Spark Streaming简介及原理
简介:
SparkStreaming是一套框架。
SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的,具备容错机制的实时流数据处理。
支持多种数据源获取数据:

Spark Streaming接收Kafka、Flume、HDFS等各种来源的实时输入数据,进行处理后,处理结构保存在HDFS、DataBase等各种地方。
Dashboards:图形监控界面,Spark Streaming可以输出到前端的监控页面上。
*使用的最多的是kafka+Spark Streaming
Spark Streaming和SparkCore的关系:

Spark处理的是批量的数据(离线数据),Spark Streaming实际上处理并不是像Strom一样来一条处理一条数据,而是对接的外部数据流之后按照时间切分,批处理一个个切分后的文件,和Spark处理逻辑是相同的。
Spark Streaming将接收到的实时流数据,按照一定时间间隔,对数据进行拆分,交给Spark Engine引擎,最终得到一批批的结果。

Dstream:Spark Streaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream
假如外部数据不断涌入,按照一分钟切片,每个一分钟内部的数据是连续的(连续数据流),而一分钟与一分钟的切片却是相互独立的(离散流)。
DStream是Spark Streaming特有的数据类型。
Dstream可以看做一组RDDs,即RDD的一个序列:

Spark的RDD可以理解为空间维度,Dstream的RDD理解为在空间维度上又加了个时间维度。
例如上图,数据流进切分为四个分片,内部处理逻辑都是相同的,只是时间维度不同。
Spark与Spark Streaming区别:
Spark -> RDD:transformation action + RDD DAG
Spark Streaming -> Dstream:transformation output(它不能让数据在中间激活,必须保证数据有输入有输出) + DStreamGraph
任何对DStream的操作都会转变为对底层RDD的操作(通过算子):
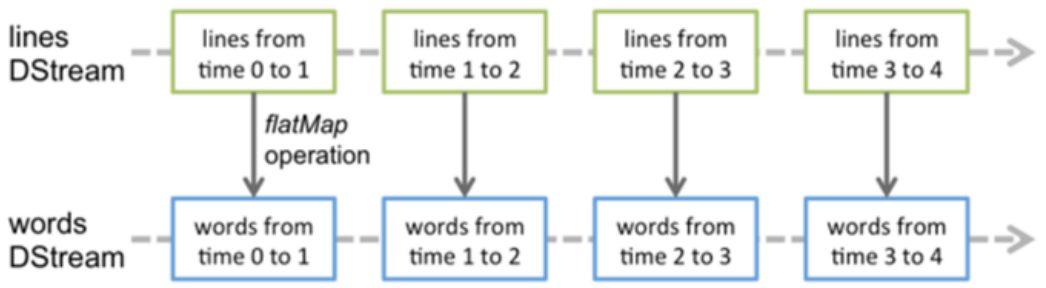
总结:将连续的数据持久化,离散化,然后进行批量处理。
持久化:接收到的数据暂存。
为什么持久化:
做容错的,当数据流出错了,因为没有得到计算,需要把数据从源头进行回溯,暂存的数据可以进行恢复。
离散化:按时间分片,形成处理单元。
分片处理:分批处理。
transformation 转换算子:
reduce,count算子不会直接触发Dstreami计算。
output 执行算子(输出算子):
