spring cloud深入学习(十三)-----使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位服务故障点,以对症下药。于是就有了分布式系统调用跟踪的诞生。
现今业界分布式服务跟踪的理论基础主要来自于 Google 的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,使用最为广泛的开源实现是 Twitter 的 Zipkin,为了实现平台无关、厂商无关的分布式服务跟踪,CNCF 发布了布式服务跟踪标准 Open Tracing。国内,淘宝的“鹰眼”、京东的“Hydra”、大众点评的“CAT”、新浪的“Watchman”、唯品会的“Microscope”、窝窝网的“Tracing”都是这样的系统。
Spring Cloud Sleuth
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。虽然每一部分都可能变得很复杂,但基本原理都类似。
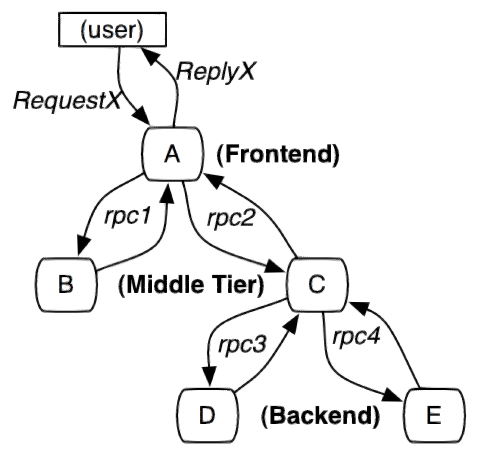
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
- 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
- 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
这是Spring Cloud Sleuth的概念图:
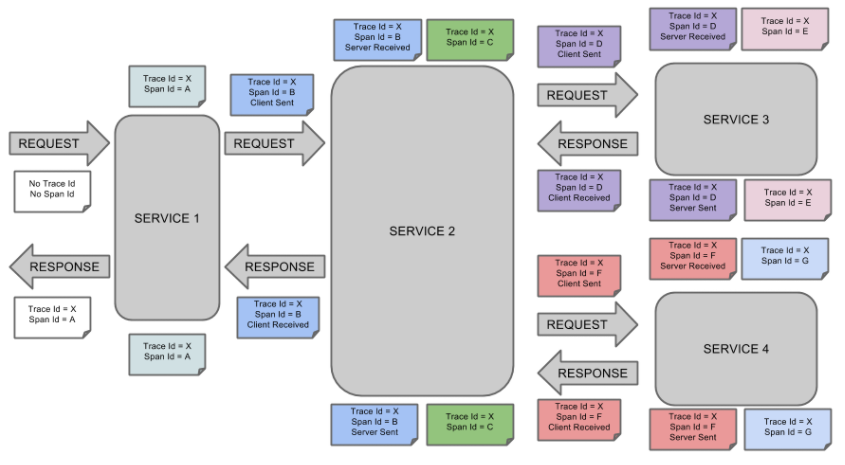
ZipKin
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。
快速上手
创建zipkin-server项目
1、项目依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
</dependencies>
2、启动类
@SpringBootApplication
@EnableEurekaClient
@EnableZipkinServer
public class ZipkinApplication { public static void main(String[] args) {
SpringApplication.run(ZipkinApplication.class, args);
} }
使用了@EnableZipkinServer注解,启用Zipkin服务。
3、配置文件
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
server:
port: 9000
spring:
application:
name: zipkin-server
配置完成后依次启动示例项目:spring-cloud-eureka、zipkin-server项目。刚问地址:http://localhost:9000/zipkin/可以看到Zipkin后台页面
项目添加zipkin支持
在项目spring-cloud-producer和spring-cloud-zuul中添加zipkin的支持。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
Spring应用在监测到Java依赖包中有sleuth和zipkin后,会自动在RestTemplate的调用过程中向HTTP请求注入追踪信息,并向Zipkin Server发送这些信息。
同时配置文件中添加如下代码:
spring:
zipkin:
base-url: http://localhost:9000
sleuth:
sampler:
percentage: 1.0
spring.zipkin.base-url指定了Zipkin服务器的地址,spring.sleuth.sampler.percentage将采样比例设置为1.0,也就是全部都需要。
Spring Cloud Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。采样器不会阻碍span相关id的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth默认采样算法的实现是Reservoir sampling,具体的实现类是PercentageBasedSampler,默认的采样比例为: 0.1(即10%)。不过我们可以通过spring.sleuth.sampler.percentage来设置,所设置的值介于0.0到1.0之间,1.0则表示全部采集。
这两个项目添加zipkin之后,依次进行启动。
进行验证
这样我们就模拟了这样一个场景,通过外部请求访问Zuul网关,Zuul网关去调用spring-cloud-producer对外提供的服务。
四个项目均启动后,在浏览器中访问地址:http://localhost:8888/producer/hello?name=neo 两次,然后再打开地址:http://localhost:9000/zipkin/点击对应按钮进行查看。
点击查找看到有两条记录
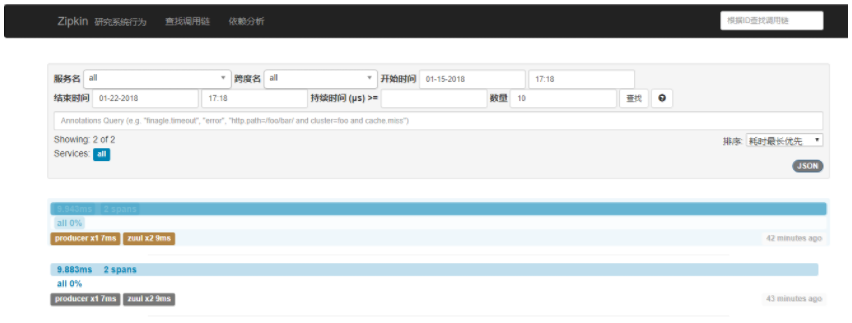
点击记录进去页面,可以看到每一个服务所耗费的时间和顺序
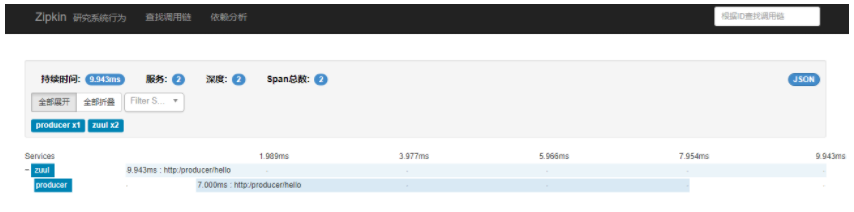
点击依赖分析,可以看到项目之间的调用关系

spring cloud深入学习(十三)-----使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪的更多相关文章
- 跟我学SpringCloud | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
SpringCloud系列教程 | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪 Springboot: 2.1.6.RELEASE SpringCloud: ...
