IO学习
---恢复内容开始---
命名规则:
1、类名使用 UpperCamelCase 风格,必须遵从驼峰形式,但以下情形例外:(领域模型 的相关命名)DO / BO / DTO / VO 等。
2、方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格,必须遵从 驼峰形式。
正例: localValue / getHttpMessage() / inputUserId
3、常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
正例: MAX_STOCK_COUNT 反例: MAX_COUNT
4、抽象类命名使用 Abstract 或 Base 开头;异常类命名使用 Exception 结尾;测试类 命名以它要测试的类的名称开始,以 Test 结尾。
Java 流式输入输出
java中的数据的输入/输出操作以流(stream)方式进行;
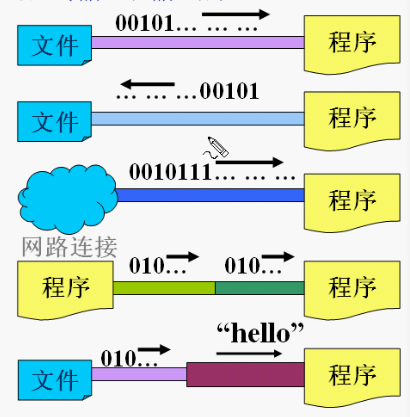

java.io(输入输出站在程序的角度看)
字节流:InputStream OutputStream
字符流: Reader Writer (2字节-UTF16)
节点流和处理流
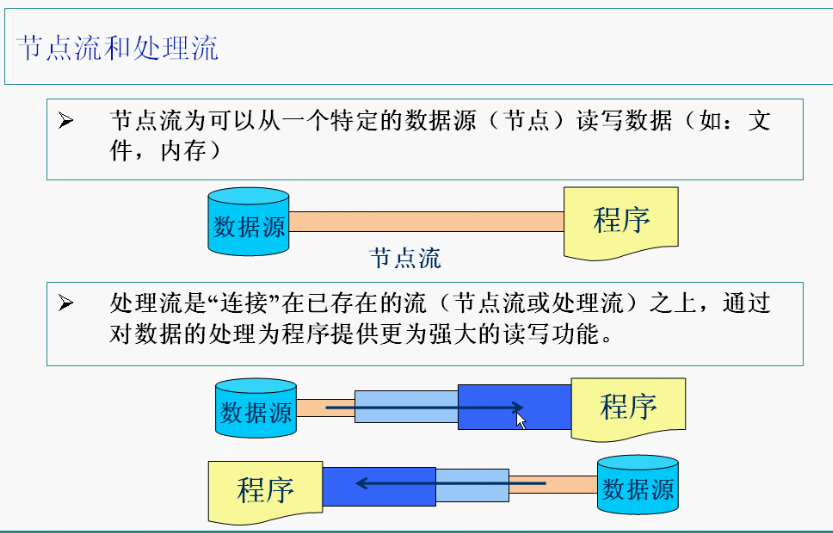
节点流:
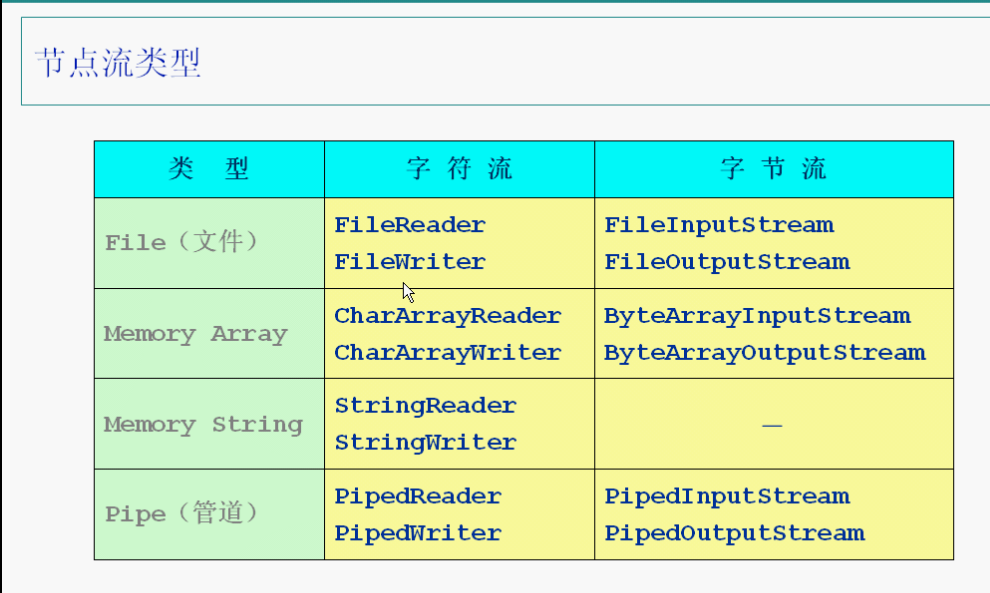
FileInputStream和FileOutputStream
FileDescriptor 是“文件描述符”。
FileDescriptor 可以被用来表示开放文件、开放套接字等。
以FileDescriptor表示文件来说:当FileDescriptor表示某文件时,我们可以通俗的将FileDescriptor看成是该文件。但是,我们不能直接通过FileDescriptor对该文件进行操作;若需要通过FileDescriptor对该文件进行操作,则需要新创建FileDescriptor对应的FileOutputStream,再对文件进行操作。
java文件路径,注意与windows系统进行区别
windows文件系统: D:\workspace
java程序设计: D:\\workspace\\hello.txt或者 D:/workspace/hello.txt
---java路径分隔符,一般为"/"或者"\\"
使用FileReader或BufferedReader从文件中读取字符或文本数据,并总是指定字符编码;使用FileInputStream从Java中文件或套接字中读取原始字节流。
import java.io.*;
public class TestInputStream {
public static void main(String[] args){
int b = 0;
FileInputStream in = null;//create a FileInputStream Object
try {
in = new FileInputStream("D:/workspace/helloworld.txt"); //opening a connection to an actual file
} catch(FileNotFoundException e) { // exception
System.out.println("找不到指定文件");
System.exit(-1);//捕获到异常,就退出程序。exit(a):a=0代表正常退出,a != 0代表非正常退出。
} try {
long num = 0;
while (( b = in.read()) != -1) { //Reads a byte of data from this input stream
System.out.println((char)b); // return -1 if the end of the file is reached.
num++;
} in.close(); //Closes this file input stream and releases any system resources associated with the stream.
System.out.println();
System.out.println("共读取了"+num+"个字节");
} catch(IOException e) {
System.out.println("文件读取错误");
System.exit(-1);
}
}
}
FileReader 和 FileWrite
import java.io.*;
public class HelloFileReader {
public static void main(String[] args){
FileReader fr = null;
