实现text-detection-ctpn一路的坎坎坷坷
小编在学习文字检测,因为作者提供的caffe实现没有训练代码(不过训练代码可以参考faster-rcnn的训练代码),所以我打算先使用tensorflow实现,主要是复现前辈的代码,主要是对文字检测模型进行训练。
代码的GitHub地址:https://github.com/eragonruan/text-detection-ctpn
主要写一下自己实现的过程,因为原文给的步骤,小编没有完全实现,所以首先打算解读一下原文步骤,然后加上自己的理解,写下自己可以实现的步骤。
文本检测概述
文本检测可以看成特殊的目标检测,但是它有别与通过目标检测,在通用目标检测中,每个目标都有定义好的边界框,检测出的bbox与当前目标的groundtruth重叠率大于0.5就表示该检测结果正确,文本检测中正确检出需要覆盖整个文本长度,且评判的标准不同于通用目标检测,具体的评判方法参见(ICDAR 2017 RobustReading Competition).所以通用的目标检测方法并不适用文本检测。
1,参数设置
parameters
there are some parameters you may need to modify according to your requirement, you can find them in ctpn/text.yml
- USE_GPU_NMS # whether to use nms implemented in cuda or not
- DETECT_MODE # H represents horizontal mode, O represents oriented mode, default is H
- checkpoints_path # the model I provided is in checkpoints/, if you train the model by yourself,it will be saved in output/
1.1 对其进行翻译如下:
根据我们的一些要求,我们可能需要修改一些参数,文件在ctpn/text.yml
- USE_GPU_NMS 是否使用在cuda中实现的nms
- DETECT_MODE H表示水平模式,O表示定向模式,默认为H
- checkpoints_path 作者提供的模型在checkpoints/ 如果我们自己训练模型,它将保存在 output/ 下面
自己训练的模型在这个路径下面:
checkpoints_path: output/ctpn_end2end/voc_2007_trainval
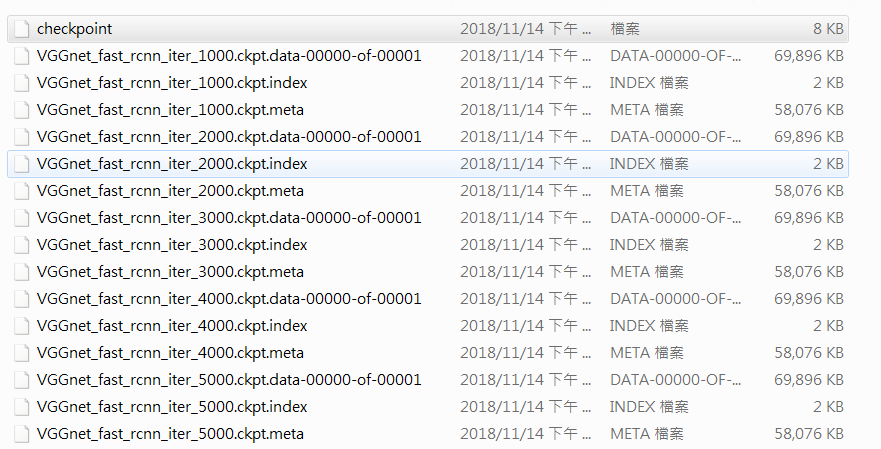
下面展示一下小编训练出来的模型:
2:环境设置
setup
- requirements: python2.7, tensorflow1.3, cython0.24, opencv-python, easydict,(recommend to install Anaconda)
- if you have a gpu device, build the library by
cd lib / utils
chmod + x make.sh
./make.sh
2.1 对其进行翻译如下:
需求的是python2.7 tensorflow1.3 cython0.24,opencv-python,easydict,(建议安装Anaconda)
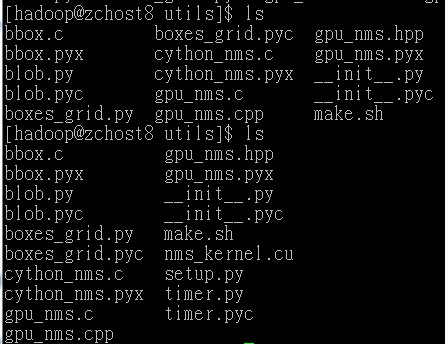
(因为我有GPU)所以直接进行第三步,进入lib、utils,执行chmod+x给权限(在给权限之前,make.sh是灰色的(不可执行的文件),执行chmod+x make.sh 则变成绿色(可执行的文件))
3:准备数据
prepare data
- First, download the pre-trained model of VGG net and put it in data/pretrain/VGG_imagenet.npy. you can download it from google drive or baidu yun.
- Second, prepare the training data as referred in paper, or you can download the data I prepared from google drive or baidu yun. Or you can prepare your own data according to the following steps.