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
- 【spring cloud】spring cloud Sleuth 和Zipkin 进行分布式链路跟踪
spring cloud 分布式微服务架构下,所有请求都去找网关,对外返回也是统一的结果,或者成功,或者失败. 但是如果失败,那分布式系统之间的服务调用可能非常复杂,那么要定位到发生错误的具体位置,就 ...
- 使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
原文:http://www.cnblogs.com/ityouknow/p/8403388.html 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成, ...
- Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin【Finchley 版】
Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin[Finchley 版] 发表于 2018-04-24 | 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请 ...
- spring cloud 入门系列八:使用spring cloud sleuth整合zipkin进行服务链路追踪
好久没有写博客了,主要是最近有些忙,今天忙里偷闲来一篇. =======我是华丽的分割线========== 微服务架构是一种分布式架构,微服务系统按照业务划分服务单元,一个微服务往往会有很多个服务单 ...
- Spring 源码学习笔记10——Spring AOP
Spring 源码学习笔记10--Spring AOP 参考书籍<Spring技术内幕>Spring AOP的实现章节 书有点老,但是里面一些概念还是总结比较到位 源码基于Spring-a ...
- Spring 源码学习笔记11——Spring事务
Spring 源码学习笔记11--Spring事务 Spring事务是基于Spring Aop的扩展 AOP的知识参见<Spring 源码学习笔记10--Spring AOP> 图片参考了 ...
- 【SpringCloud构建微服务系列】分布式链路跟踪Spring Cloud Sleuth
一.背景 随着业务的发展,系统规模越来越大,各微服务直接的调用关系也变得越来越复杂.通常一个由客户端发起的请求在后端系统中会经过多个不同的微服务调用协同产生最后的请求结果,几乎每一个前端请求都会形成一 ...
随机推荐
- h5判断是否为iphonex
js移动端页面判断是否是iphoneX 转自https://blog.csdn.net/weixin_39924326/article/details/80352929 function isIPho ...
- iOS UIWebView获取403/404
问题描述 与WindowsPhone不同,iOS UIWebView并不认为403/404这种情况下页面访问是失败的,这也情有可原,但有时候,我们需要对WebView所遇到的403/404进行处理. ...
- tp5 mkdir() 没有权限
- .NETFramework:Exception
ylbtech-System.Exception.cs 1.返回顶部 1. #region 程序集 mscorlib, Version=4.0.0.0, Culture=neutral, Public ...
- 2017/8/4 SCJP学习
2 Object Orientation . . . . . . . . . . . . . . . . . . . . . . . . . 85 Encapsulation (Exam Object ...
- idae for mac部分背景色修改收集
文章目录 所有字体默认颜色 终端背景色 行数line number背景色 line number颜色 编码区背景色 光标所在行背景色 未被使用的变量.方法或者类 控制台相关 选中文字的背景色 选中和未 ...
- ASP.NET的底层体系2
文章引导 1.ASP.NET的底层体系1 2.ASP.NET的底层体系2 引言 接着上一篇ASP.NET的底层体系1我们继续往下走 一.System.Web.HttpRuntime.ProcessRe ...
- python基础-基础知识(包括:函数递归等知识)
老男孩 Python 基础知识练习(三) 1.列举布尔值为 False 的值空,None,0, False, ", [], {}, () 2.写函数:根据范围获取其中 3 和 7 整除的所有 ...
- POJ-2255-Tree Recovery-求后序
Little Valentine liked playing with binary trees very much. Her favorite game was constructing rando ...
- POJ-3264-Balanced Lineup-线段树模板题-查询区间内最大值和最小值之差
For the daily milking, Farmer John's N cows (1 ≤ N ≤ 50,000) always line up in the same order. One d ...