Spark SQL利器:cacheTable/uncacheTable










Spark SQL利器:cacheTable/uncacheTable的更多相关文章
- Spark SQL利器:cacheTable/uncacheTable【转】
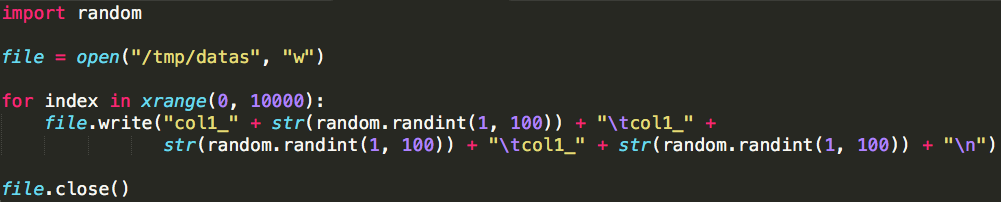
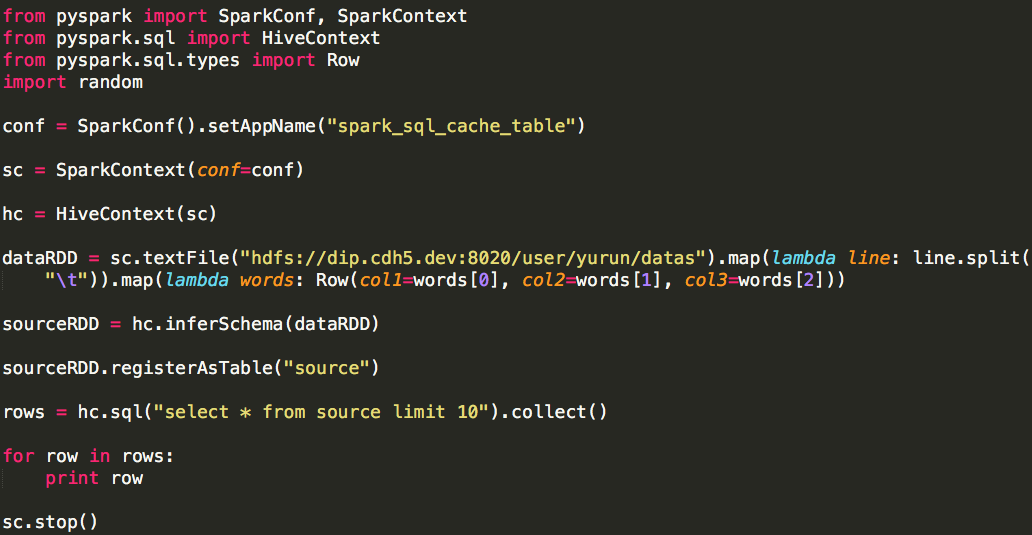
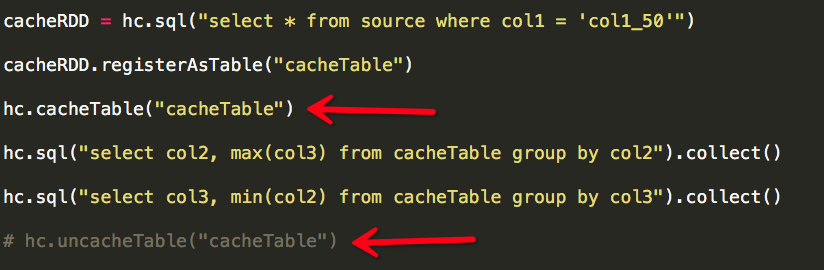
转自:http://www.cnblogs.com/yurunmiao/p/4936583.html Spark相对于Hadoop MapReduce有一个很显著的特性就是“迭代计算”(作为一个Map ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
- spark sql cache
1.几种缓存数据的方法 例如有一张hive表叫做activity 1.CACHE TABLE //缓存全表 sqlContext.sql("CACHE TABLE activity" ...
- Spark SQL 初步
已经Spark Submit 2013哪里有介绍Spark SQL.就在很多人都介绍Catalyst查询优化框架.经过一年的发展后,.今年Spark Submit 2014在.Databricks放弃 ...
- Spark SQL笔记——技术点汇总
目录 概述 原理 组成 执行流程 性能 API 应用程序模板 通用读写方法 RDD转为DataFrame Parquet文件数据源 JSON文件数据源 Hive数据源 数据库JDBC数据源 DataF ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
随机推荐
- 移动web前端小结(一)
这段时间做了几个移动项目的前端页面,姑且称之webapp.做这几个项目之前根本没接触过移动端的相关知识,以为和PC端页面没啥区别无非就是尺寸小一点罢了.上手以后发现问题颇多.下面从框架.相关知识点.遇 ...
- 一个js 变量作用域问题
一个js 域问题,有一本书 叫 javasrcip pattert 好像是,写的很好,, <!DOCTYPE html> <html> <head lang=" ...
- Spring3 + Spring MVC+ Mybatis 3+Mysql 项目整合
项目环境背景: 操作系统:win7 JDK:1.7 相关依赖包,截图如下:
- Session,ViewState用法
基本理论: session值是保存在服务器内存上,那么,可以肯定,大量的使用session将导致服务器负担加重. 而viewstate由于只是将数据存入到页面隐藏控件里,不再占用服务器资源,因此, ...
- js 配置基础启动文件
页面启动文件boot.js,获取存放该文件的路径,放置通用的css,js代码,方便html页面调用. __CreateJSPath = function (js) { var scripts = do ...
- NFC手机
NFC手机 NFC手机内置NFC芯片,比原先仅作为标签使用的RFID更增加了数据双向传送的功能,这个进步使得其更加适合用于电子货币支付:特别是RFID所不能实现的,相互认证和动态加密以及一次性钥匙(O ...
- window.clearInterval与window.setInterval的用法(
window.setInterval() 功能:按照指定的周期(以毫秒计)来调用函数或计算表达式. 语法:setInterval(code,millisec) 解释:code:在定时时间到时要执行的J ...
- Windows服务安装方法
操作系统:Win8.1 安装方法:在命令行窗口中输入:InstallUtil service.exe 出错原因:需要以管理员身份启动命令行.
- iOS中的几种定时器详解
在软件开发过程中,我们常常需要在某个时间后执行某个方法,或者是按照某个周期一直执行某个方法.在这个时候,我们就需要用到定时器. 然而,在iOS中有很多方法完成以上的任务,经过查阅资料,大概有三种方法: ...
- 数据库(学习整理)----1--如何彻底清除系统中Oracle的痕迹(重装Oracle时)
1.关于重装Oracle数据库: 由于以前装过Oracle数据库,但是版本不怎么样,结果过了试用期之后,我就没有破解和再找合适的版本了!直接使用电脑管家卸载了!可想而知,肯定没清除Oracle痕迹啊! ...