Hive介绍及安装
Hive介绍及安装
介绍:
Hive是基于Hadoop的数据仓库解决方案。由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性。
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
Hive就是我们所说的使用传统的sql来分析海量数据的工具。可以把Hive当成一个“数据库”,它也具备传统数据库的数据单元,数据库(Database/Schema)和表(Table).但实际上只是Hadoop上的一个工具。
所以从技术角度来看:
hive就是一个翻译器,将传统的sql转化成mapreduce。或者说:hive是基于mapreduce 的一个上层数据分析框架
作用:
hive能够用来进行海量数据的存储、查询和离线分析。快速查询!
hive数据库:
库:Hive中的数据库概念,本质上仅仅是表的一个目录结构或命名空间。
表:Hive中的表概念,本质上仅仅是数据的一个目录结构或命名空间。
数据单元: Databases:数据库。概念等同于关系型数据库的Schema,不多解释;
Tables:表。概念等同于关系型数据库的表,不多解释;
Partitions:分区。概念类似于关系型数据库的表分区,没有那么多分区类型,只支持固定分区,将同一组数据存放至一个固定的分区中。
Buckets (or Clusters):分桶。同一个分区内的数据还可以细分,将相同的KEY再划分至一个桶中,这个有点类似于HASH分区,只不过这里是HASH分桶,也有点类似子分区吧。
内、外部表的区别:
删除表时:
内部表:删除数据和元数据;
外部表:删除元数据。
数据是否共享:
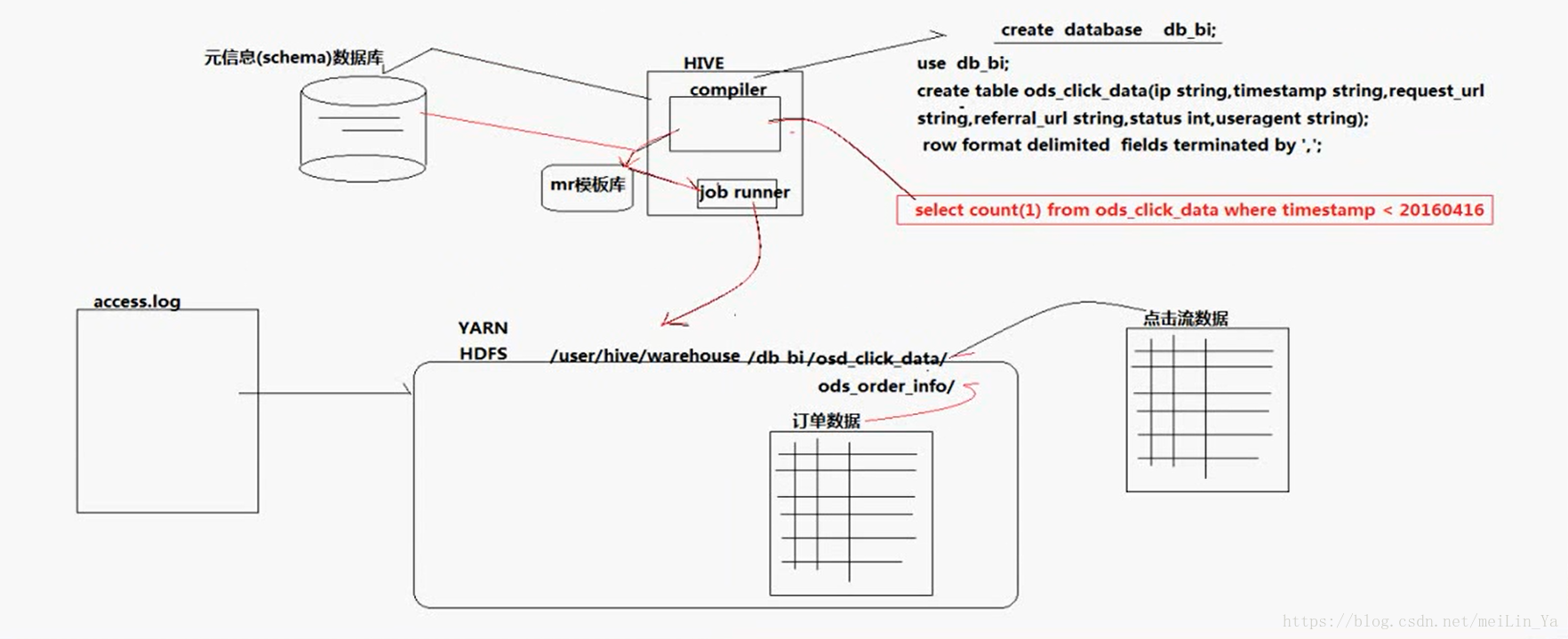
hive运行底层:来张图:
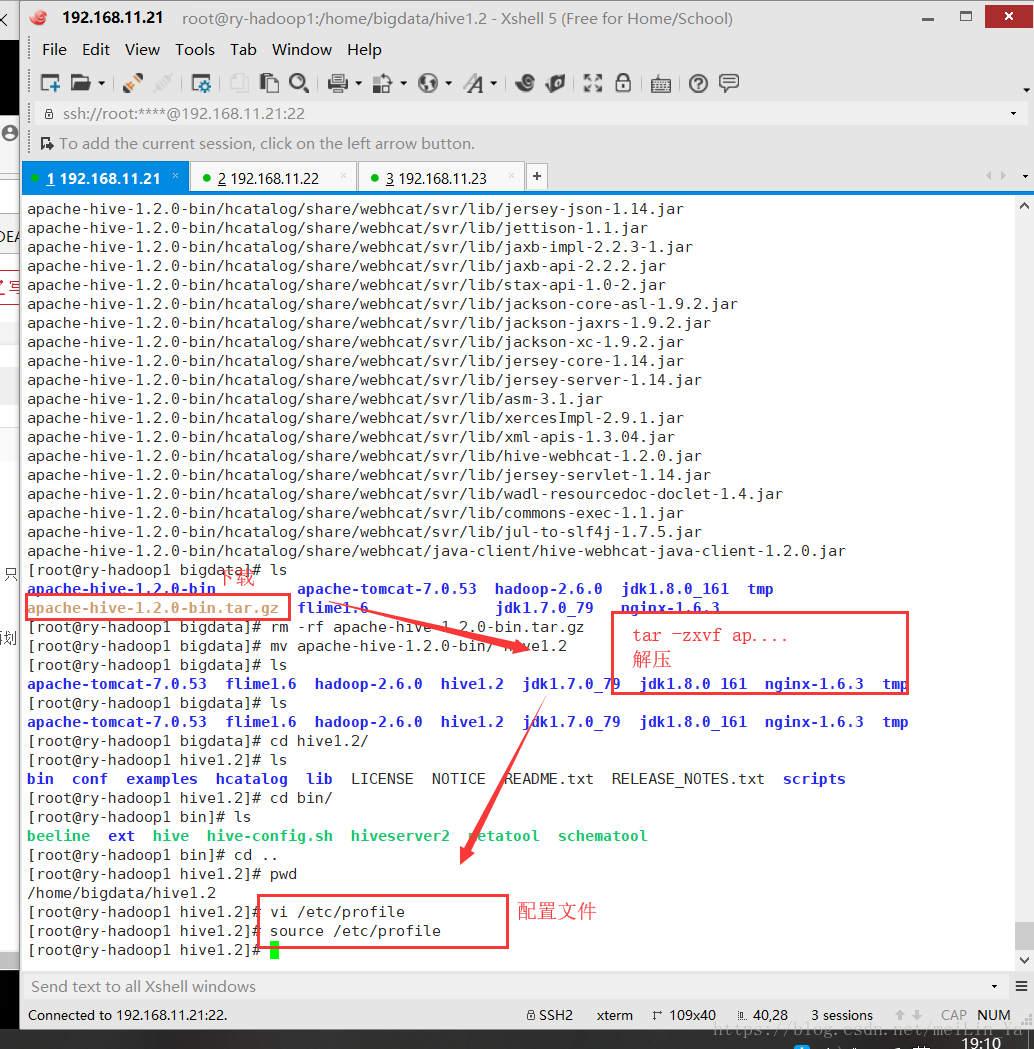
安装:
配置:
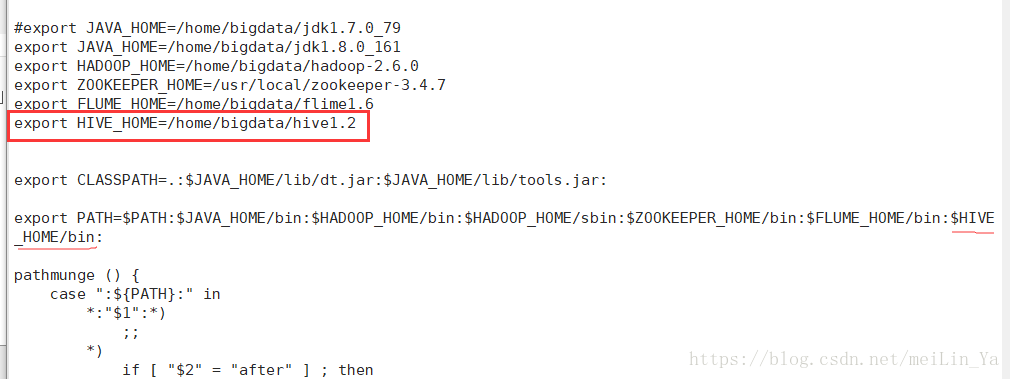
vi /conf/hive-site.xml(必须叫这个名字) 此处配置的是连接数据库
