【Lucene】Apache Lucene全文检索引擎架构之入门实战1
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。——《百度百科》
这篇博文主要从两个方面出发,首先介绍一下Lucene中的全文搜索原理,其次通过程序示例来展现如何使用Lucene。关于全文搜索原理部分我上网搜索了一下,也看了好几篇文章,最后在写这篇文章的时候部分参考了其中两篇(地址我放在文章的末尾),感谢原文作者。
1. 全文检索
何为全文检索?举个例子,比如现在要在一个文件中查找某个字符串,最直接的想法就是从头开始检索,查到了就OK,这种对于小数据量的文件来说,很实用,但是对于大数据量的文件来说,就有点呵呵了。或者说找包含某个字符串的文件,也是这样,如果在一个拥有几十个G的硬盘中找那效率可想而知,是很低的。
文件中的数据是属于非结构化数据,也就是说它是没有什么结构可言的,要解决上面提到的效率问题,首先我们得即将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这就叫全文搜索。即先建立索引,再对索引进行搜索的过程。
那么lucene中是如何建立索引的呢?假设现在有两个文档,内容如下:
文章1的内容为:Tom lives in Guangzhou, I live in Guangzhou too.
文章2的内容为:He once lived in Shanghai.
首先第一步是将文档传给分词组件(Tokenizer),分词组件会将文档分成一个个单词,并去除标点符号和停词。所谓的停词指的是没有特别意义的词,比如英文中的a,the,too等。经过分词后,得到词元(Token) 。如下:
文章1经过分词后的结果:[Tom] [lives] [Guangzhou] [I] [live] [Guangzhou]
文章2经过分词后的结果:[He] [lives] [Shanghai]
然后将词元传给语言处理组件(Linguistic Processor),对于英语,语言处理组件一般会将字母变为小写,将单词缩减为词根形式,如”lives”到”live”等,将单词转变为词根形式,如”drove”到”drive”等。然后得到词(Term)。如下:
文章1经过处理后的结果:[tom] [live] [guangzhou] [i] [live] [guangzhou]
文章2经过处理后的结果:[he] [live] [shanghai]
最后将得到的词传给索引组件(Indexer),索引组件经过处理,得到下面的索引结构:
| 关键词 | 文章号[出现频率] | 出现位置 |
|---|---|---|
| guangzhou | 1[2] | 3,6 |
| he | 2[1] | 1 |
| i | 1[1] | 4 |
| live | 1[2],2[1] | 2,5,2 |
| shanghai | 2[1] | 3 |
| tom | 1[1] | 1 |
以上就是lucene索引结构中最核心的部分。它的关键字是按字符顺序排列的,因此lucene可以用二元搜索算法快速定位关键词。实现时lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)和位置文件(positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
搜索的过程是先对词典二元查找、找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果,然后就可以在具体的文章中根据出现位置找到该词了。所以lucene在第一次建立索引的时候可能会比较慢,但是以后就不需要每次都建立索引了,就快了。当然了,这是针对英文的检索,针对中文的规则会有不同,后面我再看看相关资料。
2. 示例代码
根据上文的分析,全文检索有两个步骤,先建立索引,再检索。所以为了测试这个过程,我写了两个java类,一个是测试建立索引的,另一个是测试检索的。首先建立个maven工程,pom.xml如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.shanheyongmu.cn</groupId>
<artifactId>Lucene</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>war</packaging> <dependencies> <!-- lucene核心包 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.3.1</version>
</dependency>
<!-- lucene查询解析包 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.3.1</version>
</dependency>
<!-- lucene解析器包 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.3.1</version>
</dependency> </dependencies>
</project>
在写程序之前,首先得去弄一些文件,我随便找了一些英文的文档(中文的后面再研究),放到了D:\lucene\data\目录中,如下:

文档里面都是密密麻麻的英文,我就不截图了。
接下来开始写建立索引的java程序:
package org.shanheyongmu.cn;
import java.io.File;
import java.io.FileReader;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; /**
*
* @description 建立索引的类
* @author zzy
* @date 2016年9月21日
*/
public class Indexer { private IndexWriter writer;//写索引实例 //构造方法,实例化IndexWriter
public Indexer(String indexDir) throws Exception{
Directory dir=FSDirectory.open(Paths.get(indexDir));
Analyzer analyzer=new StandardAnalyzer();//标准分词器,会自动去掉空格,is a the等单词
IndexWriterConfig config=new IndexWriterConfig(analyzer);//将标准分词器配到写索引的配置中
writer=new IndexWriter(dir, config);//实例化写索引对象 } //关闭写索引
public void close() throws Exception{
writer.close();
} //索引指定目录下的所有文件
public int indexAll(String dataDir) throws Exception{
File[] files=new File(dataDir).listFiles();//获取该路径下的所有文件
