H3C 寻找邻居
H3C 寻找邻居的更多相关文章
- H3C IPv6邻居发现协议
- bzoj1604 牛的邻居 STL
Description 了解奶牛们的人都知道,奶牛喜欢成群结队.观察约翰的N(1≤N≤100000)只奶牛,你会发现她们已经结成了几个“群”.每只奶牛在吃草的时候有一个独一无二的位置坐标Xi,Yi(l ...
- 【转】ZigBee终端入网方式深入分析
前述 继之前对终端Direct Join的分析,发现很多东西还很模糊,存在很多问题.终于找到时间继续深入挖下去,这次应该比较完整地搞清了终端的入网机制,并纠正之前的几个认识偏差. 由于Z-Stack网 ...
- 对客户推荐产品模型+python代码
首先观看数据: l 数据的基本特征用 describe 描述每个基本特征 l 画图画出每个特征的基本统计图 应用import matplotlib.pylab as pl 画图显示 l 关 ...
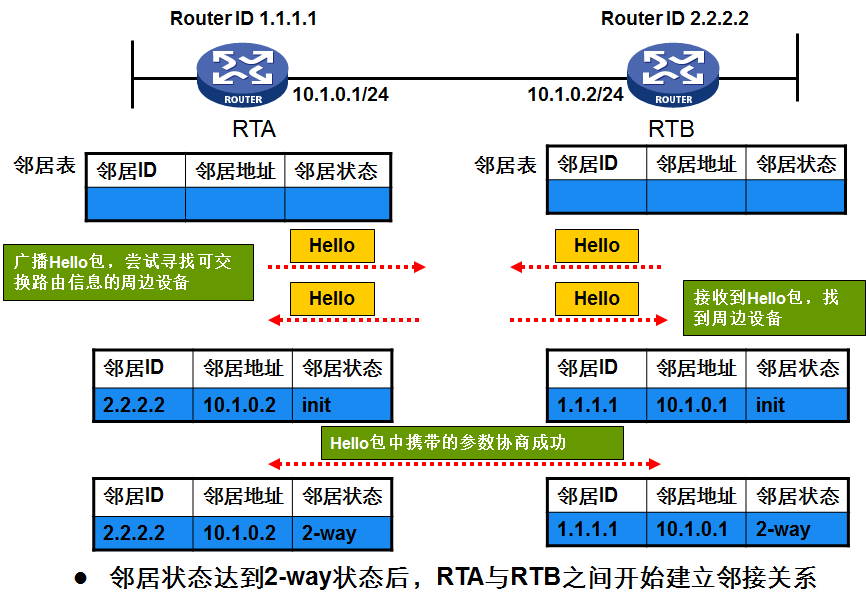
- OSPF理论总结
OSPF学习总结一.OSPF协议的报文类型: 1. Hello 报文:主要用来发现.建立和维护邻居关系. 2. DD报文:数据库的描述报文,主要用来两台路由器的数据库同步. 3. LSR报文:链路状态 ...
- k近邻法(KNN)知识点概括
分类一般分为两种: 积极学习法:先根据训练集构造模型,然后根据模型对测试集分类 消极学习法:推迟建模,先简单存储训练集,等到给定测试集时再进行建模,如KNN算法. 1. 简述 KNN的核心思想就是:物 ...
- 想玩 BGP 路由器么?用 CentOS 做一个
在之前的教程中,我对如何简单地使用Quagga把CentOS系统变成一个不折不扣地OSPF路由器做了一些介绍.Quagga是一个开源路由软件套件.在这个教程中,我将会重点讲讲如何把一个Linux系统变 ...
- OSPF基础介绍
OSPF基础介绍 一.RIP的缺陷 1.以跳数评估的路由并非最优路径 2.最大跳数16导致网络尺度小 3.收敛速度慢 4.更新发送全部路由表浪费网络资源 二.OSPF基本原理 1.什么是OSPF a& ...
- opencv7-ml之KNN
准备知识 在文件"opencv\sources\modules\ml\src\precomp.hpp"中 有cvPrepareTrainData的函数原型. int cvPrepa ...
随机推荐
- ORACLE 所有 表 记录 条数
SELECT TABLE_NAME,TO_NUMBER(EXTRACTVALUE(XMLTYPE(DBMS_XMLGEN.GETXML('SELECT COUNT(*) CNT FROM '||TAB ...
- log4j日志系统
在项目开发中,记录错误日志是一个很有必要功能.一是方便调试:二是便于发现系统运行过程中的错误:三是存储业务数据,便于后期分析: 在java中,记录日志,有很多种方式. 比如,自己实现. 自己写类,将日 ...
- Linux常用命令6 压缩解压命令
.zip是Linux和Windows共有的压缩格式 1.压缩解压命令:gzip 命令英文原意:GNU zip 命令所在路径:/bin/gzip 执行权限:所有用户 语法: gzip [文件] ...
- 【JZOJ4898】【NOIP2016提高A组集训第17场11.16】人生的价值
题目描述 NiroBC终于找到了人生的意义,可是她已经老了,在新世界,没有人认识她,她孤独地在病榻上回顾着自己平凡的一生,老泪纵横.NiroBC多么渴望再多活一会儿啊! 突然一个戴着黑色方框眼镜,方脸 ...
- [Offer收割]编程练习赛104
题目过于简单,没啥好说的,但是拿了个第一感觉很爽,记录一下 题目1 : 小Hi与魔法 排序,从1开始递增 #include <bits/stdc++.h> using namespace ...
- 用python爬虫抓站的一些技巧总结 zz
用python爬虫抓站的一些技巧总结 zz 学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自动收邮件的脚本, ...
- LeetCode21 Merge Two Sorted Lists
题意: Merge two sorted linked lists and return it as a new list. The new list should be made by splici ...
- 条件变量用例--解锁与signal的顺序问题
我们知道,当调用signal/broadcast唤醒等待条件变量的其他线程时,既可以在加锁的情况下调用signal/broadcast,也可以在解锁的情况下调用. 那么,到底哪种情况更好呢?man手册 ...
- Oracle错误——引发ORA-01843:无效的月份。
问题 引发ORA-01843:无效的月份. 解决 改动client会话日期的语言: ALTER SESSION SET nls_date_language='american';
- 数组的查找,删除 Day07
package com.sxt.arraytest2; /* * 形参列表的作用:1.接受方法调用处传来的实参 * 2.规定了实参传入数据的类型 */ import java.util.Arrays; ...