selenium对51job进行职位爬虫
selenium 爬虫流程如下:
1、对某职位进行爬虫 ---如:自动化测试
2、用到IDE为 pycharm
3、爬虫职位导入到MongoDB数据库中
4、在线安装 pip install pymongo
5、本次使用到脚本化无头浏览器 --- PhantomJS MongoDB安装说明连接:https://www.twblogs.net/a/5c27009bbd9eee16b3dba7bc/zh-cn
PhantomJS 下载地址和API连接:http://phantomjs.org/download.html , http://phantomjs.org/api/下载后添加path中 --- CMD窗口输入 PhantomJS 按回车 --- 出现 phantomjs> 说明配置成功 如下为 51job.py 截图:
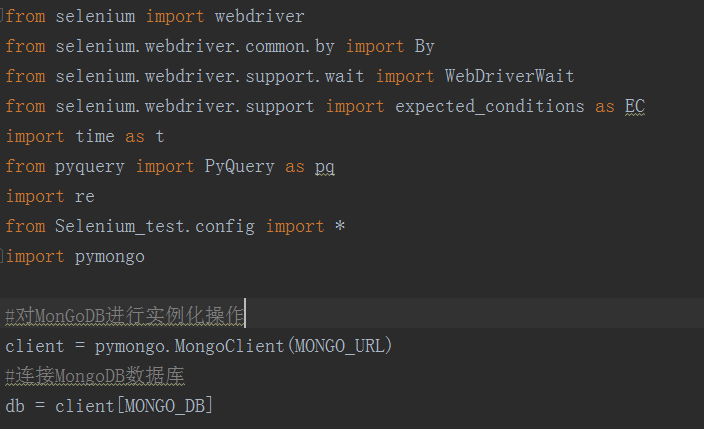

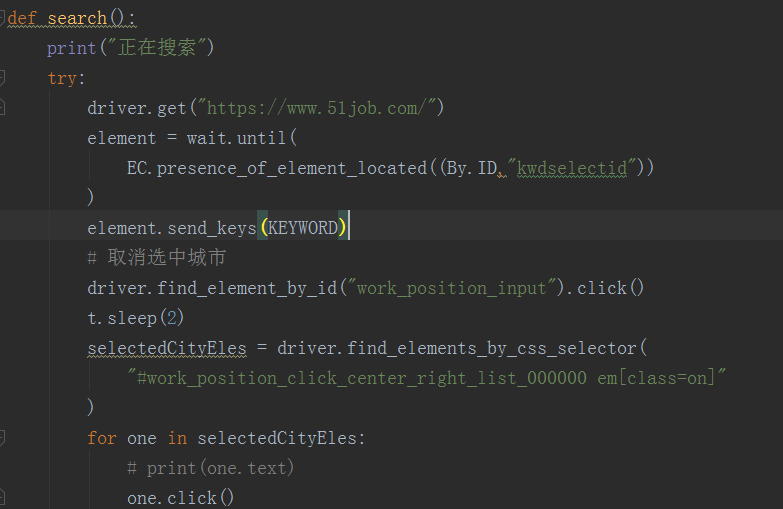
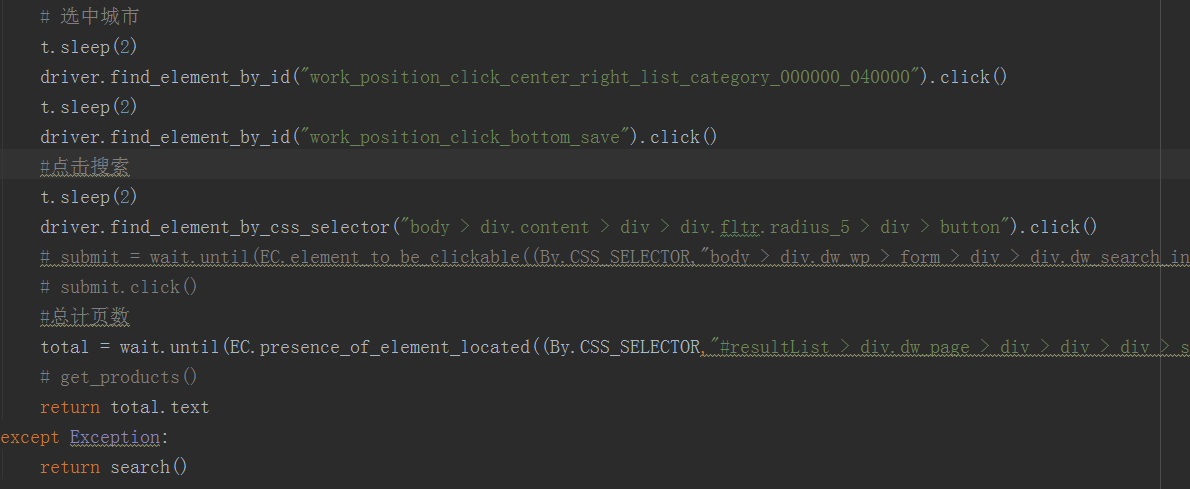
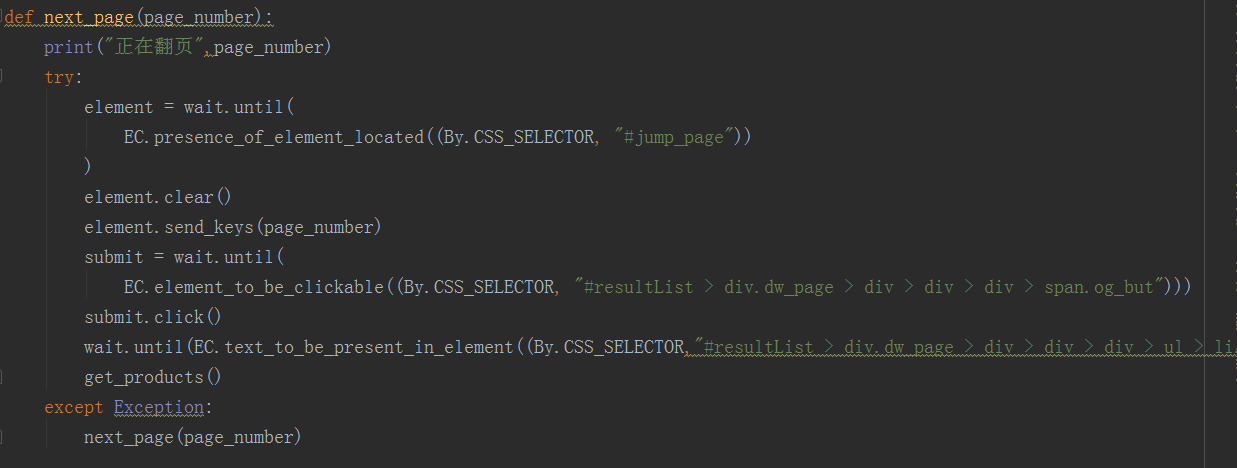
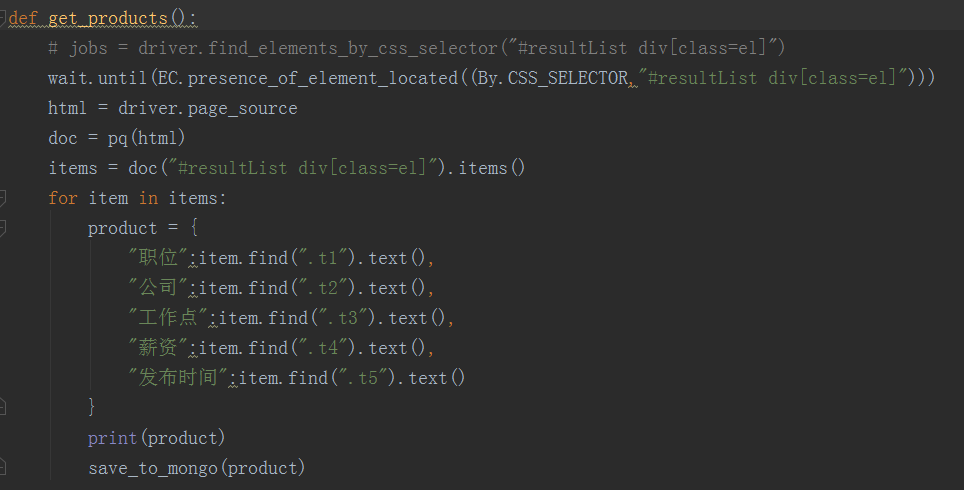
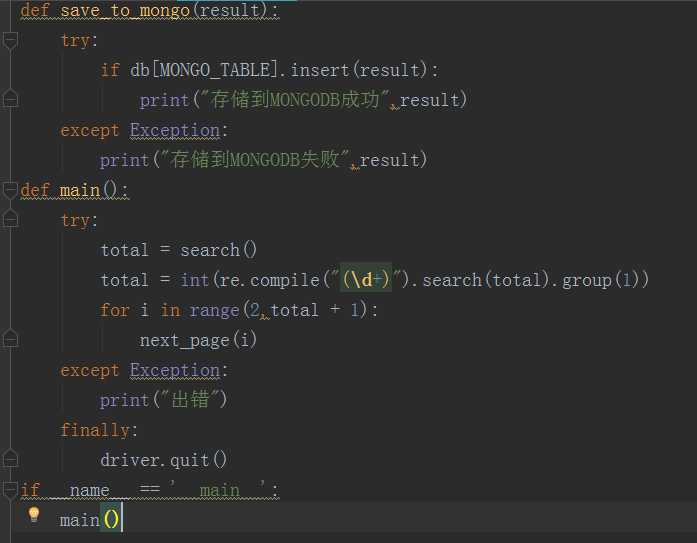
config配置文件如下:

pycharm 运行结果:

MongoDB 数据库截图:
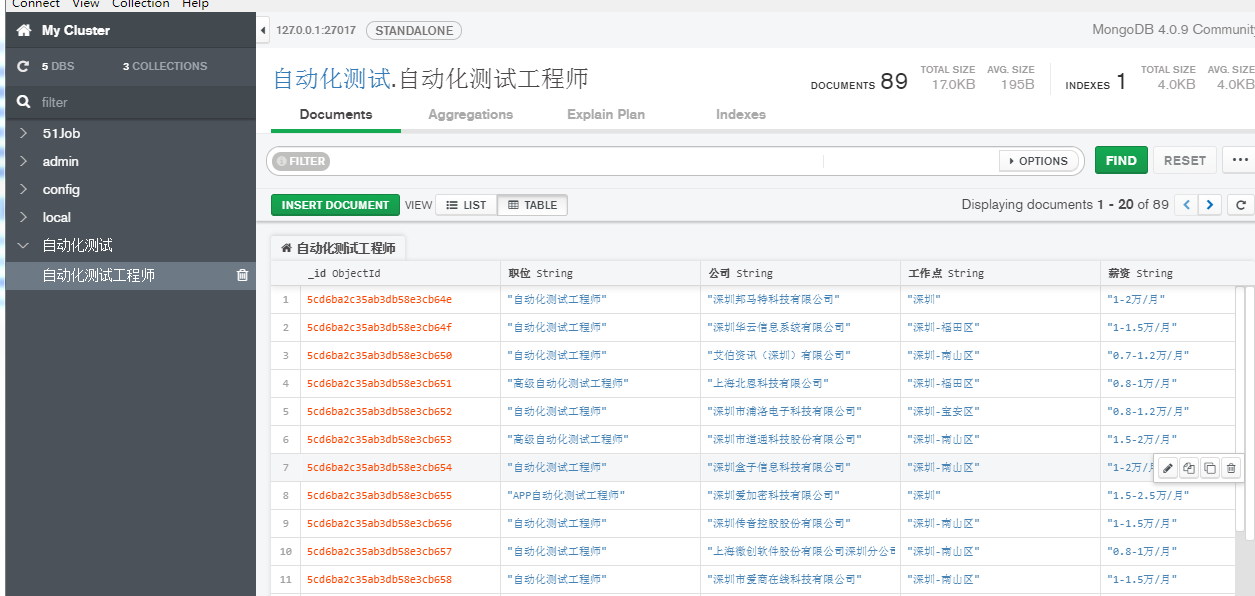
如下为config 配置文件:
MONGO_URL = "mongodb://127.0.0.1:27017/" MONGO_DB = "自动化测试"
MONGO_TABLE = "自动化测试工程师" KEYWORD = "自动化测试工程师" SERVICE_ARGS = ["--load-images=false","--disk-cache=true"] #忽略缓存和图片加载
爬虫源码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time as t
from pyquery import PyQuery as pq
