Spark SQL利器:cacheTable/uncacheTable【转】
转自:http://www.cnblogs.com/yurunmiao/p/4936583.html










Spark SQL利器:cacheTable/uncacheTable【转】的更多相关文章
- Spark SQL利器:cacheTable/uncacheTable
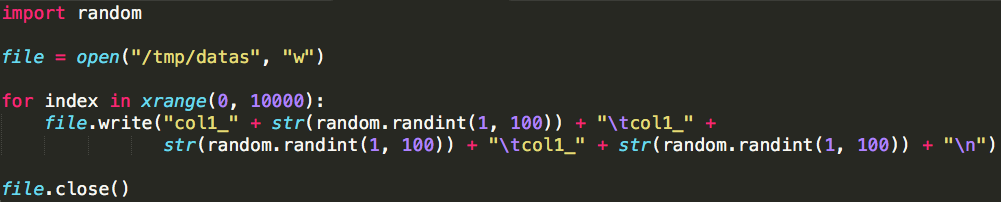
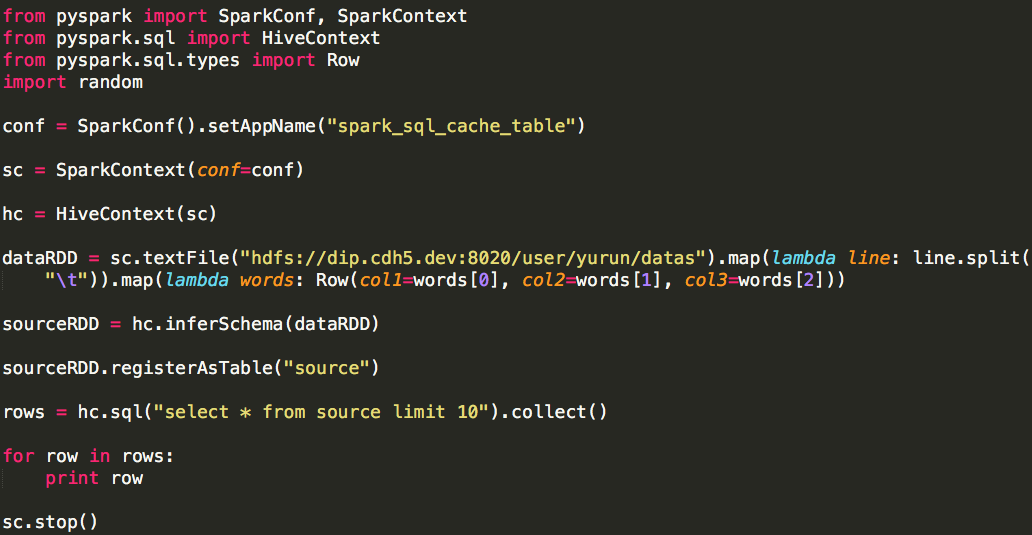
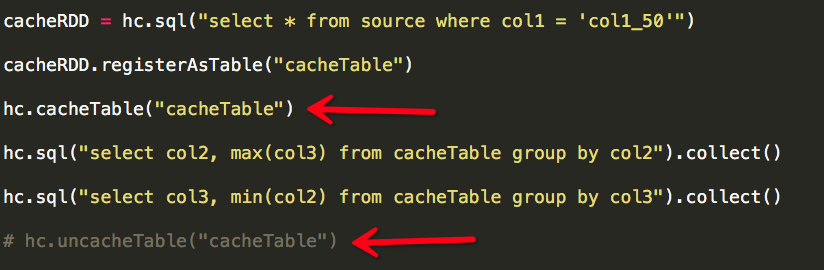
Spark相对于Hadoop MapReduce有一个很显著的特性就是“迭代计算”(作为一个MapReduce的忠实粉丝,能这样说,大家都懂了吧),这在我们的业务场景里真的是非常有用. 假设我们有 ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
- spark sql cache
1.几种缓存数据的方法 例如有一张hive表叫做activity 1.CACHE TABLE //缓存全表 sqlContext.sql("CACHE TABLE activity" ...
- Spark SQL 初步
已经Spark Submit 2013哪里有介绍Spark SQL.就在很多人都介绍Catalyst查询优化框架.经过一年的发展后,.今年Spark Submit 2014在.Databricks放弃 ...
- Spark SQL笔记——技术点汇总
目录 概述 原理 组成 执行流程 性能 API 应用程序模板 通用读写方法 RDD转为DataFrame Parquet文件数据源 JSON文件数据源 Hive数据源 数据库JDBC数据源 DataF ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
随机推荐
- FTP命令字和响应码解释
FTP命令: 命令 描述 ABOR 中断数据连接程序 ACCT <account> 系统特权帐号 ALLO <bytes> 为服务器上的文件存储器分配字节 APPE &l ...
- Easyui入门视频教程 第10集---Messager的使用
Easyui入门视频教程 第10集---Messager的使用 <script type="text/javascript"> function show(){ $.m ...
- tensorflow中的sequence_loss_by_example
在编写RNN程序时,一个很常见的函数就是sequence_loss_by_example loss = tf.contrib.legacy_seq2seq.sequence_loss_by_examp ...
- 使用Cygwin登录Raspberry PI
偿试了很多ssh终端程序,像ScureCRT,Putty,SSHSecureShellClient,SSH Client Tunnelier,每个工具都有自己的特点,putty对中文的支持还算好的,其 ...
- 【解决问题】failed: java.lang.RuntimeException: org.openqa.selenium.WebDriverException: Unexpected error launching Internet Explorer.
failed: java.lang.RuntimeException: org.openqa.selenium.WebDriverException: Unexpected error launchi ...
- 转:Spring Cache抽象详解
缓存简介 缓存,我的理解是:让数据更接近于使用者:工作机制是:先从缓存中读取数据,如果没有再从慢速设备上读取实际数据(数据也会存入缓存):缓存什么:那些经常读取且不经常修改的数据/那些昂贵(CPU/I ...
- HDU 1023 Train Problem II (大数卡特兰数)
Train Problem II Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- webpack window 安装loader
1.安装loadernpm install css-loader style-loader --save-dev 2.配置loader,在webpack.config.js中 module: { lo ...
- k8s实战之Service
一.概述 为了适应快速的业务需求,微服务架构已经逐渐成为主流,微服务架构的应用需要有非常好的服务编排支持,k8s中的核心要素Service便提供了一套简化的服务代理和发现机制,天然适应微服务架构,任何 ...
- Javascript将html转成pdf,下载(html2canvas 和 jsPDF)
最近碰到个需求,需要把当前页面生成pdf,并下载.弄了几天,自己整理整理,记录下来,我觉得应该会有人需要 :) 项目源码地址:https://github.com/linwalker/render-h ...