spider csdn blog part II
继续上次的笔记, 继续完善csdn博文的提取.
发现了非常好的模块. html2docx
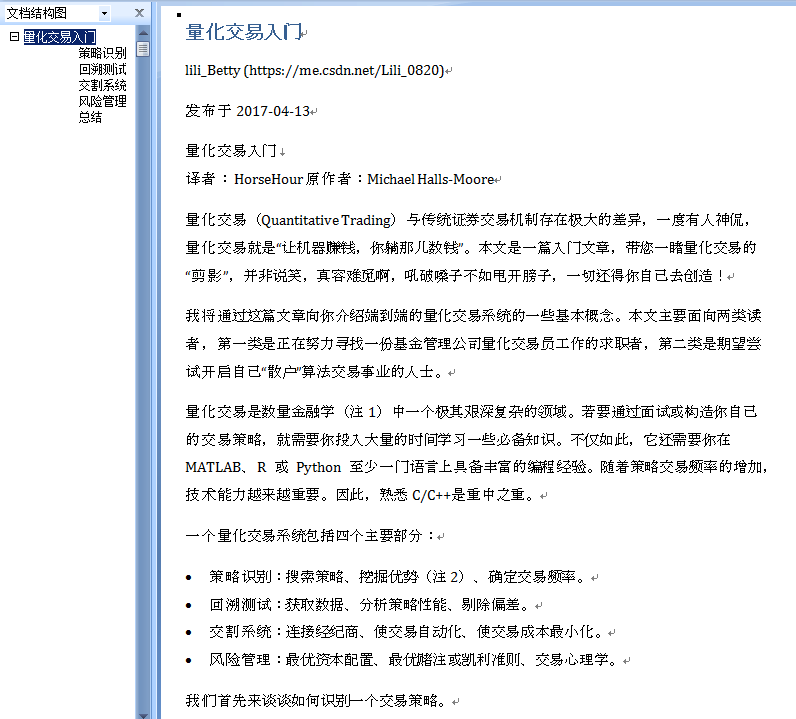
结果展示:
运行之后, 直接生成docx文档. 截个图如下:
结果已经基本满意了!!!
在编写过程中的一些感想.
获取网站响应:
决定放弃requests, 采用 selenium.webdriver.
后者就是模拟浏览器操作. 可以应对许多需要登录的, 防止爬取的网站
超时控制(等待网站响应), 操作网页等功能也非常强大.定位页面元素:
在定位页面元素方面: 有太多的方法可以选择. 最后决定就用一种. webdriver方法.
放弃etree, BeautifulSoup, 还有直接用re模块的提取.好好学习并掌握webdriver一种办法, 就可以了. 它的功能已经非常强大了,
也支持用xpath来锁定页面元素.webdriver支持 网页面里注入javascript脚本来完成任务. (网络开发里的前端技术)
为了与html2docx衔接, 这里利用了
selenium.webdriver.WebElemnt.get_attribute('outHTML')方法获取元素的html
BeautifulSoup对象的prettify()方法, 来生成合法的完整的页面元素的html源码.
代码:
import os; type(os)
import time; type(time)
import re
anys = '.*?' # 任意长的字符串, 贪婪型的
import random; type(random)
#import requests
#from lxml import etree
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.binary_location = r'C:\Users\Administrator\AppData\Roaming\360se6\Application\360se.exe'
chrome_options.add_argument(r'--lang=zh-CN') # 这里添加一些启动的参数
import logging
logging.basicConfig(level=logging.INFO,
format= '%(asctime)s - %(name)s - %(levelname)s : %(message)s',
#format='%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s %(message)s',
)
logger = logging.getLogger(__name__)
#logger.info("Start print log")
#logger.debug("Do something")
#logger.warning("Something maybe fail.")
#logger.info("Finish")
from bs4 import BeautifulSoup
from html2docx import html2docx
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
type(By)
type(EC)
def itm(): return int(time.time())
def insert_title(title:'html w/o Body tag',
article:'html with Body tag'):
'''在article这个完整的合法的html网页里, 在它的头部插入标题部分(title).