· saveAsObjectFile、saveAsTextFile、saveAsHadoopFiles:将一批数据输出到Hadoop文件系统中,用批量数据的开始时间
戳来命名
· forEachRDD:允许用户对DStream的每一批量数据对应的RDD本身做任意操作
Dstream Graph:
一系列transformation操作的抽象
Dstream之间的转换所形成的的依赖关系全部保存在DStreamGraph中, DStreamGraph对于
后期生成RDD Graph至关重要
SparkStreaming是一套框架,实际是写代码就是写框架。
框架:先把整个数据计算的流程做一个统一的分析,直到output。
传统Spark开发中涉及到的RDD具有数据不变性,但是SparkStreaming却与其相违背。
所以有了Dstream和Dstream Graph。
框架变成任务执行,其实执行的是spark job,而spark任务只认识RDD。
所以可以把Dstream当成RDD的一个模板,DStream Graph当成RDD DAG的一个模板。
所以写代码就是写Dstream和DStream Graph模板。
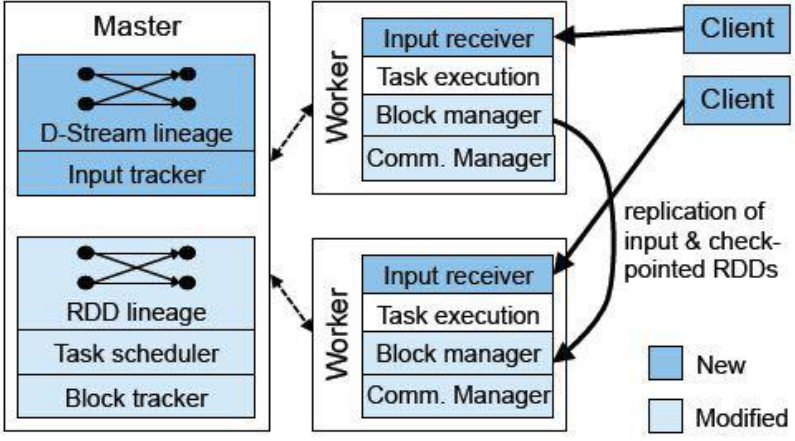
SparkStreaming架构:
Master:记录Dstream之间的依赖关系或者血缘关系,并负责任务调度以生成新的RDD
Worker:从网络接收数据,存储并执行RDD计算
Client:负责向Spark Streaming中灌入数据
调度:按照时间触发。
Master:维护了DStream Graph这张图。(不是节点级别的,是任务级别的)
Worker:按照图去执行。
Worker里面有个重要的角色:receiver,接收外部数据流,然后数据流通过receiver传入整个Spark Streaming 内部(receiver最终把数据流包装成Spark Streaming能处理的格式)
receiver:接收器,接收不同的数据源,进行针对性的获取,Spark Streaming 也提供了不同的接收器分布在不同的节点上,每个接收器都是一个特定的进程,每个节点接收一部分作为输入。,receiver接受完不马上做计算,先存储到它的内部缓存区。因为Streaming 是按照时间不断的分片,所以需要等待,一旦定时器到时间了,缓冲区就会把数据转换成数据块block(缓冲区的作用:按照用户定义的时间间隔切割),然后把数据块放到一个队列里面去,然后Block manager从队列中把数据块拿出来,把数据块转换成一个spark能处理的数据块。
为什么是一个进程?
container -> Executor 所以是一个进程
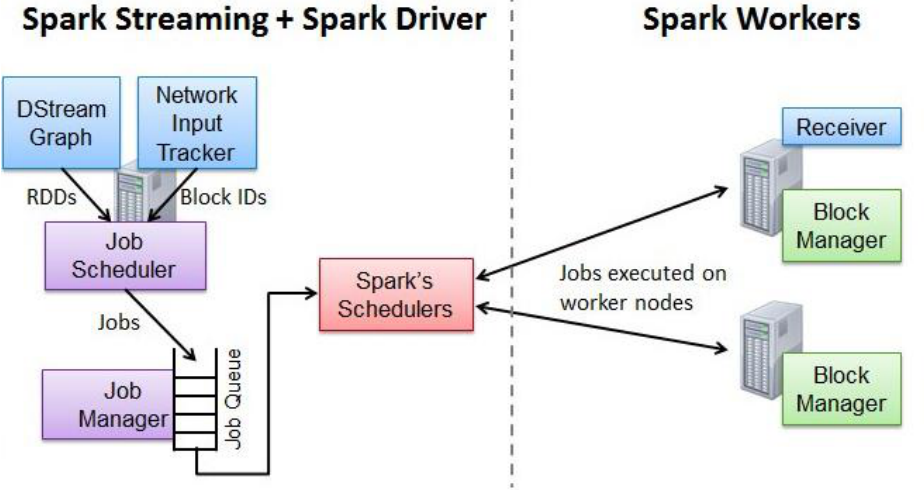
Spark Streaming 作业提交:
• Network Input Tracker:跟踪每一个网络received数据,并且将其映射到相应的input Dstream上