int c =0;
try {
fr = new FileReader("D:/workspace/helloworld.txt");
int ln = 0;
while ((c = fr.read()) != -1){
System.out.println((char)c);
}
fr.close();
} catch(FileNotFoundException e) {
System.out.println("找不到指定文件");
} catch (IOException e){
System.out.println("文件读取错误");
}
}
}
FileReader
import java.io.*;
public class TestFileWrite {
public static void main(String[] args){
FileWriter fw = null;
try {
fw = new FileWriter("D:/workspace/hello.bat");
for (int c = ;c <= ;c++){
fw.write(c);
}
fw.close();
} catch(IOException e) {
e.printStackTrace();
System.out.println("无法找到文件");
System.exit();//终止JVM
}
}
}
BufferedInputStream示例
import java.io.*;
public class TestBufferStream1 {
public static void main(String[] args){
try {
FileInputStream fis =
new FileInputStream("D:/workspace/helloworld.txt");
BufferedInputStream bis = new BufferedInputStream(fis);
int c = ;
System.out.println((char)bis.read());
System.out.println((char)bis.read());
bis.mark();//直接从第100个开始读
for (int i = ;i < &&(c = bis.read()) != -;i++){
System.out.println((char) c+"");
}
System.out.println();//打印空行
bis.reset();//回到第100个的标记
for (int i = ;i < &&(c = bis.read()) != -;i++){
System.out.println((char) c+"");
}
bis.close();
} catch(IOException e) {
e.printStackTrace();
}
}
}
BufferedWriter示例
import java.io.*;
public class TestBufferedWritee {
public static void main(String[] args){
try {
BufferedWriter bw = new BufferedWriter(new FileWriter("D:/workspace/world.txt"));
BufferedReader br = new BufferedReader(
new FileReader("D:/workspace/world.txt"));//throw 的IllegalArgumentException 属于RuntimeException可以不做处理
String s = null;
for (int i = 1;i <= 100;i++){
s = String.valueOf(Math.random());//random() 随机产生0.0~1.0的双精度浮点型数据
bw.write(s);//Writes a single character.
bw.newLine();//行分隔符
}
bw.flush();//Flushes this buffered output stream.输出时,bufferter需要flush
while ((s = br.readLine()) != null){
System.out.println(s);
}
bw.close();
br.close();
} catch (IOException e){
e.printStackTrace();
}
}
}
IO学习的更多相关文章
- Java IO学习笔记:概念与原理
Java IO学习笔记:概念与原理 一.概念 Java中对文件的操作是以流的方式进行的.流是Java内存中的一组有序数据序列.Java将数据从源(文件.内存.键盘.网络)读入到内存 中,形成了 ...
