python+NLTK 自然语言学习处理六:分类和标注词汇一
在一段句子中是由各种词汇组成的。有名词,动词,形容词和副词。要理解这些句子,首先就需要将这些词类识别出来。将词汇按它们的词性(parts-of-speech,POS)分类并相应地对它们进行标注。这个过程叫做词性标注。
要进行词性标注,就需要用到词性标注器(part-of-speech tagger).代码如下
text=nltk.word_tokenize("customer found there are abnormal issue")
print(nltk.pos_tag(text))
提示错误:这是因为找不到词性标注器
LookupError:
**********************************************************************
Resource averaged_perceptron_tagger not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('averaged_perceptron_tagger')
Searched in:
- '/home/zhf/nltk_data'
- '/usr/share/nltk_data'
- '/usr/local/share/nltk_data'
- '/usr/lib/nltk_data'
- '/usr/local/lib/nltk_data'
- '/usr/nltk_data'
- '/usr/lib/nltk_data'
**********************************************************************
运行nltk.download进行下载,并将文件拷贝到前面错误提示的搜索路径中去,
>>> import nltk
>>> nltk.download('averaged_perceptron_tagger')
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] /root/nltk_data...
[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.
True
以及对应的帮助文档
>>> nltk.download('tagsets')
[nltk_data] Downloading package tagsets to /root/nltk_data...
[nltk_data] Unzipping help/tagsets.zip.
True
运行结果:
[('customer', 'NN'), ('found', 'VBD'), ('there', 'EX'), ('are', 'VBP'), ('abnormal', 'JJ'), ('issue', 'NN')]
在这里得到了每个词以及每个词的词性。下表是一个简化的词性标记集
|
标记 |
含义 |
例子 |
|
ADJ |
形容词 |
new, good, high, special, big, local |
|
ADV |
动词 |
really, already, still, early, now |
|
CNJ |
连词 |
and, or, but, if, while, although |
|
DET |
限定词 |
the, a, some, most, every, no |
|
EX |
存在量词 |
there, there’s |
|
FW |
外来词 |
dolce, ersatz, esprit, quo, maitre |
|
MOD |
情态动词 |
will, can, would, may, must, should |
|
N |
名词 |
year, home, costs, time, education |
|
NP |
专有名词 |
Alison, Africa, April, Washington |
|
NUM |
数词 |
twenty-four, fourth, 1991, 14:24 |
|
PRO |
代词 |
he, their, her, its, my, I, us |
|
P |
介词 |
on, of, at, with, by, into, under |
|
TO |
词 to |
to |
|
UH |
感叹词 |
ah, bang, ha, whee, hmpf, oops |
|
V |
动词 |
is, has, get, do, make, see, run |
|
VD |
过去式 |
said, took, told, made, asked |
|
VG |
现在分词 |
making, going, playing, working |
|
VN |
过去分词 |
given, taken, begun, sung |
|
WH |
Wh 限定词 |
who, which, when, what, where, how |
如果解析的对象是由单独的词/标记字符串构成的,可以用str2tuple的方法将词和标记解析出来并形成元组。使用方法如下:
[nltk.tag.str2tuple(t) for t in "customer/NN found/VBD there/EX are/VBP abnormal/JJ issue/NN".split()]
运行结果:
[('customer', None), ('found', None), ('there', None), ('are', None), ('abnormal', None), ('issue', None)]
对于在NLTK中自带的各种文本,也自带词性标记器
nltk.corpus.brown.tagged_words()
[('The', 'AT'), ('Fulton', 'NP-TL'), ...]
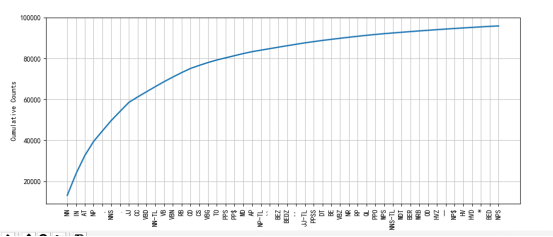
那么借助与Freqdist和以及绘图工具。我们就可以画出各个词性的频率分布图,便于我们观察句子结构
brown_news_tagged=nltk.corpus.brown.tagged_words(categories='news')
tag_fd=nltk.FreqDist(tag for (word,tag) in brown_news_tagged)
tag_fd.plot(50,cumulative=True)
结果如下,绘制出了前50个
假如我们正在学习一个词,想看下它在文本中的应用,比如后面都用的什么词。可以采用如下的方法,我想看下oftern后面都跟的是一些什么词语
brown_learned_text=nltk.corpus.brown.words(categories='learned')
ret=sorted(set(b for(a,b) in nltk.bigrams(brown_learned_text) if a=='often'))
在这里用到了bigrams方法,这个方法主要是形成双连词。
比如下面的这段文本,生成双连词
for word in nltk.bigrams("customer found there are abnormal issue".split()):
print(word)
结果如下:
('customer', 'found')
('found', 'there')
('there', 'are')
('are', 'abnormal')
('abnormal', 'issue')
光看后面跟了那些词语还不够,我们还需要查看后面的词语都是一些什么词性。
1 首先是对词语进行词性标记。形成词语和词性的二元组
2 然后根据bigrams形成连词,然后根据第一个词是否是often,得到后面词语的词性
brown_learned_text=nltk.corpus.brown.tagged_words(categories='learned')
tags=[b[1] for (a,b) in nltk.bigrams(brown_learned_text) if a[0]=='often']
fd=nltk.FreqDist(tags)
fd.tabulate()
结果如下:
VBN VB VBD JJ IN QL , CS RB AP VBG RP VBZ QLP BEN WRB . TO HV
15 10 8 5 4 3 3 3 3 1 1 1 1 1 1 1 1 1 1
同样的,如果我们想的到三连词, 可以采用trigrams的方法。
python+NLTK 自然语言学习处理六:分类和标注词汇一的更多相关文章
- python+NLTK 自然语言学习处理七:N-gram标注
在上一章中介绍了用pos_tag进行词性标注.这一章将要介绍专门的标注器. 首先来看一元标注器,一元标注器利用一种简单的统计算法,对每个标识符分配最有可能的标记,建立一元标注器的技术称为训练. fro ...