标题部分: 包括文章标题行+作者行+发布日期
'''
merged = re.sub('(<html>\n\s*<body>)',
'<html>\n <body>\n' + title,
article,
flags=re.S,)
return merged
def get_it_wait_untill(browser, element_func='title', sleep_time=80, arg=''):
'''
selenium内核的锁定页面元素, 然后取之. 比如:
获取网页标题
获取整个网页的源文件
获取指定页面元素:
by_id
by_xpath
Example:
>>> get_it_wait_untill(browser, 'title')
>>> get_it_wait_untill(browser, 'page_source')
>>> get_it_wait_untill(browser, element_func='find_element_by_id',
arg='content_views',
)
>>> get_it_wait_untill(browser, element_func='find_element_by_xpath',
arg='//section[@class="content article-content"]',
)
'''
prop = str(type(getattr(browser, element_func)))
#python的很多内置的函数, 是使用C语言写出来的,要看C语言的源代码
if prop == "<class 'str'>":
element = WebDriverWait(browser, sleep_time).until(
lambda x: getattr(x, element_func)
)
#elif callable(getattr(browser, element_func)):
elif prop == "<class 'method'>":
element = WebDriverWait(browser, sleep_time).until(
lambda x: getattr(x, element_func)(arg)
)
return element
def get_csdn_blog(
url='https://blog.csdn.net/Lili_0820/article/details/70155949'
,
sleep_time=40
,
):
'''
爬取csdn blog文章
参数:
url: str,
sleep_time: int, wait time in seconds
Example:
>>> get_csdn_blog()
'''
logger.info(f'当前网页的url: {url}')
browser = webdriver.Chrome(options=chrome_options)
browser.implicitly_wait(200)
#timeout_wait = WebDriverWait(browser, 2*5) # 10sec
browser.get(url)
timeout_wait = WebDriverWait(browser, sleep_time) # 10sec;
type(timeout_wait)
'''
我们需要确保: 网页信息已经全部加载, 否则可能提取不到有用信息.
Sets a sticky timeout to implicitly wait for an element to be found,
or a command to complete.
This method only needs to be called one time per session.
当浏览器(webdriver实例)在定位元素的时候,
我们可以设置一个隐式的超时等待时间,
如果超过这个设定的时间还不能锁定元素, 那么就报错或者继续执行.
本方法在整个对话期内, 只需调用一次.
'''
title = WebDriverWait(browser, sleep_time).until(lambda x: x.title)
logger.info(f'提取网页标题: {title}')
html= WebDriverWait(browser, sleep_time).until(lambda x: x.page_source)
#html = browser.page_source
#需要花点时间
#time.sleep(sleep_time) # 太粗暴简单了
title = browser.find_element_by_xpath('//h1[@class="title-article"]').text
pub_date = browser.find_element_by_xpath('//div[@class="article-bar-top"]').text
author_url = browser.find_element_by_xpath('//div[@class="article-bar-top"] /a[1]').get_attribute('href')
pub_date = re.findall('\n(.*?)阅读数.*?收藏', pub_date,re.S)[0]
author, pub_date = re.findall('(.*?) (发布.*?) ', pub_date, re.S)[0]
insertion = f'''
<h1> {title} </h1>
<p> {author} ({author_url}) </p>
<p> {pub_date} </p>
'''
content_we = browser.find_element_by_id('content_views') # selenium.webelement
text = content_we.text; type(text)
logger.info('网页源码的长度和博文的长度分别是: {1} {0}'.
format(len(text), len(html))
)
content_html = content_we.get_attribute('outerHTML')
content_html = BeautifulSoup(content_html, 'lxml').prettify()
content_html = insert_title(insertion, content_html)
# 规范化: 输出文件名
# if '|' in title: title2=title.replace('|', '')
# title2 = title2.replace('QuantStart','')
# title2 = title2.replace(' ','_')
outf=f'{title}_{itm()}.docx'
buffer = html2docx(content_html, title=title)
with open(outf, "wb") as fh: fh.write(buffer.getvalue())
if os.path.exists(outf): print( f'{outf} created!!!')
# re方法
'''
pattern = 'id="content_views" class="markdown_views.*?>' + \
'(.*?)' + \
'<link href="https://csdnimg.cn/release/' + \
'phoenix/mdeditor/markdown_views'
a = re.findall(pattern, html, re.S)
a = a[0]
a = re.findall(f'{anys}(<p>{anys})</div>{anys}', a, re.S)[0]
'''
# etree方法
'''
tree = etree.HTML(html)
cv_etree = tree.xpath('//div[@id="content_views"]')[0]
text = cv_etree.xpath('*/text()')
cv_html = etree.tostring(cv_etree, encoding='unicode')
'''
browser.close()
browser.quit()
#return a
if __name__=='__main__':
pass
# url='https://blog.csdn.net/Lili_0820/article/details/70155949'
# get_csdn_blog(url, sleep_time=80)
spider csdn blog part II的更多相关文章
- spider csdn博客和quantstart文章
spider csdn博客和quantstart文章 功能 提取csdn博客文章 提取quantstart.com 博客文章, Micheal Hall-Moore 创办的网站 特色功能就是: 想把原 ...