for(File file:files){
indexFile(file);//调用下面的indexFile方法,对每个文件进行索引
}
return writer.numDocs();//返回索引的文件数
}
//索引指定的文件
private void indexFile(File file) throws Exception {
System.out.println("索引文件的路径:"+file.getCanonicalPath());
Document doc=getDocument(file);//获取该文件的document
writer.addDocument(doc);//调用下面的getDocument方法,将doc添加到索引中 }
//获取文档,文档里再设置每个字段,就类似于数据库中的一行记录
private Document getDocument(File file) throws Exception {
Document doc=new Document();
//添加字段
doc.add(new TextField("contents",new FileReader(file)));//添加内容
doc.add(new TextField("fileName", file.getName(),Field.Store.YES));//添加文件名,并把这个字段存到索引文件里
doc.add(new TextField("fullPath", file.getCanonicalPath(),Field.Store.YES));//添加文件路径
return doc;
} public static void main(String[] args){ String indexDir="D:\\lucene";//将索引保存到的路径
String dataDir="D:\\lucene\\data";//需要索引的文件数据存放的目录
Indexer indexer=null;
int indexedNum=0;
long startTime=System.currentTimeMillis();//记录索引开始时间 try{
indexer=new Indexer(indexDir);
indexedNum=indexer.indexAll(dataDir); }catch(Exception e){
e.printStackTrace();
}finally{
try {
indexer.close();
} catch (Exception e) { e.printStackTrace();
}
}
long endTime=System.currentTimeMillis();//记录索引结束时间
System.out.println("索引共耗时"+(endTime-startTime)+"毫秒");
System.out.println("共索引了"+indexedNum+"个文件");
}
}
我是按照建立索引的过程来写的程序,在注释中已经解释的很清楚了,这里就不再赘述了。然后运行一下main方法看一下结果,如下:
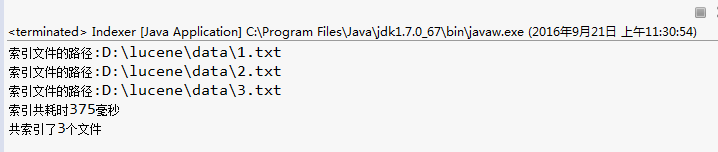
共索引了3个文件,耗时375毫秒,还是蛮快的,而且索引文件的路径也是对的,然后可以看一下D:\lucene\会生成一些文件,这些
就是生成的索引。 当你继续执行一次 建立索引 又会生成共6个文件

现在有了索引了,我们可以检索想要查询的字符了,我随便打开了一个文件,在里面找了个比较丑的字符串“clothes-that-inexpensive”来作为检索的对象。在检索之前先看一下检索的java代码:
package org.shanheyongmu.cn; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; public class Searcher { public static void search(String indexDir,String q) throws Exception{
Directory dir=FSDirectory.open(Paths.get(indexDir));//获取要查询的路径,也就是索引所在的位置
IndexReader reader=DirectoryReader.open(dir);
IndexSearcher searcher=new IndexSearcher(reader);
Analyzer analyzer=new StandardAnalyzer();//标准分词器,会自动去掉空格啊,is a too等单词
QueryParser parser=new QueryParser("contents", analyzer);//查询解析器器
Query query=parser.parse(q);//通过解析要查询的String,获取查询对象 long startTime=System.currentTimeMillis();//记录索引开始时间
TopDocs docs=searcher.search(query, 10);//开始查询,查询前10条数据 将记录在docs中
long endTime=System.currentTimeMillis();//记录索引结束时间
System.out.println("匹配到"+q+"共耗时"+(endTime-startTime)+"毫秒");
System.out.println("查询到"+docs.totalHits+"条记录"); for(ScoreDoc scoreDoc:docs.scoreDocs){//取出每条查询结果
Document doc=searcher.doc(scoreDoc.doc);//scoreDoc.doc相当于docID,根据这个docID来获取文档
System.out.println(doc.get("fullPath"));//fullPath是刚刚建立索引的时候我们定义的一个字段
}
reader.close();
}
public static void main(String[] args){
String indexDir="D:\\lucene";
String q="clothes-that-inexpensive";//查询这个字符串
try{
search(indexDir, q);
}catch(Exception e){
e.printStackTrace();
}
}
}

Lucene已经正确的帮我们检索到了,然后我把中间的“-”去掉,它也能帮我们检索到,但是我把前面的字符都去掉,只留下“pensive”就检索不到了,这也能说明Lucene中建立索引是以单词来划分的,但是这个问题是可以解决的,我会在后续的文章中写到。
本篇参考csdn eson
【Lucene】Apache Lucene全文检索引擎架构之入门实战1的更多相关文章
- Lucene作为一个全文检索引擎
Lucene作为一个全文检索引擎,其具有如下突出的优点: (1)索引文件格式独立于应用平台.Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件. ...