import re
#config -- 上面已展示
from Selenium_test.config import *
import pymongo #对MonGoDB进行实例化操作
client = pymongo.MongoClient(MONGO_URL)
#连接MongoDB数据库
db = client[MONGO_DB] #浏览器实例化
driver = webdriver.PhantomJS(service_args=SERVICE_ARGS)
# driver = webdriver.Chrome()
driver.set_window_size(1400,900)
driver.maximize_window()
driver.implicitly_wait(10)
#显示等待
wait = WebDriverWait(driver,10) def search():
print("正在搜索")
try:
driver.get("https://www.51job.com/")
element = wait.until(
EC.presence_of_element_located((By.ID,"kwdselectid"))
)
element.send_keys(KEYWORD)
# 取消选中城市
driver.find_element_by_id("work_position_input").click()
t.sleep(2)
selectedCityEles = driver.find_elements_by_css_selector(
"#work_position_click_center_right_list_000000 em[class=on]"
)
for one in selectedCityEles:
# print(one.text)
one.click()
# 选中城市
t.sleep(2)
driver.find_element_by_id("work_position_click_center_right_list_category_000000_040000").click()
t.sleep(2)
driver.find_element_by_id("work_position_click_bottom_save").click()
#点击搜索
t.sleep(2)
driver.find_element_by_css_selector("body > div.content > div > div.fltr.radius_5 > div > button").click()
# submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,"body > div.dw_wp > form > div > div.dw_search_in > button")))
# submit.click()
#总计页数
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#resultList > div.dw_page > div > div > div > span:nth-child(2)")))
# get_products()
return total.text
except Exception:
return search() def next_page(page_number):
print("正在翻页",page_number)
try:
element = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#jump_page"))
)
element.clear()
element.send_keys(page_number)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#resultList > div.dw_page > div > div > div > span.og_but")))
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#resultList > div.dw_page > div > div > div > ul > li.on"),str(page_number)))
get_products()
except Exception:
next_page(page_number) def get_products():
# jobs = driver.find_elements_by_css_selector("#resultList div[class=el]")
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#resultList div[class=el]")))
html = driver.page_source
doc = pq(html)
items = doc("#resultList div[class=el]").items()
for item in items:
product = {
"职位":item.find(".t1").text(),
"公司":item.find(".t2").text(),
"工作点":item.find(".t3").text(),
"薪资":item.find(".t4").text(),
"发布时间":item.find(".t5").text()
}
print(product)
save_to_mongo(product) def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print("存储到MONGODB成功",result)
except Exception:
print("存储到MONGODB失败",result) def main():
try:
total = search()
total = int(re.compile("(\d+)").search(total).group(1))
for i in range(2,total + 1):
next_page(i)
except Exception:
print("出错")
finally:
driver.quit() if __name__ == '__main__':
main()
selenium对51job进行职位爬虫的更多相关文章
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
- 基于selenium爬取拉勾网职位信息
1.selenium Selenium 本是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.而这一特性为爬虫开发提供了一个选择及方向,由于其本身依赖 ...