- 仿CSDN Blog返回页面顶部功能
只修改了2个地方: 1,返回的速度-->改成了慢慢回去.(原来是一闪而返回) 2,返回顶部图标出现的时机-->改成了只要不在顶部就显示出来.(原来是向下滚动500px后才显示) 注意:JS ...
- 用word发CSDN blog,免去插图片的烦恼
目前大部分的博客作者在用Word写博客这件事情上都会遇到以下3个痛点: 1.所有博客平台关闭了文档发布接口,用户无法使用Word,Windows Live Writer等工具来发布博客.使用Word写 ...
- 用Word 写csdn blog
目前大部分的博客作者在用Word写博客这件事情上都会遇到以下3个痛点: 1.所有博客平台关闭了文档发布接口,用户无法使用Word,Windows Live Writer等工具来发布博客.使用Word写 ...
- 用word发CSDN blog
目前大部分的博客作者在用Word写博客这件事情上都会遇到以下3个痛点: 1.所有博客平台关闭了文档发布接口,用户无法使用Word,Windows Live Writer等工具来发布博客.使用Word写 ...
- 使用Genymotion调试出现错误INSTALL_FAILED_CPU_ABI_INCOMPATIBLE解决办法【转自wjr2012的csdn blog】
点击下载Genymotion-ARM-Translation.zip 将你的虚拟器运行起来,将下载好的zip包用鼠标拖到虚拟机窗口中,出现确认对跨框点OK就行.然后重启你的虚拟机.
- 怎么样CSDN Blog投机和增加流量?
所谓推测装置,以提高它们的可见性,最近比较顾得上,这样一来打字游戏.一方面,练习打字速度 .在又一个方面中,以了解诱导的理论 版权声明:本文博客原创文章,博客,未经同意,不得转载.
- 博客导出工具(C++实现,支持sina,csdn,自定义列表)
操作系统:windowAll 编程工具:visual studio 2013 编程语言:VC++ 最近博文更新的较频繁,为了防止账号异常引起csdn博文丢失,所以花了点时间做了个小工具来导出博文,用做 ...
- python爬虫CSDN文章抓取
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/nealgavin/article/details/27230679 CSDN原则上不让非人浏览訪问. ...
随机推荐
- Eclipse配置jstl标准标签库详解
安装JSTL1.2 日期:2017-06-27 下载jstl1.2版本,下载地址:http://repo2.maven.org/maven2/javax/servlet/jstl/ 用压缩包打开jst ...
- Codeforces 142B(二分染色、搜索)
要点 会发现本质上棋盘分成了若干个独立集,本集合内的点放不放棋子并不影响其他集合内的 集合的划分方式就是满棋盘跳马步直到全跳过了,然后每个集合就分成两队,我们选人多的那队放棋子,人少那队当禁区 con ...
- [Array]628. Maximum Product of Three Numbers
Given an integer array, find three numbers whose product is maximum and output the maximum product. ...
- Django项目:CRM(客户关系管理系统)--40--32PerfectCRM实现King_admin添加不进行限制
# forms.py # ————————19PerfectCRM实现King_admin数据修改———————— from django import forms from crm import m ...
- poj 3468 A Simple Problem with Integers (线段树区间更新求和lazy思想)
A Simple Problem with Integers Time Limit: 5000MS Memory Limit: 131072K Total Submissions: 75541 ...
- ORACLE的Copy命令和create table,insert into的比较
在数据表间复制数据是Oracle DBA经常面对的任务之一,Oracle为这一任务提供了多种解决方案,SQL*Plus Copy 命令便是其中之一.SQL*Plus Copy 命令通过SQL*Net在 ...
- .NET框架之---MEF托管可扩展框架
MEF简介: 今天学习了下MEF框架,MEF,全称Managed Extensibility Framework(托管可扩展框架).MEF是专门致力于解决扩展性问题的框架,MSDN中对MEF有这样一段 ...
- GIT → 03:Git的下载和安装
3.1 Git 下载 官网:https://git-scm.com/ 软件下载地址:https://git-scm.com/downloads 根据自己电脑版本下载对应版本: 3.2 Git 安装 3 ...
- SELECT (@i :=@i + 1)生成序列号
转载自https://blog.csdn.net/qq_27922171/article/details/86477544 同类别自动生成序列号:https://bbs.csdn.net/topics ...
- WCF 服务
1.代码 using System; using System.Collections.Generic; using System.Linq; using System.Runtime.Seriali ...