- Modify the path and gt_path in prepare_training_data/split_label.py according to your dataset. And run
cd lib/prepare_training_data
python split_label.py
- it will generate the prepared data in current folder, and then run
python ToVoc.py
- to convert the prepared training data into voc format. It will generate a folder named TEXTVOC. move this folder to data/ and then run
cd ../../data
ln -s TEXTVOC VOCdevkit2007
3.1 对其进行翻译
- 首先,下载预先训练的VGG网络模型并将其放在data/pretrain/VGG_imagenet.npy.
- 其次,准备论文提到的训练数据。或者我们可以放置自己的数据
- 根据我们的数据集修改prepare_training_data/split_label.py中的path和gt_path路径。并执行下面操作。
cd lib/prepare_training_data
python split_label.py
- 它将在当前文件夹中生成准备好的数据,然后运行下面代码:
python ToVoc.py
- 将准备好的训练数据转换为voc格式。它将生成一个名为TEXTVOC的文件夹。将此文件夹移动到数据/然后运行
cd ../../data
ln -s TEXTVOC VOCdevkit2007
3.2 数据是否只有VOC2007?
作者给的数据是预处理过的数据,
我们下载了数据,VOCdevkit2007 只有1.06G,但是此数据可以训练自己的模式,要是想训练自己的数据,那么需要自己标注数据,找自己的数据。
作者使用的icdar17的multi lingual scene text dataset, 没有用voc,只是用了他的数据格式,下面给出的数据是作者实现的源数据地址。
gt_path的数据地址:http://rrc.cvc.uab.es/?com=contestant
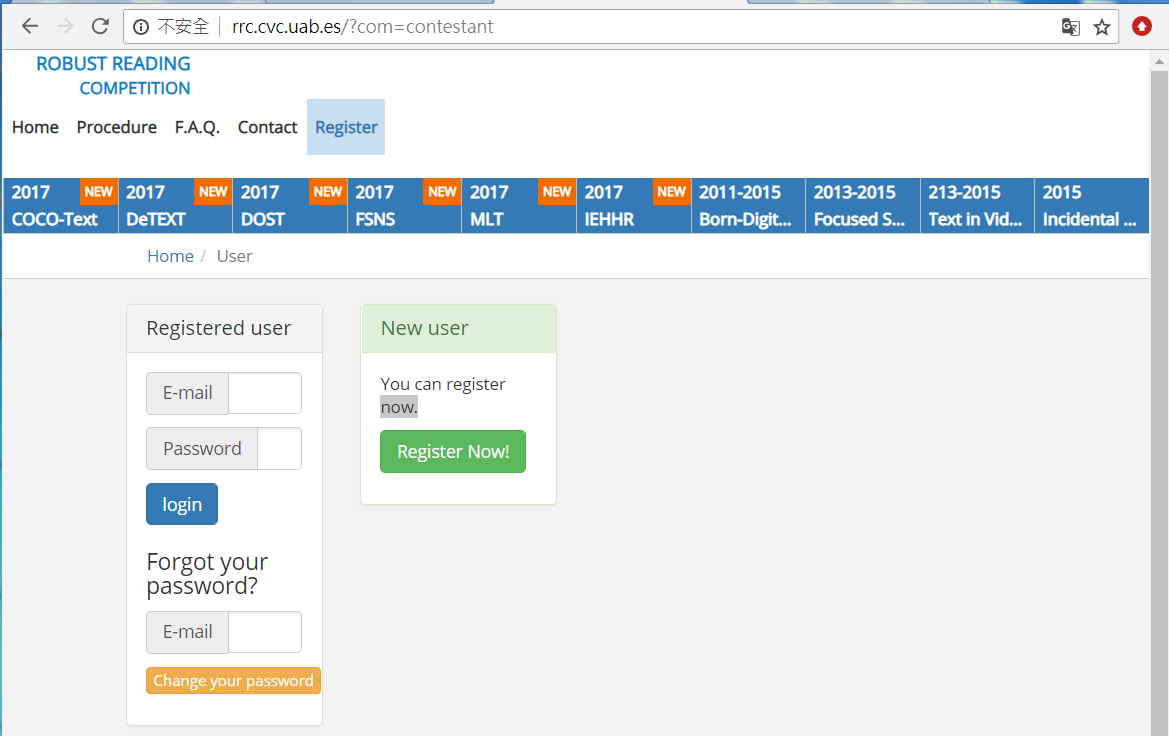
进入2017MLT 查看如下:
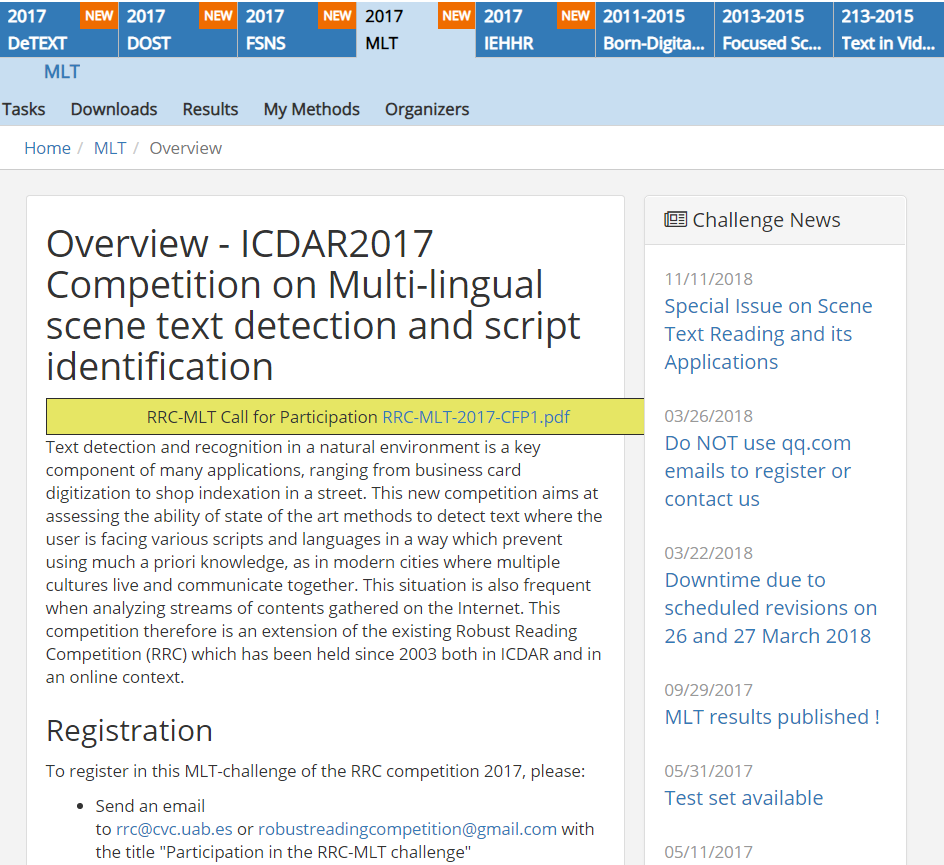
然后我们可以发送邮件,注册用户,并激活,进入下载页面:
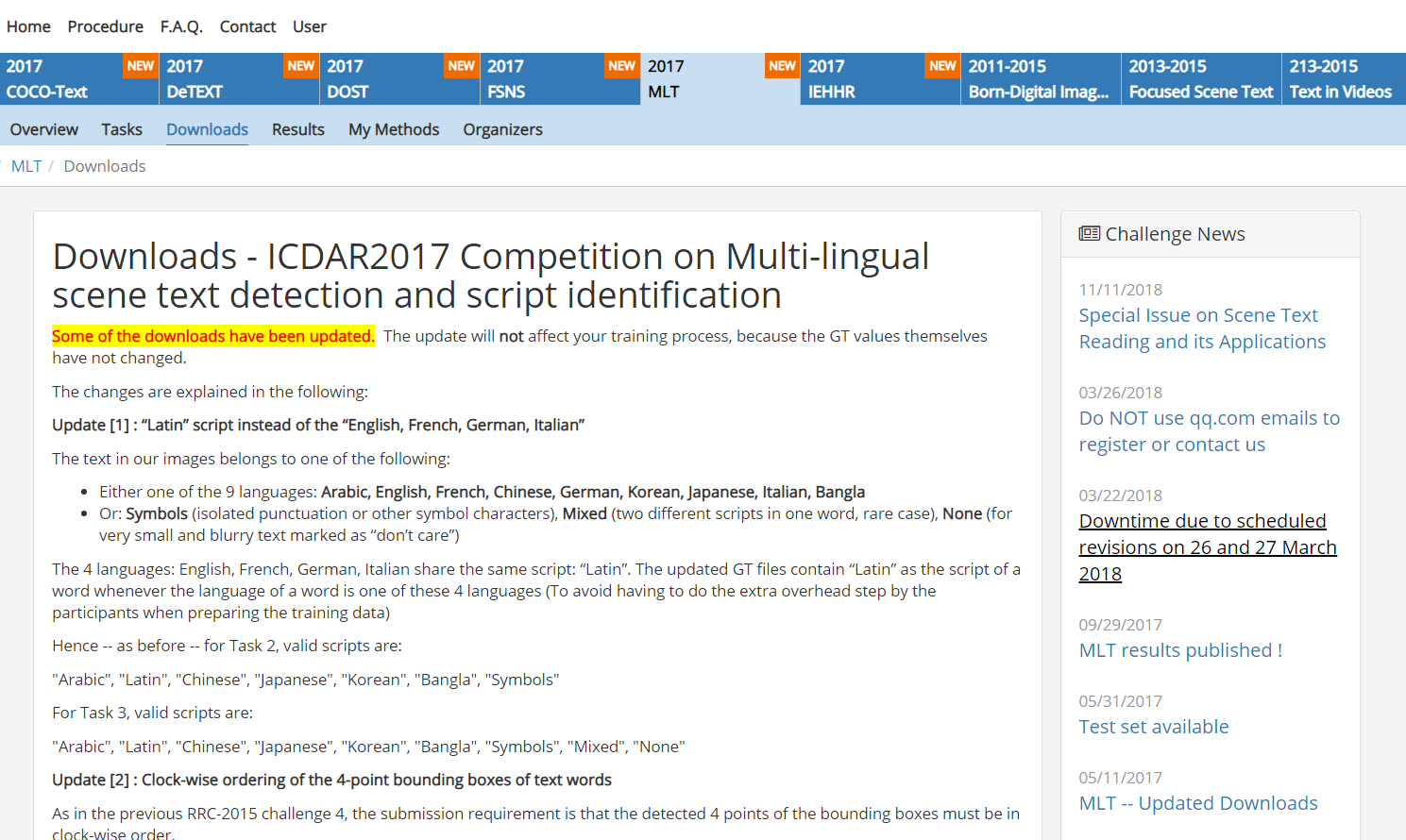