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--><configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://ry-hadoop1:3306/hive?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>添加一个jdbc jar包
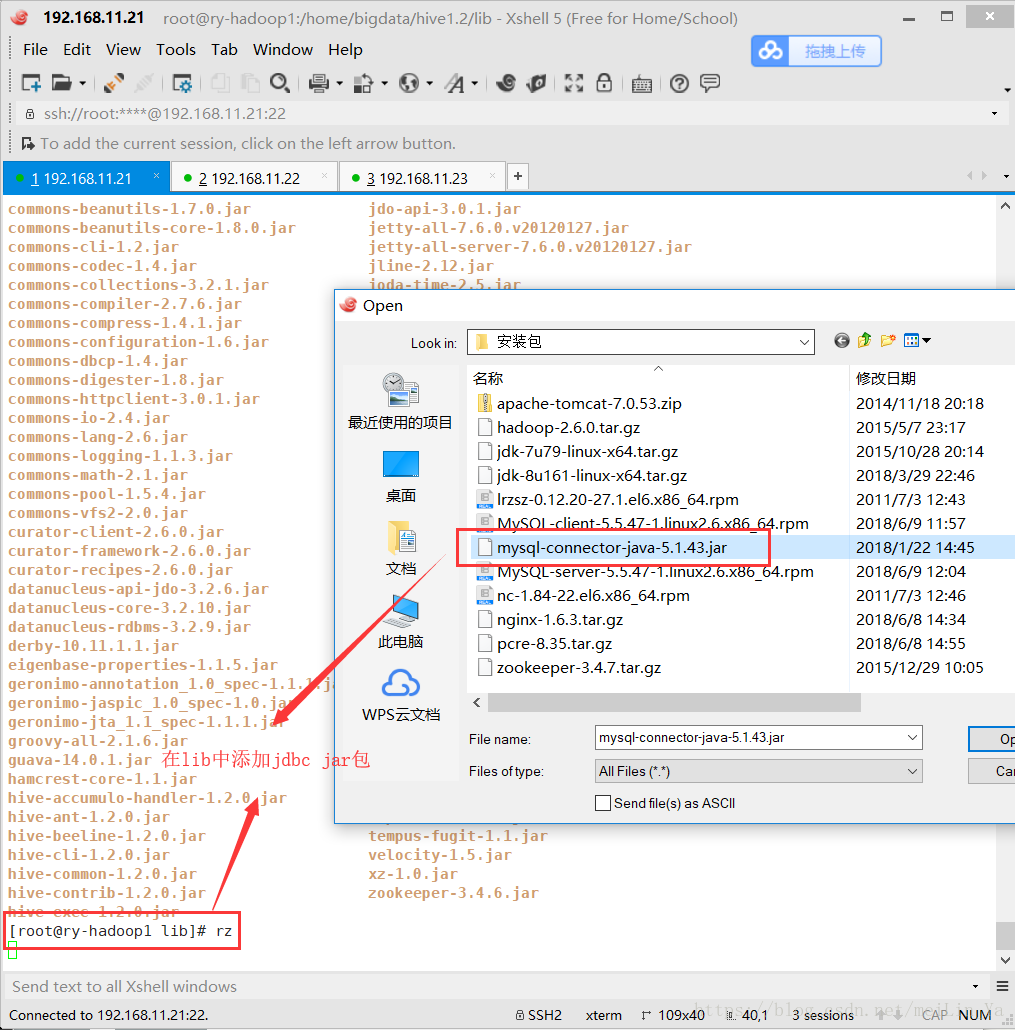