- NLTK学习笔记(五):分类和标注词汇
目录 词性标注器 标注语料库 表示已经标注的标识符:nltk.tag.str2tuple('word/类型') 读取已经标注的语料库 名词.动词.形容词等 尝试找出每个名词类型中最频繁的名词 探索已经 ...
- python+NLTK 自然语言学习处理八:分类文本一
从这一章开始将进入到关键部分:模式识别.这一章主要解决下面几个问题 1 怎样才能识别出语言数据中明显用于分类的特性 2 怎样才能构建用于自动执行语言处理任务的语言模型 3 从这些模型中我们可以学到那些 ...
- python+NLTK 自然语言学习处理:环境搭建
首先在http://nltk.org/install.html去下载相关的程序.需要用到的有python,numpy,pandas, matplotlib. 当安装好所有的程序之后运行nltk.dow ...
- python+NLTK 自然语言学习处理二:文本
在前面讲nltk安装的时候,我们下载了很多的文本.总共有9个文本.那么如何找到这些文本呢: text1: Moby Dick by Herman Melville 1851 text2: Sense ...
- python+NLTK 自然语言学习处理四:获取文本语料和词汇资源
在前面我们通过from nltk.book import *的方式获取了一些预定义的文本.本章将讨论各种文本语料库 1 古腾堡语料库 古腾堡是一个大型的电子图书在线网站,网址是http://www.g ...
- python+NLTK 自然语言学习处理五:词典资源
前面介绍了很多NLTK中携带的词典资源,这些词典资源对于我们处理文本是有大的作用的,比如实现这样一个功能,寻找由egivronl几个字母组成的单词.且组成的单词每个字母的次数不得超过egivronl中 ...
- python+NLTK 自然语言学习处理三:如何在nltk/matplotlib中的图片中显示中文
我们首先来加载我们自己的文本文件,并统计出排名前20的字符频率 if __name__=="__main__": corpus_root='/home/zhf/word' word ...
- Python+NLTK自然语言处理学习(一):环境搭建
Python+NLTK自然语言处理学习(一):环境搭建 参考黄聪的博客地址:http://www.cnblogs.com/huangcong/archive/2011/08/29/2157437.ht ...
随机推荐
- Kwickserver
Kwickserver 欢迎来到Kwickserver的主页 Kwickserver是什么? Kwickserver是一个易于安装的和易于使用的服务器应用程序,从CD安装在PC兼容的硬件和坚持webi ...
- Oracle 数据库监听配置
一.监听器(LISTENER) 监听器是Oracle基于服务器端的一种网络服务,主要用于监听客户端向数据库服务器端提出的连接请求.既然是基于服务器端的服务,那么它也只存在于数据库服务器端,进行监听器的 ...
- 利用gearman同步mysql数据到redis
一.Gearman 1.Gearman是一个分发任务的程序框架. 2.体系:a.client:发送一个jobb.server:找到合适的worker,把job交给该workerc.worker:处理j ...
- lodash 展平数组 flatten flattenDeep
_.flatten(array) 向上一级展平数组嵌套 <!DOCTYPE html> <html lang="zh"> <head> < ...
- 个人观点,说一下对 PHPCMS 的站点架构的看法
PHPCMS应该是国内第一家用MVC架构来写开源PHP产品的,我第一次工作上接触到PHPCMS是在两年前.那个时候对MVC还是不理解,然后由于工作须要,须要改动一下PHPCMS的源代码.拿到代码后.我 ...
- (四)Thymeleaf标准表达式之——[3->6] 操作符(文本、算术、布尔、比较及相等)
2.3 文本操作符 模板名称:text.html 连接符: + 可以是任意字符和表达式等 文本替换符:| 不能表达出条件表达式(官网:只能是变量表达式) e.g. 1.<span th ...
- chrome使用
本文转载于http://www.cnblogs.com/tester-l/p/5743031.html Chrome调试工具各个工具的作用: Element Elements板块你可以看到整个页面的D ...
- OSX: 命令行制作U盘Recovery HD
使用命令行操作,非常easy,可是操作不当非常危急! 免责声明:假设操作不当造成的数据丢失,本人概不负责. 为什么? 不是有OSX恢复磁盘助理嘛?是的.假设仅仅想使用GUI的软件.能够去苹果官方站点: ...
- CentOS上yum安装Nginx服务
一.更改yum源为网易的源加快速度 vi /etc/yum.repos.d/CentOS-Base.repo更改内容如下 # CentOS-Base.repo # # This file uses a ...
- C# 接口中的索引器
索引器可在 接口(C# 参考) 上声明.接口索引器的访问器与类索引器的访问器具有以下方面的不同: 接口访问器不使用修饰符. 接口访问器没有体. 因此,访问器的用途是指示索引器是读写.只读还是只写.以下 ...