找到数据集并下载,因为这是国外网址,所以被墙了,小编没有全部下载下来,就走到了这一步,目前没有下一步(如果有人看到这篇博文,希望把下载的数据能分享给我,先在这里道声谢!!!):
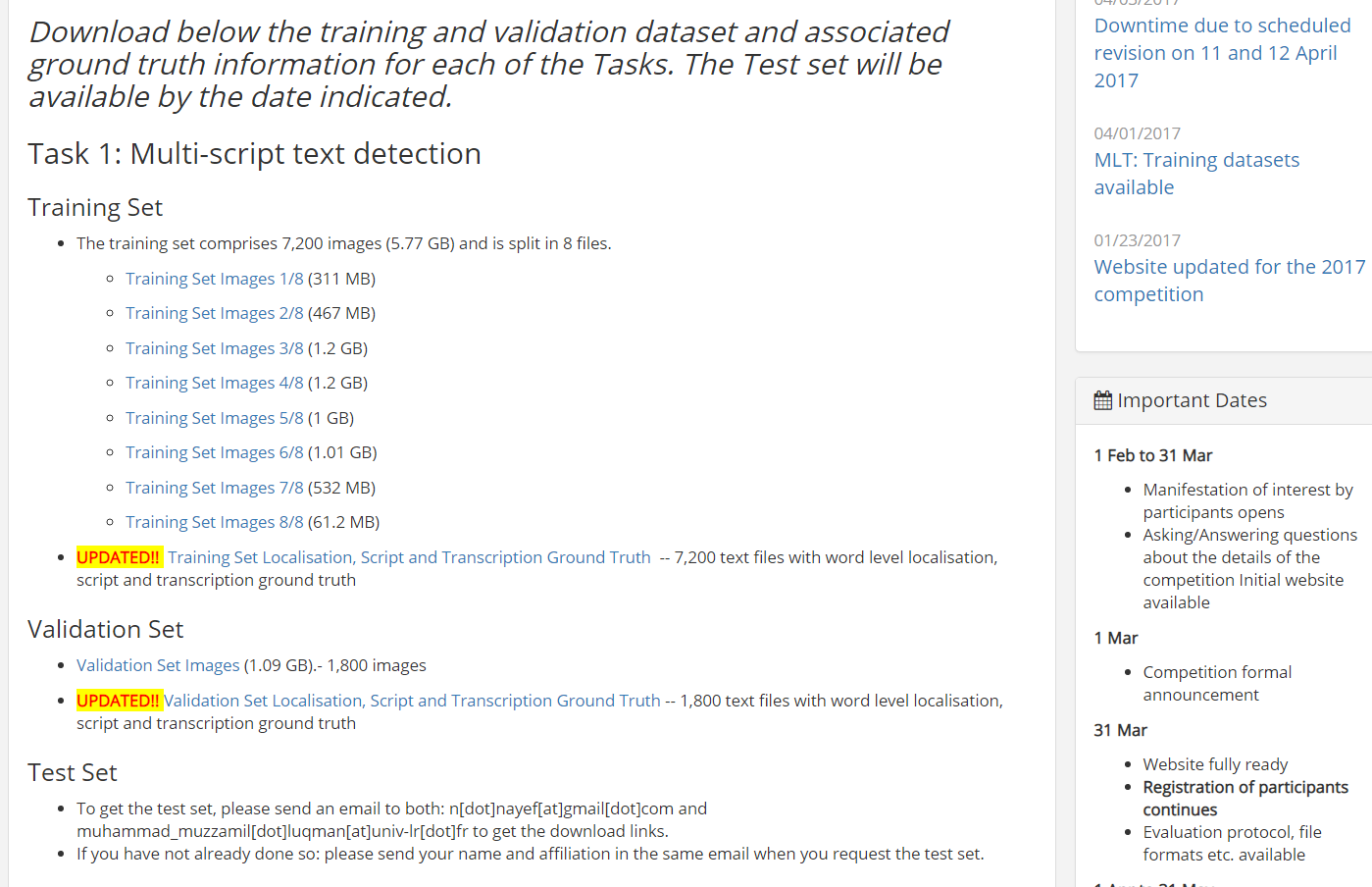
3.3 存放数据
作者训练使用的是6000张图片。使用train或者trainval是一样的,因为用的都是这6000张图片。可以检查一下VOCdevkit2007/VOC2007/ImageSets/Main下面的train.txt和trainval.txt是否正确,是否是6000张图片。你在用自己数据训练的时候也要特别注意一点,数据的标注格式是不是和mlt这个数据集一致,因为split_label这个函数是针对mlt的标注格式来写的,所以如果你原始数据标注格式如果和它不同,转换之后可能会是错的,那么得到的用来训练的数据集可能也不对。
这是作者存放数据的路径,我们修改路径,并放数据(因为源数据没有拿到,所以就数据存放也就做到这一步,没有后续!!)。

对原始gt文件进一步处理的分析(也就是对txt标注数据进行进一步处理),生成对应的xml文件部分内容截图如下:
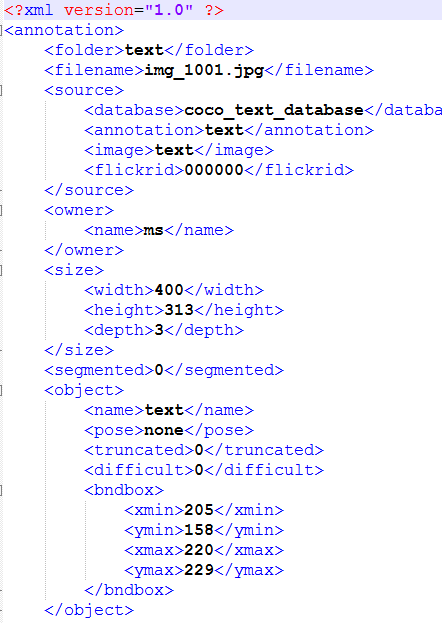
对split_label的部分代码截取如下:
for file in files:
_, basename = os.path.split(file)
if basename.lower().split('.')[-1] not in ['jpg', 'png']:
continue
stem, ext = os.path.splitext(basename)
gt_file = os.path.join(gt_path, 'gt_' + stem + '.txt')
img_path = os.path.join(path, file)
print(img_path)
img = cv.imread(img_path)
img_size = img.shape
im_size_min = np.min(img_size[0:2])
im_size_max = np.max(img_size[0:2]) im_scale = float(600) / float(im_size_min)
if np.round(im_scale * im_size_max) > 1200:
im_scale = float(1200) / float(im_size_max)
re_im = cv.resize(img, None, None, fx=im_scale, fy=im_scale, interpolation=cv.INTER_LINEAR)
re_size = re_im.shape
cv.imwrite(os.path.join(out_path, stem) + '.jpg', re_im) with open(gt_file, 'r') as f:
lines = f.readlines()
for line in lines:
splitted_line = line.strip().lower().split(',')
pt_x = np.zeros((4, 1))
pt_y = np.zeros((4, 1))
pt_x[0, 0] = int(float(splitted_line[0]) / img_size[1] * re_size[1])
pt_y[0, 0] = int(float(splitted_line[1]) / img_size[0] * re_size[0])
pt_x[1, 0] = int(float(splitted_line[2]) / img_size[1] * re_size[1])
pt_y[1, 0] = int(float(splitted_line[3]) / img_size[0] * re_size[0])
pt_x[2, 0] = int(float(splitted_line[4]) / img_size[1] * re_size[1])
pt_y[2, 0] = int(float(splitted_line[5]) / img_size[0] * re_size[0])
pt_x[3, 0] = int(float(splitted_line[6]) / img_size[1] * re_size[1])
pt_y[3, 0] = int(float(splitted_line[7]) / img_size[0] * re_size[0]) ind_x = np.argsort(pt_x, axis=0)
pt_x = pt_x[ind_x]
pt_y = pt_y[ind_x] if pt_y[0] < pt_y[1]:
pt1 = (pt_x[0], pt_y[0])
pt3 = (pt_x[1], pt_y[1])
else:
pt1 = (pt_x[1], pt_y[1])
pt3 = (pt_x[0], pt_y[0]) if pt_y[2] < pt_y[3]:
pt2 = (pt_x[2], pt_y[2])
pt4 = (pt_x[3], pt_y[3])
else:
pt2 = (pt_x[3], pt_y[3])
pt4 = (pt_x[2], pt_y[2]) xmin = int(min(pt1[0], pt2[0]))
ymin = int(min(pt1[1], pt2[1]))
xmax = int(max(pt2[0], pt4[0]))
ymax = int(max(pt3[1], pt4[1])) if xmin < 0:
xmin = 0
if xmax > re_size[1] - 1:
