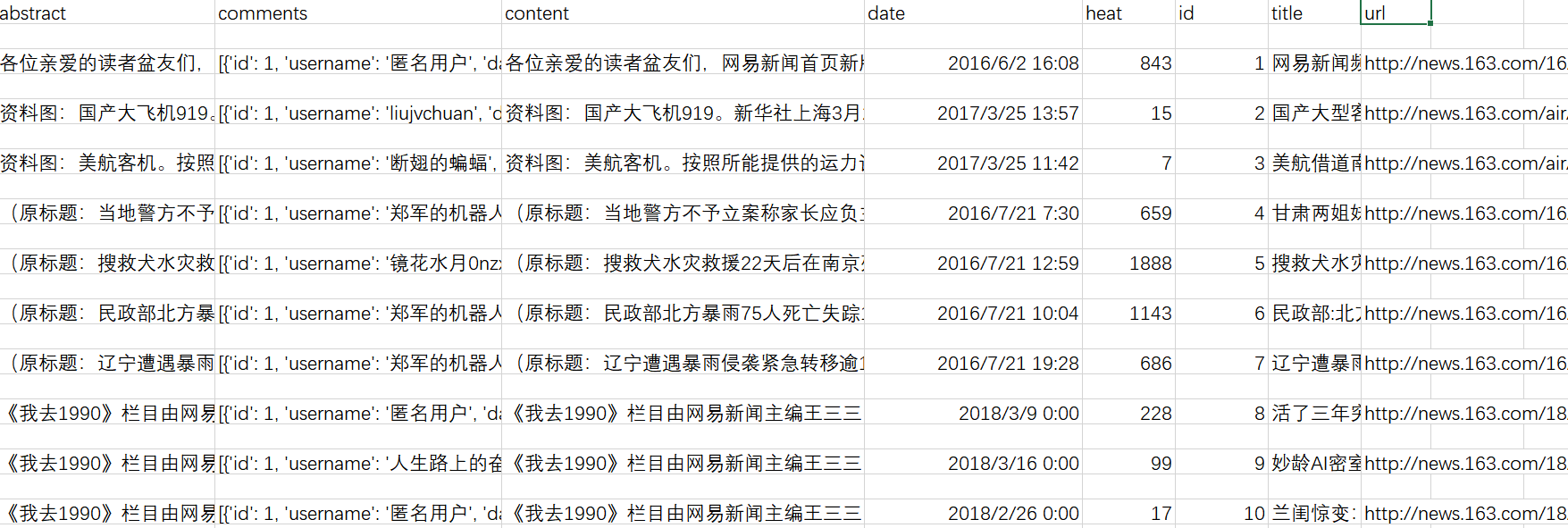
③如果需要将评论单独提取出来,可以使用csv_process.py,效果如下:
四、其他补充
暂时没有
注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权
基于Scrapy框架的Python新闻爬虫的更多相关文章
- 基于Scrapy框架的增量式爬虫
概述 概念:监测 核心技术:去重 基于 redis 的一个去重 适合使用增量式的网站: 基于深度爬取的 对爬取过的页面url进行一个记录(记录表) 基于非深度爬取的 记录表:爬取过的数据对应的数据指纹 ...
- 基于scrapy框架的爬虫
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. scrapy 框架 高性能的网络请求 高性能的数据解析 高性能的 ...
- 使用scrapy框架做赶集网爬虫
使用scrapy框架做赶集网爬虫 一.安装 首先scrapy的安装之前需要安装这个模块:wheel.lxml.Twisted.pywin32,最后在安装scrapy pip install wheel ...
- 基于scrapy框架输入关键字爬取有关贴吧帖子
基于scrapy框架输入关键字爬取有关贴吧帖子 站点分析 首先进入一个贴吧,要想达到输入关键词爬取爬取指定贴吧,必然需要利用搜索引擎 点进看到有四种搜索方式,分别试一次,观察url变化 我们得知: 搜 ...
- 基于scrapy框架的分布式爬虫
分布式 概念:可以使用多台电脑组件一个分布式机群,让其执行同一组程序,对同一组网络资源进行联合爬取. 原生的scrapy是无法实现分布式 调度器无法被共享 管道无法被共享 基于 scrapy+redi ...
- 基于scrapy框架的爬虫基本步骤
本文以爬取网站 代码的边城 为例 1.安装scrapy框架 详细教程可以查看本站文章 点击跳转 2.新建scrapy项目 生成一个爬虫文件.在指定的目录打开cmd.exe文件,输入代码 scrapy ...
- Scrapy框架实战-妹子图爬虫
Scrapy这个成熟的爬虫框架,用起来之后发现并没有想象中的那么难.即便是在一些小型的项目上,用scrapy甚至比用requests.urllib.urllib2更方便,简单,效率也更高.废话不多说, ...
- scrapy框架解读--深入理解爬虫原理
scrapy框架结构图: 组成部分介绍: Scrapy Engine: 负责组件之间数据的流转,当某个动作发生时触发事件 Scheduler: 接收requests,并把他们入队,以便后续的调度 Do ...
- python基于scrapy框架的反爬虫机制破解之User-Agent伪装
user agent是指用户代理,简称 UA. 作用:使服务器能够识别客户使用的操作系统及版本.CPU 类型.浏览器及版本.浏览器渲染引擎.浏览器语言.浏览器插件等. 网站常常通过判断 UA 来给不同 ...
随机推荐
- LCA(最近公共祖先)--tarjan离线算法 hdu 2586
HDU 2586 How far away ? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/ ...
- [转]Android之Activity的几种跳转方式
1.显示调用方法 Intent intent=new Intent(this,OtherActivity.class); //方法1 Intent intent2=new Intent(); in ...
- PAT甲级1026. Table Tennis
PAT甲级1026. Table Tennis 题意: 乒乓球俱乐部有N张桌子供公众使用.表的编号从1到N.对于任何一对玩家,如果有一些表在到达时打开,它们将被分配给具有最小数字的可用表.如果所有的表 ...
- debian禁止或者允许指定ip访问远程mysql、ssh、rsynccat /etc/xinetd.conf
如果没有安装xinetd,安装xinetd apt-get install xinetd 然后创建配置文件 vi /etc/xinetd.d/mysqld service login { socket ...
- OpenVPN Server端配置文件详细说明(转)
本文将介绍如何配置OpenVPN服务器端的配置文件.在Windows系统中,该配置文件一般叫做server.ovpn:在Linux/BSD系统中,该配置文件一般叫做server.conf.虽然配置文件 ...
- WICED™ <SMART> Software Development Kit
WICED™ Software Development Kit The WICED™ SDK includes the tools and software needed to create Wi-F ...
- Visual Studio删除所有的注释和空行
visual studio用"查找替换"来删掉源代码中所有//方式的纯注释和空行 注意:包括/// <summary>这样的XML注释也都删掉了. 步骤1/2(删除注释 ...
- visual studio 2008试用版的评估期(万能破解)
教程 http://jingyan.baidu.com/article/a3a3f811ee87268da2eb8ae7.html 参考: http://blog.chinaunix.net/uid- ...
- Wix使用整理(二)
1) 安装卸载时进行日志记录 Wix 制作的 Installer 的调试很麻烦,没有直接的 Bug 工具,可以通过记录安装日志的方式进行间接调试.命令为 msiexec /i pack ...
- [翻译] YLGIFImage 高效读取GIF图片
YLGIFImage 高效读取GIF图片 https://github.com/liyong03/YLGIFImage Asynchronized GIF image class and Image ...