- 【Lucene】Apache Lucene全文检索引擎架构之构建索引2
上一篇博文中已经对全文检索有了一定的了解,这篇文章主要来总结一下全文检索的第一步:构建索引.其实上一篇博文中的示例程序已经对构建索引写了一段程序了,而且那个程序还是挺完善的.不过从知识点的完整性来考虑 ...
- 【Lucene】Apache Lucene全文检索引擎架构之中文分词和高亮显示4
前面总结的都是使用Lucene的标准分词器,这是针对英文的,但是中文的话就不顶用了,因为中文的语汇与英文是不同的,所以一般我们开发的时候,有中文的话肯定要使用中文分词了,这一篇博文主要介绍一下如何使用 ...
- 【Lucene】Apache Lucene全文检索引擎架构之搜索功能3
上一节主要总结了一下Lucene是如何构建索引的,这一节简单总结一下Lucene中的搜索功能.主要分为几个部分,对特定项的搜索:查询表达式QueryParser的使用:指定数字范围内搜索:指定字符串开 ...
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- Apache Lucene(全文检索引擎)—分词器
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- Apache Lucene(全文检索引擎)—搜索
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- 全文检索引擎 Lucene.net
全文搜索引擎是目前广泛应用的主流搜索引擎.它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行 ...
- Lucene:基于Java的全文检索引擎简介
Lucene:基于Java的全文检索引擎简介 Lucene是一个基于Java的全文索引工具包. 基于Java的全文索引/检索引擎--Lucene Lucene不是一个完整的全文索引应用,而是是一个用J ...
随机推荐
- 兼容ie7到ie11,edge,chrome,firefox的ajax发送接收post数据代码
/* * 生成XMLHttpRequest */ function getxhr() { //获取ajax对象 var xhr = null; try { xhr = new XDomainReque ...
- java1.7集合源码阅读:ArrayList
ArrayList是jdk1.2开始新增的List实现,首先看看类定义: public class ArrayList<E> extends AbstractList<E> i ...
- Java进阶之路,技术要点
宏观方面 一.JAVA.要想成为JAVA(高级)工程师肯定要学习JAVA.一般的程序员或许只需知道一些JAVA的语法结构就可以应付了.但要成为JAVA(高级)工程师,您要对JAVA做比较深入的研究.您 ...
- SqlServer 2014安装指引
具体步骤看整理的Word文档 链接:https://pan.baidu.com/s/1zOhaFVpro2DNnJlJ6dbSEg 密码:lj4m 具体步这里不介绍了,这里记录下报错信息 这个是说系统 ...
- HDU 6235.Permutation (2017中国大学生程序设计竞赛-哈尔滨站-重现赛)
Permutation Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Tot ...
- [BZOJ5289][HNOI2018]排列(拓扑排序+pb_ds)
首先确定将所有a[i]向i连边之后会形成一张图,图上每条有向边i->j表示i要在j之前选. 图上的每个拓扑序都对应一种方案(如果有环显然无解),经过一系列推导可以发现贪心策略与合并的块的大小和w ...
- 【bzoj1415】【聪聪和可可】期望dp(记忆化搜索)+最短路
[pixiv] https://www.pixiv.net/member_illust.php?mode=medium&illust_id=57148470 Descrition 首先很明显是 ...
- [POI2014]Beads
题目大意: 有$n(n\leq10^6)$种颜色,第$i$种颜色有$c_i(\sum c_i\leq10^6)$个,指定第一个颜色为$a$,最后一个颜色为$b$,问对于一个长度为$m=\sum c_i ...
- centos忘记密码,重新设置密码的方法
(1)重新启动Centos,在启动过程中,长按“ESC”键,进入GNU GRUB界面. (2)选择要进入的系统,按“E”键(在启动之前编辑命令). (3)选择第二项操作系统的内核“kernel”,按& ...
- sed 中如何替换换行符
使用如下解决方案: sed ':a;N;$!ba;s/\n/ /g' 这将在一个循环里读取整个文件,然后将换行符替换成一个空格. 说明: 通过 :a创建一个标记 通过N追加当前行和下一行到模式区域 如 ...