xmax = re_size[1] - 1
if ymin < 0:
ymin = 0
if ymax > re_size[0] - 1:
ymax = re_size[0] - 1 width = xmax - xmin
height = ymax - ymin # reimplement
step = 16.0
x_left = []
x_right = []
x_left.append(xmin)
x_left_start = int(math.ceil(xmin / 16.0) * 16.0)
if x_left_start == xmin:
x_left_start = xmin + 16
for i in np.arange(x_left_start, xmax, 16):
x_left.append(i)
x_left = np.array(x_left) x_right.append(x_left_start - 1)
for i in range(1, len(x_left) - 1):
x_right.append(x_left[i] + 15)
x_right.append(xmax)
x_right = np.array(x_right) idx = np.where(x_left == x_right)
x_left = np.delete(x_left, idx, axis=0)
x_right = np.delete(x_right, idx, axis=0) if not os.path.exists('label_tmp'):
os.makedirs('label_tmp')
with open(os.path.join('label_tmp', stem) + '.txt', 'a') as f:
for i in range(len(x_left)):
f.writelines("text\t")
f.writelines(str(int(x_left[i])))
f.writelines("\t")
f.writelines(str(int(ymin)))
f.writelines("\t")
f.writelines(str(int(x_right[i])))
f.writelines("\t")
f.writelines(str(int(ymax)))
f.writelines("\n")
3.4 参考知乎大神的准备数据如下:
数据标注
在标注数据的时候采用的是顺时针方向,一次是左上角坐标点,右上角坐标点,右下角坐标点,左下角坐标点(即x1,y1,x2,y2,x3,y3,x4,y4),,这里的标注方式与通用目标检测的目标检测方式一样,这里我标注的数据是生成到txt中,具体格式如下:
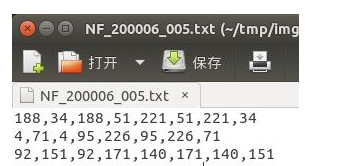