• Job Scheduler:周期性的访问DStream Graph并生成Spark Job,将其交给Job Manager执行
• Job Manager:获取任务队列,并执行Spark任务
Spark Streaming 窗口操作:
• Spark提供了一组窗口操作,通过滑动窗口技术对大规模数据的增量更新进行统计分析
• Window Operation:定时进行一定时间段内的数据处理

• 任何基于窗口操作需要指定两个参数:
– 窗口总长度(window length):你想计算多长时间的数据
– 滑动时间间隔(slide interval):你每多长时间去更新一次
Spark Streaming的容错:
•实时的流式处理系统必须是7*24运行的,同时可以从各种各样的系统错误中恢复,在设计之初,Spark Streaing就支持driver和worker节点的错误恢复(Spark Streaing只有两个节点:driver->AM,worker->NM)
• Worker容错:spark和rdd的保证worker节点的容错性。spark streaming构建在spark之上,
所以它的worker节点也是同样的容错机制
• Driver容错:依赖WAL持久化日志 --------------------------------------------------- Hbase也有WAL
– 启动WAL需要做如下的配置
– 1:给streamingContext设置checkpoint的目录,该目录必须是HADOOP支持的文件系统,用来保存WAL和做
Streaming的checkpoint
– 2:spark.streaming.receiver.writeAheadLog.enable 设置为true
引入了WAL:保证了任何可靠的数据源接收到的数据在失败中都不会丢失。
例如:接收的数据源不支持事物,那么依靠数据源重新发送数据不可靠,所以WAL能尽量避免丢失。
Spark Streaming中 WAL 工作原理:
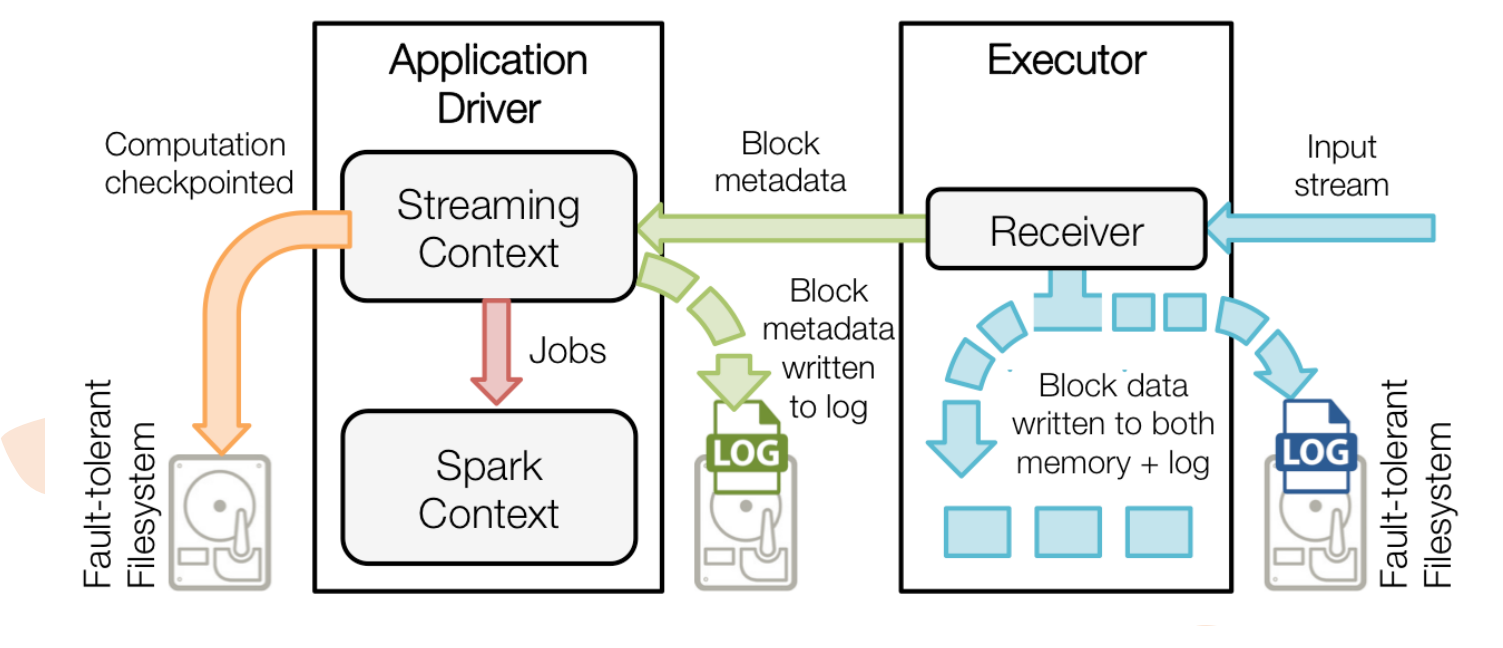
(蓝色的线是数据)input stream进来的时候是连续的,receiver接收数据,然后切分成block,左边的写到了自己的内存空间,右边的写到了log(WAL)里面,(绿色的线是元数据信息,不是真正的数据)StreamingContext把数据对接过来(原信息包含了内存中block的id号,日志中文件里block偏移量,偏移信息等),右边绿色也是把元数据信息写入log,红色表明StreamingContext转换成SparkContext
黄色的线:例如 wordcount
Streaming对10分钟一个的处理窗口 -> wordcount
0-10min ------>wordcount1
10-20min------>wordcount2
.........
