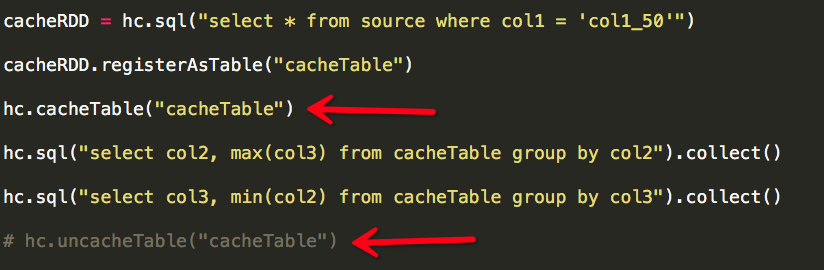
Spark SQL利器:cacheTable/uncacheTable










Spark SQL利器:cacheTable/uncacheTable的更多相关文章
- Spark SQL利器:cacheTable/uncacheTable【转】
转自:http://www.cnblogs.com/yurunmiao/p/4936583.html Spark相对于Hadoop MapReduce有一个很显著的特性就是“迭代计算”(作为一个Map ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
- spark sql cache
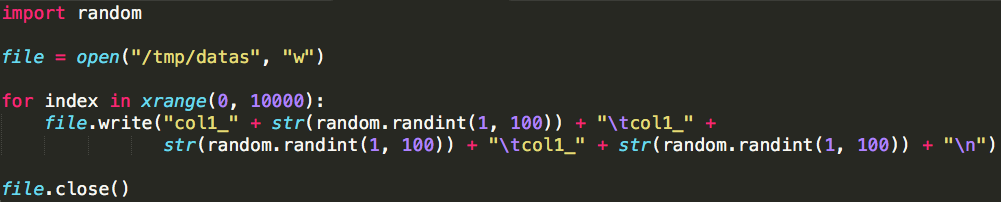
1.几种缓存数据的方法 例如有一张hive表叫做activity 1.CACHE TABLE //缓存全表 sqlContext.sql("CACHE TABLE activity" ...
- Spark SQL 初步
已经Spark Submit 2013哪里有介绍Spark SQL.就在很多人都介绍Catalyst查询优化框架.经过一年的发展后,.今年Spark Submit 2014在.Databricks放弃 ...
- Spark SQL笔记——技术点汇总
目录 概述 原理 组成 执行流程 性能 API 应用程序模板 通用读写方法 RDD转为DataFrame Parquet文件数据源 JSON文件数据源 Hive数据源 数据库JDBC数据源 DataF ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark SQL官方文档阅读--待完善
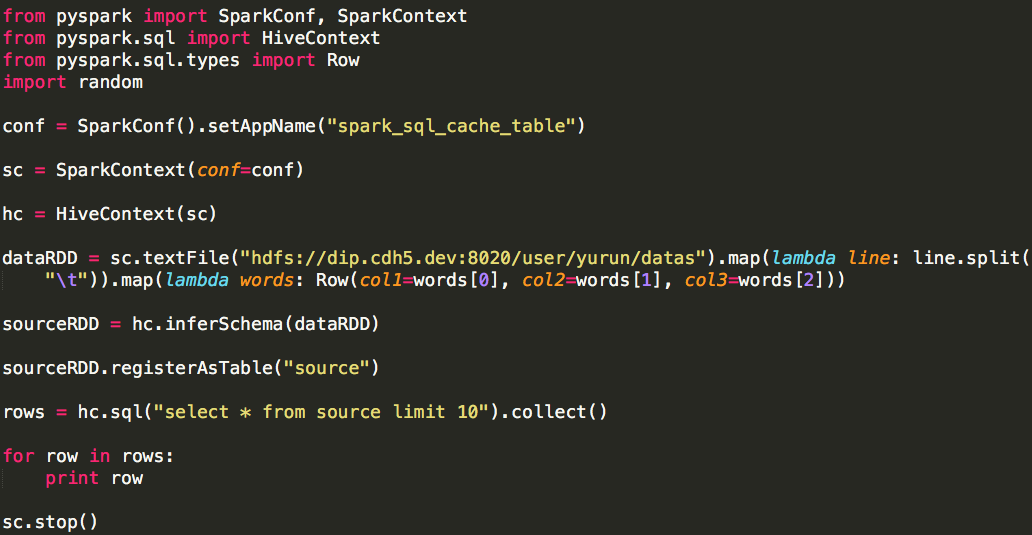
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
随机推荐
- ajax 基础教程
这是一本什么书?这是一本技术类的书籍,主要从历史.XMLHttpRequest对象.怎么样于服务器交互.构建完备的Ajax开发工具箱.使用jsUnit测试javascript 代码,总之就是让我们从这 ...
- asp.net服务器控件开发系列一
最近想写写博客记录下自己学习开发服务器控件. 第一步:搭建环境. 1.新建一个项目类库,用于保存控件: 2.新建一个Web工程,用于调用控件: 如图: 第二步:在控件类库下,新建一个服务器控件类Tex ...
- C++ 实现01背包动态规划
简述一下01背包: 背包容量大小固定,有一些物品,每个物品都有重量和价值两个属性,且物品唯一不重复(即同一物品只能放入一个),放入物品的总重量不能超过背包容量 ,求放入背包的物品的总价值最大化.0代表 ...
- C# 调用AForge类库操作摄像头
如有雷同,不胜荣幸,若转载,请注明 最近做项目需要操作摄像头,在网上百度了很多资料,很多都是C#调用window API 发送SendMessage,实现操作摄像头,但是C#调用window API的 ...
- Lucene分页-----SearcherAfter
/** * 分页,SearcherAfter * @param query * @param pageIndex * @param pageSize */ public void searchPage ...
- 生成dll文件的示例
看了好多网上写的关于dll文件生成和实用的资料发现多尔不全,都是抄来抄去,有的干脆就是搬用msdn上的原文,实在没有创意和可看的东西.于是本着学和实用的目的自己实践的东西分享给大家. 大前提:使用VS ...
- Fedora 21 中添加及更新源的命令
原文: Fedora 21 中添加及更新源的命令 fedora的软件源信息文件(*.repo)都是放在 /etc/yum.repos.d 目录下的.可以通过# ls -l /etc/yum.repos ...
- JavaScript 学习笔记之线程异步模型
核心的javascript程序语言并没有包含任何的线程机制,客户端javascript程序也没有任何关于线程的定义,事件驱动模式下的javascript语言并不能实现同时执行,即不能同时执行两个及以上 ...
- php 之 json格式
/*JSON语法数据在名称/值对中数据由逗号分隔花括号保存对象方括号保存数组 JSON 数据的书写格式是:名称/值对名称/值对包括字段名称(在双引号中),后面写一个冒号,然后是值;如"myw ...
- C#中的Invoke
在用.NET Framework框架的WinForm构建GUI程序界面时,如果要在控件的事件响应函数中改变控件的状态,例如:某个按钮上的文本原先叫“打开”,单击之后按钮上的文本显示“关闭”,初学者往往 ...