x1,y1,x2,y2,x3,y3,x4,y4 分别是一个框的四个角点的x,y坐标。这是因为作者用的mlt训练的,他的数据就是这么标注的,如果你要用一些水平文本的数据集,标注是x,y,w,h的,也是可以的,修改一下split_label的代码,或者写个小脚本把x,y,w,h转换成x1,y1,x2,y2,x3,y3,x4,y4就行。
数据处理
根据ctpn训练数据的要求,需要对上述数据(txt标注数据)进行进一步的处理,生成对应的xml文件,具体格式参考pascal voc 具体的训练数据截图和生成的pascal voc格式如下图:

处理数据的时候执行下面代码(和原文一致)
cd lib/prepare_training_data
python split_label.py
python ToVoc.py
cd ../../data
ln -s TEXTVOC VOCdevkit2007
注意:这里生成的数据会在当前目录下,文件夹为TEXTVOC,需要将该文件夹移至/data目录下,然后再做VOCdevikt2007的软连接。
3.5 准备数据注意事项
在原作者使用那6000张图片的话,roidb和image_index都是6000,因为使用的train和trainval是一样的,所以我们在使用自己数据训练的时候也要特别注意一点,数据的标注格式是不是与mlt这个数据集一致,因为split_label这个函数是针对mlt的标注格式来写的,所以我们原始数据标注格式如果和它不同,转化之后可能会是错的,那么得来的用来训练的数据集可能也不对。
cache是为了加速数据读取,所以不会每次重新生成,更换了数据集需要手动清理。
3.6 训练数据的格式是什么样子,是否需要准备图片?
其实想了解自己准备图片的格式,以及图片中的文字区域的坐标是否需要手动标出,才能训练。
上面也说了训练数据的格式是x1,y1,x2,y2,x3,y3,x4,y4 ,当然了自己标注比较麻烦,这里我们可以直接使用一些公开的数据集,原作者使用的额是multi lingual scene texts dataset。
4:训练
Simplely run
python ./ctpn/train_net.py
- you can modify some hyper parameters in ctpn/text.yml, or just used the parameters I set.
- The model I provided in checkpoints is trained on GTX1070 for 50k iters.
- If you are using cuda nms, it takes about 0.2s per iter. So it will takes about 2.5 hours to finished 50k iterations.