单看wordcount1和wordcount2是没有关系的,但是假设我们的目的是统计一天的wordcount,如果这么看,那么就需要把时间窗口改为1天,那就完全可以用mapreduce和spark去做了,失去了Spark Streaming的意义。
所以Spark Streaming是带状态的流计算。
带状态:假设要做0-20min的wordcount,是把wordcount1的值直接拿过来使用的。(把前面的结果拿过来)
所以黄色线所连的log为wordcount1,wordcount2.....
实时流计算:主要就是为了低延时。
• 当一个Driver失败重启后,恢复流程:
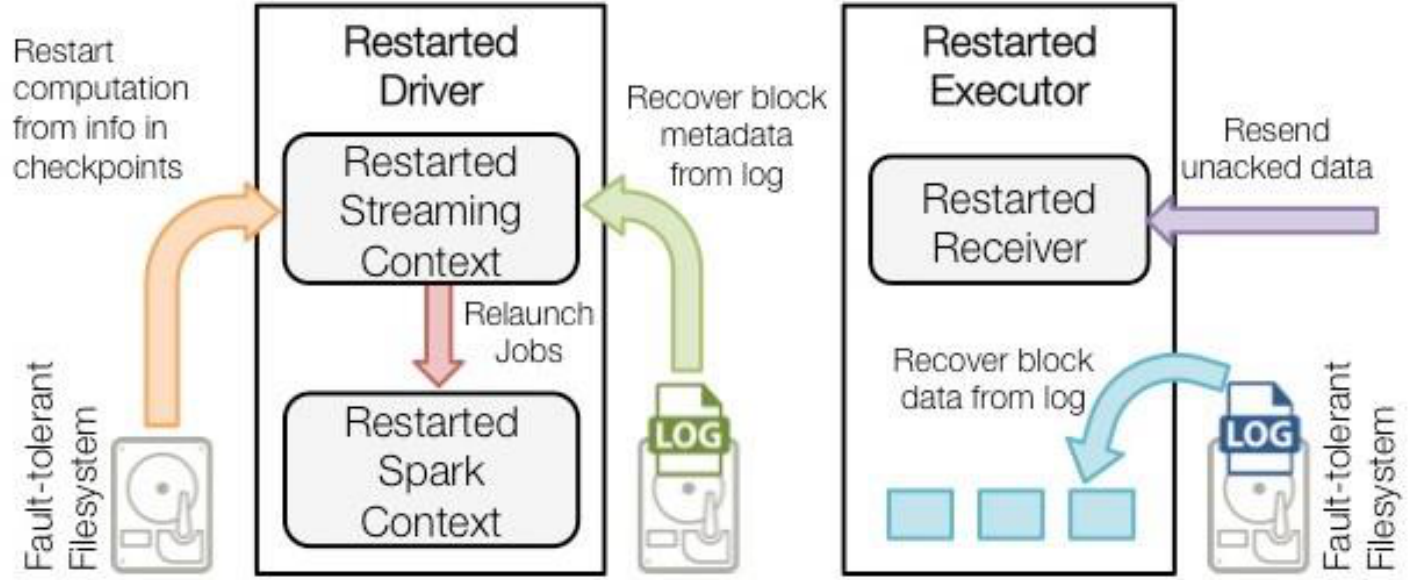
一旦driver失败重启了,首先黄色恢复计算,point信息用来重启driver的,构造上下文,重启receiver(因为receiver是由driver来启动的,driver挂了,没人管receiver了),然后receiver从外部的WAL读取进来,然后再重启所有的receiver,依赖绿色的元数据信息,没有计算完的任务,重新生成启动,正在数据从蓝色读取到内存中。紫色是外部组件做一些确认的操作(数据有没有传输过来)
Spark Streaming简介及原理的更多相关文章
- 49、Spark Streaming基本工作原理
一.大数据实时计算介绍 1.概述 Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架.它的底层,其实,也是基于我们之前讲解的Spark Core的. 基本 ...