此时启动hive会报错,是因为hadoop中/home/bigdata/hadoop-2.6.0/share/hadoop/yarn/lib/jline-0.9.94.jar 的版本太低,所以我们将hive中jline-2.12.jar替换掉hadoop中版本低的。
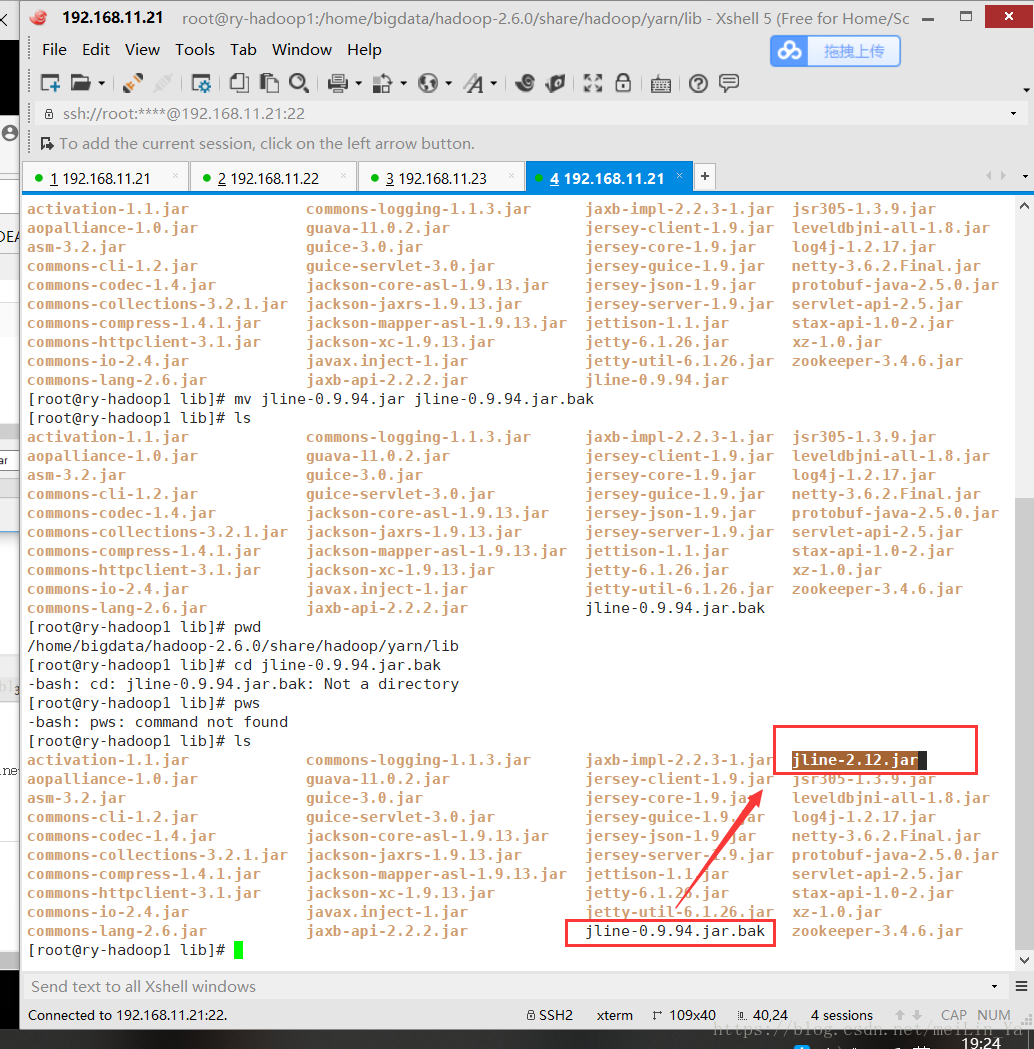
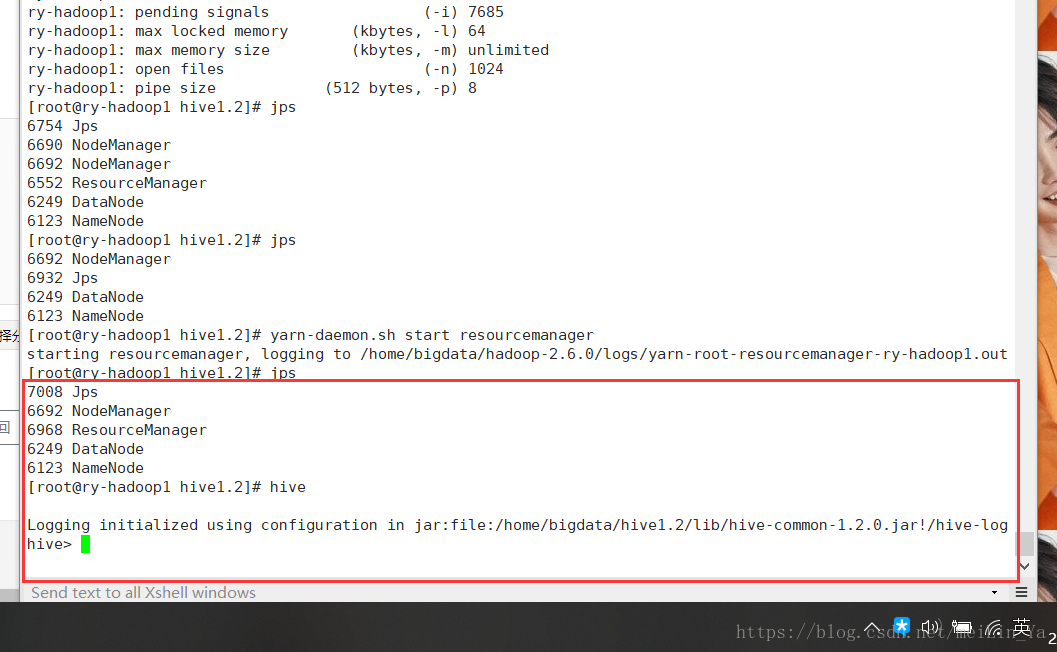
然后启动hive,启动hive之前一定要启动集群。
Hive介绍及安装的更多相关文章
- 从零自学Hadoop(14):Hive介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 本系列已 ...