4.1:对其进行翻译
简单的运行
你可以在ctpn/text.yml中修改一些参数,或者只使用作者设置的参数
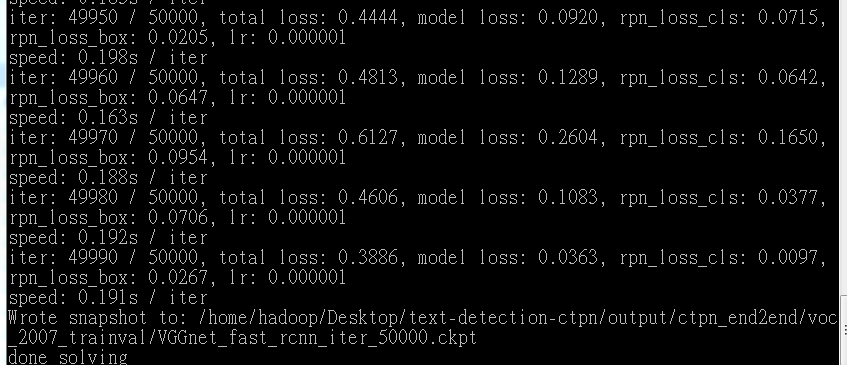
作者提供的模型在GTX1070上训练了50K iters
如果我们正在使用cuda nms ,它每次约需要0.2秒,因此完成50k迭代需要大约2.5小时
当然,我们可以指定在那块显卡上运行,比如我这里指定选择第一块显卡上训练,训练的命令如下:
CUDA_VISIBLE_DEVICES="0" python ./ctpn/train_net.py
4.2 成功运行截图!!!
4.3:执行训练代码报的一个错误如下
AttributeError: module 'tensorflow.python.ops.gen_logging_ops' has no attribute '_image_summary'
tensroflow 新版本相较于一些老版本更改了一些函数和变量类型。可以到 \lib\fast_rcnn\train.py 内尝试把 build_image_summary(self) 函数整体替换为以下语句:
def build_image_summary(self):
# A simple graph for write image summary
log_image_data = tf.placeholder(tf.uint8, [None, None, 3])
log_image_name = tf.placeholder(tf.string)
from tensorflow.python.ops import gen_logging_ops
from tensorflow.python.framework import ops as _ops
log_image = tf.summary.image(str(log_image_name),
tf.expand_dims(log_image_data, 0), max_outputs=1)
_ops.add_to_collection(_ops.GraphKeys.SUMMARIES, log_image)
return log_image, log_image_data, log_image_name
也就是把原文中那句替换成下面这句:
log_image = tf.summary.image(str(log_image_name),
tf.expand_dims(log_image_data, 0), max_outputs=1)
4.4 在训练时候,训练集扩展了2倍,目的是什么?
在训练时候,训练集扩展了2倍,图片倍翻转了,这样做的目的是扩展训练集。
5:部分代码解析
5.1 train_net.py的代码解析
import os.path
import pprint
import sys #os.getcwd()返回当前工作目录 sys.path.append()用于将前面的工作目录添加到搜索路径中
sys.path.append(os.getcwd())
from lib.fast_rcnn.train import get_training_roidb, train_net
from lib.fast_rcnn.config import cfg_from_file, get_output_dir, get_log_dir
from lib.datasets.factory import get_imdb
from lib.networks.factory import get_network
from lib.fast_rcnn.config import cfg if __name__ == '__main__':
#存放训练参数
cfg_from_file('ctpn/text.yml')
print('Using config:')
# pprint函数的pprint模块下的方法是一种标准的格式化输出方式。
# pprint(object, stream=None, indent=1, width=80, depth=None, *, compact=False)
# 这里是将训练的参数格式化显示出来
pprint.pprint(cfg)
# 读取VOC中的数据集
imdb = get_imdb('voc_2007_trainval')
print('Loaded dataset `{:s}` for training'.format(imdb.name))
# 获得感兴趣区域的数据集
roidb = get_training_roidb(imdb) # 返回程序运行结果存放的文件夹的路径
output_dir = get_output_dir(imdb, None)
# 返回程序运行时中间过程产生的文件。
log_dir = get_log_dir(imdb)
print('Output will be saved to `{:s}`'.format(output_dir))
print('Logs will be saved to `{:s}`'.format(log_dir)) device_name = '/gpu:0'
print(device_name) # 获取VGG网络结构 定义网络结构
network = get_network('VGGnet_train') train_net(network, imdb, roidb,
output_dir=output_dir,
log_dir=log_dir,
pretrained_model='data/pretrain/VGG_imagenet.npy',
max_iters=int(cfg.TRAIN.max_steps),restore=bool(int(cfg.TRAIN.restore)))
#采用VGG_Net 输入训练图片的数据集,感兴趣区域的数据集等开始训练。。
6,图片标注方法
如果想训练自己的数据集,那么我们可以自己去标注图片。本文将推荐一个十分好用的数据标注工具LabelImg。
这款工具是全图形界面,用Python和Qt写的,最牛的是其标注信息可以直接转化成为XML文件,与PASCAL VOC以及ImageNet用的XML是一样的。(具体如何使用,直接参考下面GitHub或者网上百度即可)
它来自下面的项目:https://github.com/tzutalin/labelImg
其中标签存储功能和“Next Image”、“Prev Image”的设计使用起来比较方便。
该软件最后保存的xml文件格式和ImageNet数据集是一样的。
- Labelme 适用于图像分割任务的数据集制作
- labellmg适用于图像检测任务的数据集制作
- yolo_mark适用于图像检测任务的数据集制作
- Vatic适用于图像检测任务的数据集制作
参考文献:https://zhuanlan.zhihu.com/p/37363942
http://slade-ruan.me/2017/10/22/text-detection-ctpn/
实现text-detection-ctpn一路的坎坎坷坷的更多相关文章
- 论文阅读(Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition)
Xiang Bai--[TIP2014]A Unified Framework for Multi-Oriented Text Detection and Recognition 目录 作者和相关链接 ...