- Spark Streaming fileStream实现原理
fileStream是Spark Streaming Basic Source的一种,用于“近实时”地分析HDFS(或者与HDFS API兼容的文件系统)指定目录(假设:dataDirectory)中 ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- Spark Streaming简介
离线计算和实时计算对比 1)数据来源 离线:HDFS历史数据 数据量比较大 实时:消息队列(Kafka),实时新增/修改记录过来的某一笔数据 2)处理过程 离线:MapReduce: map+redu ...
- 63、Spark Streaming:架构原理深度剖析
一.架构原理深度剖析 StreamingContext初始化时,会创建一些内部的关键组件,DStreamGraph,ReceiverTracker,JobGenerator,JobScheduler, ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- .Spark Streaming(上)--实时流计算Spark Streaming原理介
Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍 http://www.cnblogs.com/shishanyuan/p/474 ...
- 实时流计算Spark Streaming原理介绍
1.Spark Streaming简介 1.1 概述 Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的.具备容错机制的实时流数据的处理.支持从多种数据源获取数据,包 ...
- Spark Streaming初步使用以及工作原理详解
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着电商企业的发展,hadoop只适用于一些离线数据的处理,无法应对一些实时数据的处理分析,我们需要一些实时计算框架来分析数据.因此出现了很多 ...
随机推荐
- pip更新及Requirement already up-to-date解决方法
pip更新及Requirement already up-to-date解决方法 文:铁乐与猫 2018-9-11 更新命令 将pip更新到最新版本 python -m pip install --u ...
- Python基础知识:模块
目录 JSON模块&pickle模块 requests模块 time模块 datetime模块 logging模块 os模块 sys模块 hashlib模块 re模块.正则表达式 config ...
- tcpdump抓包具体分析
Tcpdump抓包分析过程 一.TCP连接建立(三次握手) 过程 客户端A,服务器B,初始序号seq,确认号ack 初始状态:B处于监听状态,A处于打开状态 A -> B : seq = x ...
- 函数重载(overload)
重载的定义及特点 在同一个类中,允许存在一个以上的同名函数, 只要他们的参数个数或者参数类型不同(不仅指两个重载方法的参数类型不同,还指相同参数拥有不同的参数类型顺序)就构成重载. 重载只和参数列表有 ...
- iOS时间显示今天昨天
一.前言 今天无意间想起写这个功能,仔细考虑了一下,其实很简单,整体思路如下: 先获取你所要转换的时间的年月日,然后再获取今天和昨天的年月日,然后对比,进而返回不同的字符串. 二.实现步骤 首先,我们 ...
- java 代码说明制作讲解
命令格式及介绍 javadoc -d 文档存放目录 -author -version 源文件名.java 这条命令编译一个名为"源文件名.java"的 java 源文件,并将生成的 ...
- Java日志框架Slf4j+Log4j入门
一.日志系统介绍 slf4j,即简单日志门面(Simple Logging Facade for Java),不是具体的日志解决方案,它只服务于各种各样的日志系统.简答的讲就是slf4j是一系列的日志 ...
- Excel中IF函数的嵌套用法(多条件)
Excel中IF函数的嵌套用法(多条件) Excel中IF函数的嵌套用法(多条件) 函数格式:if(logical_test,value_if_true,value_if_false).其中: ...
- go标准库的学习-crypto/sha1
参考:https://studygolang.com/pkgdoc 导入方式: import "crypto/sha1" sha1包实现了SHA1哈希算法,参见RFC 3174. ...
- metamascara学习导论
研究了一段时间的metamascara终于有了一点起色,因为前段时间有一个小伙伴问了我一个问题,就是能不能将metamask嵌入到自己设计的网站中,在自己要进行交易的时候也会弹出一个页面来让用户确认这 ...