HBase 原理

- 逻辑数据模型

- 物理数据模型

- HBase所有行按照Rowkey进行字典排序,Table在行的方向分割为多个region

- Region 按照大小进行分割,每个table最初只有一个Region,随着数据的不断插入,Region不短增大,当增加到一定阈值后,从中间分裂成两个Region。 Table中的数据不断增加,就会有越来越的Region

- Region是HBase分布式存储和负载均衡的最小单元,一个region只能在一个RegionServer上。
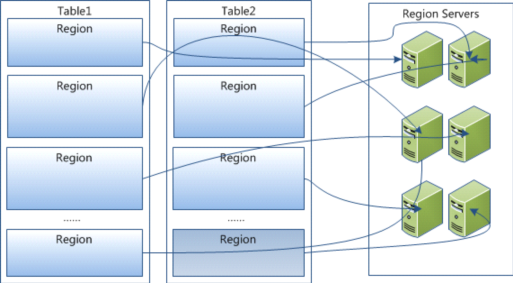
- Region虽然是分布式存储的最小单元,但不是存储的最小单元(内部有更详细的结构)。内部划分为多个Store,一个Store对应一个Column Family。 Store内部又分为一个MemStore和零到多个Storefile。Storefile以Hfile的形式存储在HDFS上

- 每个Region server 管理大约1000个HRegion。(Why:这个1000的数字应该是从BigTable的论文中来的(5 Implementation节):Each tablet server manages a set of tablets(typically we have somewhere between ten to a thousand tablets per tablet server))


这个架构图比较清晰的表达了HMaster和NameNode都支持多个热备份,使用ZooKeeper来做协调;
ZooKeeper并不是云般神秘,它一般由三台机器组成一个集群,内部使用PAXOS算法支持三台Server中的一台宕机,
也有使用五台机器的,此时则可以支持同时两台宕机,既少于半数的宕机,然而随着机器的增加,它的性能也会下降;
RegionServer和DataNode一般会放在相同的Server上实现数据的本地化。


- Client
- Zookeeper
- HMaster
- Region Server
- 写入
- 读出
HBase 原理的更多相关文章
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Hbase原理
Hbase原理 概述 HBase是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop ...
- HBase原理、设计与优化实践
转自:http://www.open-open.com/lib/view/open1449891885004.html 1.HBase 简介 HBase —— Hadoop Database的简称,G ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- 1、Hbase原理分析
一.Hbase介绍 1.1.对Hbase的认识 HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现. HBase参考 Google 的 Bigtable ...
- HBase原理 – 分布式系统中snapshot是怎么玩的?(转载)
snapshot(快照)基础原理 snapshot是很多存储系统和数据库系统都支持的功能.一个snapshot是一个全部文件系统.或者某个目录在某一时刻的镜像.实现数据文件镜像最简单粗暴的方式是加锁拷 ...
- 【转】HBase原理和设计
简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠的方 ...
- HBase原理和设计
转载 2016年1月10日:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ 简介 架构 数据组织 原理 RS定位 region写入 ...
- HBase原理解析(转)
本文属于转载,原文链接:http://www.aboutyun.com/thread-7199-1-1.html 前提是大家至少了解HBase的基本需求和组件. 从大家最熟悉的客户端发起请求开始讲 ...
- HBase之一:HBase原理和设计
一.简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠 ...
随机推荐
- 2019-10-22-Roslyn-打包自定义的文件到-NuGet-包
title author date CreateTime categories Roslyn 打包自定义的文件到 NuGet 包 lindexi 2019-10-22 19:45:34 +0800 2 ...
- This cache store does not support tagging.
用户权限管理系统 https://github.com/Zizaco/entrust 再添加角色的时候... 报了一个错.. BadMethodCallException in Repository. ...
- 从零学React Native之06flexbox布局
前面我们接触了好多React Native代码, 并没有介绍RN中的组件具体是如何布局的,这一篇文章,重点介绍下flexbox布局. 什么是flexbox布局 React中引入了flexbox概念,f ...
- 自定义View系列教程04--Draw源码分析及其实践
深入探讨Android异步精髓Handler 站在源码的肩膀上全解Scroller工作机制 Android多分辨率适配框架(1)- 核心基础 Android多分辨率适配框架(2)- 原理剖析 Andr ...
- java 删除字符串左边空格和右边空格 trimLeft trimRight
/** * 去右空格 * @param str * @return */ public String trimRight(String str) { if (str == null || str.eq ...
- Go 语言开发工具
Go 语言开发工具 LiteIDE LiteIDE是一款开源.跨平台的轻量级Go语言集成开发环境(IDE). 支持的操作系统 Windows x86 (32-bit or 64-bit) Linux ...
- CSS常用函数calc等
>>CSS常用函数<<
- C#的选择语句
一.选择语句 if,else if是如果的意思,else是另外的意思,if'后面跟()括号内为判断条件,如果符合条件则进入if语句执行命令.如果不符合则不进入if语句.else后不用加条件,但是必须与 ...
- springmvc 过滤器和拦截器
1. 拦截器: interceptor 过滤器(filter)与拦截器(intercepter)相同点:1) 都可以拦截请求,过滤请求2) 都是应用了过滤器(责任链)设计模式 2.区别: 1) fi ...
- win10 uwp 使用 AppCenter 自动构建
微软在今年7月上线 appcenter.ms 这个网站,通过 App Center 可以自动对数千种设备进行适配测试.快速将应用发送给测试者或者直接发布到应用商店.做到开发的构建和快速测试,产品的遥测 ...