- 论文阅读(Xiang Bai——【arXiv2016】Scene Text Detection via Holistic, Multi-Channel Prediction)
Xiang Bai--[arXiv2016]Scene Text Detection via Holistic, Multi-Channel Prediction 目录 作者和相关链接 方法概括 创新 ...
- 论文阅读(Zhuoyao Zhong——【aixiv2016】DeepText A Unified Framework for Text Proposal Generation and Text Detection in Natural Images)
Zhuoyao Zhong--[aixiv2016]DeepText A Unified Framework for Text Proposal Generation and Text Detecti ...
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
Xiang Bai--[CVPR2016]Multi-Oriented Text Detection with Fully Convolutional Networks 目录 作者和相关链接 方法概括 ...
- 论文速读(Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection)
Chuhui Xue--[arxiv2019]MSR_Multi-Scale Shape Regression for Scene Text Detection 论文 Chuhui Xue--[arx ...
- 【论文速读】XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection
XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection 作者和代码 caffe代码 关键词 ...
- 【论文速读】Fangfang Wang_CVPR2018_Geometry-Aware Scene Text Detection With Instance Transformation Network
Han Hu--[ICCV2017]WordSup_Exploiting Word Annotations for Character based Text Detection 作者和代码 caffe ...
- 【论文速读】Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping
Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrappi ...
- 【速读】——Shangxuan Tian——【ICCV2017】WeText_Scene Text Detection under Weak Supervision
Shangxuan Tian——[ICCV2017]WeText_Scene Text Detection under Weak Supervision 目录 作者和相关链接 文章亮点 方法介绍 方法 ...
随机推荐
- 数据库-mysql语句-查
复习: 列类型: 数值类型: 20 '20' tinyint / smallint / int / bigint float / double / decimal(m,d) bool (TRU ...
- Python从入门到精通之First!
Python的种类 Cpython Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上. Jy ...
- linux 系统管理学习
Linux系统管理一.进程管理1.进程管理的作用1)判断服务器健康状态2)查看系统中所有进程3)杀死进程2.进程的查看1)查看所有进程ps aux 查看系统中所有进程ps -le 查看系统中所有进程- ...
- js计算器---转
至今见过的一个还没问题的计算器,收藏在此. 转自javascript写的简单的计算器原文链接,谢分享! js部分 ar num=0,result=0,numshow="0"; va ...
- PowerShell 使用.NetFramework
我们都知道,由于PowerShell是基于.NETFramework建立的所以它能够具备访问.NET的能力,因为.NET提供了庞大的数据类库,所以我们可以很好的使用PowerShell去完成一些Pow ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十七之铭文升级版
铭文一级: 功能1:今天到现在为止 实战课程 的访问量 yyyyMMdd courseid 使用数据库来进行存储我们的统计结果 Spark Streaming把统计结果写入到数据库里面 可视化前端根据 ...
- Anton 上课题
Anton 上课题 Anton likes to play chess. Also he likes to do programming. No wonder that he decided to a ...
- Django Model 进阶
回顾: 定义 models settings.py激活app才能使用models migrations:版本控制,当更改库表结构时可以处理数据 增删改查 常见Field 模型的价值在于定义数据模型,使 ...
- Mac 下 Java 多版本切换
Step 1: 安装 jdk1.7 jdk1.8 路径如下: + /Library/Java/JavaVirtualMachines/jdk1.7.0_80.jdk + /Library/Java/J ...
- CPP全面总结(涵盖C++11标准)
OOP之类和对象 1. this指针的引入 每个成员函数都有一个额外的隐含的形参,这个参数就是this指针,它指向调用对象的地址.默认情况下,this的类型是指向类类型非常量版本的常量指针.可以表示成 ...