【Spark-SQL学习之一】 SparkSQL
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、Shark
Shark是基于Spark计算框架之上且兼容Hive语法的SQL执行引擎,由于底层的计算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,当数据全部load在内存的话,将快10倍以上,因此Shark可以作为交互式查询应用服务来使用。除了基于Spark的特性外,Shark是完全兼容Hive的语法,表结构以及UDF函数等,已有的HiveSql可以直接进行迁移至Shark上Shark底层依赖于Hive的解析器,查询优化器,但正是由于SHark的整体设计架构对Hive的依赖性太强,难以支持其长远发展,比如不能和Spark的其他组件进行很好的集成,无法满足Spark的一栈式解决大数据处理的需求。
二、SparkSQL
1、SparkSQL介绍
Hive是Shark的前身,Shark是SparkSQL的前身。
(1)SparkSQL产生的根本原因是其完全脱离了Hive的限制。
(2)SparkSQL支持查询原生的RDD,RDD是Spark平台的核心概念,是Spark能够高效的处理大数据的各种场景的基础。
(3)能够在Scala中写SQL语句,支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用。
2、Spark on Hive和Hive on Spark
Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行。
Hive on Spark:Hive即作为存储又负责sql的解析优化,Spark负责执行。
3、DataFrame(SparkSQL的最佳搭档)
DataFrame也是一个分布式数据容器。
与RDD类似,然而DataFrame更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。
同时与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。
从API易用性的角度上看, DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
DataFrame的底层封装的是RDD,只不过RDD的泛型是Row类型。
4. SparkSQL的数据源
SparkSQL的数据源可以是JSON类型的字符串,也可以是JDBC,Parquent,Hive,HDFS等。

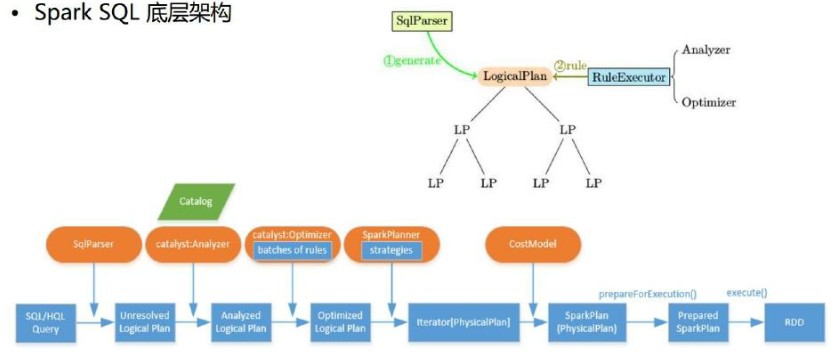
5. SparkSQL底层架构
首先拿到sql后解析一批未被解决的逻辑计划,
-->再经过分析得到分析后的逻辑计划,
-->再经过一批优化规则转换成一批最佳优化的逻辑计划,
-->再经过SparkPlanner的策略转化成一批物理计划,
-->随后经过消费模型转换成一个个的Spark任务执行。
6. 谓词下推(predicate Pushdown)

参考:
【Spark-SQL学习之一】 SparkSQL的更多相关文章
- spark SQL学习(综合案例-日志分析)
日志分析 scala> import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row scala&g ...
- spark SQL学习(认识spark SQL)
spark SQL初步认识 spark SQL是spark的一个模块,主要用于进行结构化数据的处理.它提供的最核心的编程抽象就是DataFrame. DataFrame:它可以根据很多源进行构建,包括 ...
- spark SQL学习(案例-统计每日销售)
需求:统计每日销售额 package wujiadong_sparkSQL import org.apache.spark.sql.types._ import org.apache.spark.sq ...
- spark SQL学习(案例-统计每日uv)
需求:统计每日uv package wujiadong_sparkSQL import org.apache.spark.sql.{Row, SQLContext} import org.apache ...
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- spark SQL学习(数据源之json)
准备工作 数据文件students.json {"id":1, "name":"leo", "age":18} {&qu ...
- spark SQL学习(数据源之parquet)
Parquet是面向分析型业务得列式存储格式 编程方式加载数据 代码示例 package wujiadong_sparkSQL import org.apache.spark.sql.SQLConte ...
- spark SQL学习(load和save操作)
load操作:主要用于加载数据,创建出DataFrame save操作:主要用于将DataFrame中的数据保存到文件中 代码示例(默认为parquet数据源类型) package wujiadong ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
随机推荐
- OSI 协议
- Android手机用wifi连接adb调试的方法
https://www.jianshu.com/p/dc6898380e38 0x0 前言 Android开发肯定要连接pc的adb进行调试,传统的方法是用usb与pc进行连接,操作简单即插即用,缺点 ...
- [python] python3.6 安装 pytesseract 出错
安装pytesseact出错, 下载 tesseract-ocr , 地址 https://github.com/tesseract-ocr/tesseract 修改pytesseract.py 设置 ...
- Inside The C++ Object Model(四)
============================================================================4-1. Member 的各种调用方式静态成员函 ...
- Android查看文件大小
查看当前路径下的各个挂载模块的大小及剩余量(例如在根目录执行) df #输出 Filesystem Size Used Free Blksize /sys/fs/cgroup .0K /mnt/ase ...
- Android 官方独立 adb / fastboot 工具包
https://dl.google.com/android/repository/platform-tools-latest-darwin.zip https://dl.google.com/andr ...
- jenkins git 之 Advanced clone behaviours
jenins 上的 Git Plugin插件,默认是下载完整的历史版本,随着分支约多,历史版本约多,整个文件会很大,下载常常会超时. 单独的git命令可以使用以下方式来优化 git clone --d ...
- 11.1 vue(2)
2018-11-1 19:41:00 2018年倒数第二个月! 越努力越幸运!!!永远不要高估自己! python视频块看完了!还有30天吧就结束了! 今天老师讲的vue 主要是看官网文档 贴上连接 ...
- 10.27 rest_framework(1)
2018-10-27 16:48:04 前几天在整理django博客! 新学的rest_framework框架是源于Django的 使用的时候得 pip install djangorestframe ...
- iframe 加载外部资源,显示隐藏loading,onload失效
在项目中使用iframe 来加载外部资源,需要在iframe请求外部资源的时候,需要显示一个loading,在加载完成后,将这个loading隐藏掉,刚开始看到W3C中 iframe有一个 onloa ...