- Hive介绍、安装(转)
1.Hive介绍 1.1 Hive介绍 Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据.它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语 ...
- 1.hive介绍及安装配置
1.Hive介绍 数据库OLTP 在线事务处理 数据仓库OLAP 在线分析处理 延迟高 类sql方式(HQL) 使用sql方式,用来读写,管理位于分布式存储系统上的大型数据集的数据仓库技术 hive是 ...
- Hive介绍和安装部署
搭建环境 部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放 Hadoop等组件运行包.因为该目录用于安装h ...
- hive介绍、安装配置、表操作基础知识适合小白学习
1.hive概述 Apache Hive数据仓库软件有助于使用SQL读取,编写和管理驻留在分布式存储中的大型数据集.可以将结构投影到已存储的数据中.提供了命令行工具和JDBC驱动以将用户连接到Hive ...
- hive学习笔记_hive的介绍与安装
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- Hive学习之一 《Hive的介绍和安装》
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- 从零自学Hadoop(19):HBase介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一篇, ...
- Spark入门实战系列--5.Hive(上)--Hive介绍及部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Hive介绍 1.1 Hive介绍 月开源的一个数据仓库框架,提供了类似于SQL语法的HQ ...
随机推荐
- java框架之SpringBoot(8)-嵌入式Servlet容器
前言 SpringBoot 默认使用的嵌入式 Servlet 容器为 Tomcat,通过依赖关系就可以看到: 问题: 如何定制和修改 Servlet 容器相关配置? SpringBoot 能否支持其它 ...
- python基础(6)-深浅拷贝
赋值 字符串和数字 # id()函数可以获取变量在内存中的地址标识 num1 = 2; num2 = 2; print(id(num1)) # result:8791124202560 print(i ...
- python框架之Django(16)-接入Redis
准备 安装Redis 参考 Ubuntu 中 Redis 的安装与使用. 在python中使用Redis 参考 python 中使用 Redis . 安装依赖包 在 Django 中接入 Redis ...
- 9个用来爬取网络站点的 Python 库
上期入口:10个不到500行代码的超牛Python练手项目 1️⃣Scrapy 一个开源和协作框架,用于从网站中提取所需的数据. 以快速,简单,可扩展的方式. 官网:https://scrapy.or ...
- WAR包方式安装Jenkins
WAR包方式安装Jenkins 系统环境: CentOS 7.5 1804 IP:192.168.1.3 关闭selinux.firewalld jenkins war包:下载地址 一.安装t ...
- 第三章 jQuery事件和动画
1.什么是事件:事件指的是用于对网页操作的时候,网页做出的一个回应. 2.JQuery中的事件:JQuery事件是对JavaScript事件的封装,常用事件的分类如下:(1)基础事件:window事件 ...
- pypi上传命令
windows 1.新建一个setup.py文件与你自己写的.py模块放在一个文件夹内 内容: from distutils.core import setup setup( name = " ...
- Android项目第一天,下载安装Android Studio和“我的第一个安卓项目”
一.AS的下载我是在AS官方网站进行下载的最新版本,如图所示 二.AS的安装过程 点击你下载的安装包安装即可,傻瓜式一站到底. 到这一步时选择第二个按钮, 随后出现如下界面 这个窗口是提示我们设置代理 ...
- vs2017 exe在Linux上运行
1:将vs .netcore控制台项目发布打包(比如文件名为:demo2core.zip,以下会用到) 2:使用XShell软件连接Linux a.在linux上使用命令 id addr找出ip地址 ...
- python爬虫——对爬到的数据进行清洗的一些姿势(5)
做爬虫,当然就要用数据.想拿数据进行分析,首先清洗数据.这个清洗数据包括清除无用数据列和维度,删除相同数据,对数据进行勘误之类的. 从各大不同新闻网站可以爬到重复新闻...这个可以有.之前为了对爬到的 ...