- Java IO学习笔记总结
Java IO学习笔记总结 前言 前面的八篇文章详细的讲述了Java IO的操作方法,文章列表如下 基本的文件操作 字符流和字节流的操作 InputStreamReader和OutputStreamW ...
- Java IO学习笔记三
Java IO学习笔记三 在整个IO包中,实际上就是分为字节流和字符流,但是除了这两个流之外,还存在了一组字节流-字符流的转换类. OutputStreamWriter:是Writer的子类,将输出的 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- Java IO学习笔记一
Java IO学习笔记一 File File是文件和目录路径名的抽象表示形式,总的来说就是java创建删除文件目录的一个类库,但是作用不仅仅于此,详细见官方文档 构造函数 File(File pare ...
- java IO 学习(三)
java IO 学习(一)给了java io 进行分类,这一章学习这些类的常用方法 一.File 1.创建一个新的File的实例: /** * 创建一个新的File实例 */ File f = new ...
- nodejs的socket.io学习笔记
socket.io学习笔记 1.服务器信息传输: 2.不分组,数据传输: 3.分组数据传输: 4.Socket.io难点大放送(暂时没有搞定): 服务器信息传输 1. // send to curre ...
- 阻塞 io 非阻塞 io 学习笔记
阻塞 io 非阻塞 io 学习笔记
- Java IO学习笔记一:为什么带Buffer的比不带Buffer的快
作者:Grey 原文地址:Java IO学习笔记一:为什么带Buffer的比不带Buffer的快 Java中为什么BufferedReader,BufferedWriter要比FileReader 和 ...
- Java IO学习笔记二:DirectByteBuffer与HeapByteBuffer
作者:Grey 原文地址:Java IO学习笔记二:DirectByteBuffer与HeapByteBuffer ByteBuffer.allocate()与ByteBuffer.allocateD ...
随机推荐
- golang的json序列化问题
首先看一段代码: package main import ( "encoding/json" "fmt" ) type Result struct { //st ...
- Spring AOP的实现研究
1. 背景 在前文Spring IOC容器创建bean过程浅析已经介绍了Spring IOC创建初始化bean的大致过程.现在对Spring的AOP实现机制进行研究分析. 2. 名词与概念 名词 概念 ...
- vue实例生命周期详解
每个 Vue 实例在被创建之前都要经过一系列的初始化过程. 例如,实例需要配置数据观测(data observer).编译模版.挂载实例到 DOM ,然后在数据变化时更新 DOM . 在这个过程中,实 ...
- Intent加强
Intent是一种运行时绑定(runtime binding)机制,它能在程序运行的过程中连接两个不同的组件.通过Intent,你的程序可以向Android表达某种请求或者意愿,Android会根据意 ...
- Android中消息系统模型和Handler Looper
http://www.cnblogs.com/bastard/archive/2012/06/08/2541944.html Android中消息系统模型和Handler Looper 作为Andro ...
- sahrepoint 上传到文档库
sharepoint学习笔记汇总 http://blog.csdn.net/qq873113580/article/details/20390149 /// <summary&g ...
- $Matrix-Tree$定理-理论
$Matrix-Tree$ 矩阵的行列式 这个东西看了好久才明白 _ (:з」∠)_ 时间不够可以直接跳到第六段. 看到这种新定义,第一反应还是去翻百度百科: 但是这个讲解真的让人很迷惑...关键就是 ...
- NOIP2018爆零退役滚粗记
\(Day\ -1\) 非常的颓废 上午考了loli\(\ \ oi\)的最后一轮,\(mhr\)一个小时十五分钟怒切\(260\)分,吊打生爷 发现自己\(T2\)树的直径写怪了,不明觉厉 怕不是要 ...
- Vxlan学习笔记——原理(转)
文章转自http://www.cnblogs.com/hbgzy/p/5279269.html 1. 为什么需要Vxlan 普通的VLAN数量只有4096个,无法满足大规模云计算IDC的需求,而IDC ...
- 分布式爬虫之elasticsearch基础6(bluk)
上篇文章介绍了在es里面批量读取数据的方法mget,本篇我们来看下关于批量写入的方法bulk. bulk api可以在单个请求中一次执行多个索引或者删除操作,使用这种方式可以极大的提升索引性能. bu ...