- Selenium结合BeautifulSoup4编写简单爬虫
在学会了抓包,接口请求(如requests库)和Selenium的一些操作方法后,基本上就可以编写爬虫,爬取绝大多数网站的内容. 在爬虫领域,Selenium永远是最后一道防线.从本质上来说,访问网页 ...
- selenium+chromdriver 动态网页的爬虫
# 获取加载更多的数据有 2 种方法# 第一种就是直接找数据接口, 点击'加载更多' 在Network看下, 直接找到数据接口 # 第二种方法就是使用selenium+chromdriver # se ...
- python+selenium实现网页自动化与爬虫技术
举例某购物网站,通过selenium与python,实现主页上商品的搜索,并将信息爬虫保存至本地excel表内. 一.python环境与selenium环境安装 python在官网下载并安装并且设置环 ...
- selenium+BeautifulSoup实现强大的爬虫功能
sublime下运行 1 下载并安装必要的插件 BeautifulSoup selenium phantomjs 采用方式可以下载后安装,本文采用pip pip install BeautifulSo ...
- [python爬虫] Selenium常见元素定位方法和操作的学习介绍
这篇文章主要Selenium+Python自动测试或爬虫中的常见定位方法.鼠标操作.键盘操作介绍,希望该篇基础性文章对你有所帮助,如果有错误或不足之处,请海涵~同时CSDN总是屏蔽这篇文章,再加上最近 ...
- python爬虫积累(一)--------selenium+python+PhantomJS的使用
最近按公司要求,爬取相关网站时,发现没有找到js包的地址,我就采用selenium来爬取信息,相关实战链接:python爬虫实战(一)--------中国作物种质信息网 一.Selenium介绍 Se ...
- 使用Python + Selenium打造浏览器爬虫
Selenium 是一款强大的基于浏览器的开源自动化测试工具,最初由 Jason Huggins 于 2004 年在 ThoughtWorks 发起,它提供了一套简单易用的 API,模拟浏览器的各种操 ...
随机推荐
- 面向对象:继承(经典类&新式类继承原理、属性查找)、派生
继承: 继承是指类与类之间的关系,是一种“什么”是“什么”的关系. 继承的功能之一就是用来解决代码重用问题 继承是一种创建新类的方式,在Python中,新建的类可以继承一个或多个父类,父类又可以称为基 ...
- android开发里跳过的坑——调用已安装视频播放器在有些机器上无效
调用已安装视频播放器播放未修改之前的代码 private void startPlay(String fileName){ File file = new File(fileName); Intent ...
- DELL T110II Server如何通过RAID 级别迁移的方式在OMSA下实现磁盘阵列扩容?
目录: RAID 转移规则说明 操作步骤 本文介绍了 通过RAID 级别转换来实现扩容的方法注意:本文相关RAID的操作,仅供在测试环境里学习和理解戴尔PowerEdge服务器RAID控制卡的功能和使 ...
- mysql 经常使用命令整理总结
#改动字段类型 alter table `table_name` modify column ip varchar(50); #添加字段 alter table `table_name` add ip ...
- Storm计算结果是怎样存放的
Storm计算的结果存放在哪里? 刚開始接触Storm的时候.往往都会有这么一个疑问:"Storm处理后 的计算结果是保存在哪里呢?"是内存中还是在其他的地方? 官方给出的解释是: ...
- react 项目实战(二)创建 用户添加 页面 及 fetch请求 json-server db.json -w -p 8000
1.安装 路由 npm install -S react-router@3.x 2.新增页面 我们现在的应用只有一个Hello React的页面,现在需要添加一个用于添加用户的页面. 首先在/src目 ...
- C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 VC中进程与进程之间共享内存 .net环境下跨进程、高频率读写数据 使用C#开发Android应用之WebApp 分布式事务之消息补偿解决方案
C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing). ...
- Netty In Action中文版 - 第四章:Transports(传输)
本章内容 Transports(传输) NIO(non-blocking IO,New IO), OIO(Old IO,blocking IO), Local(本地), Embedded(嵌入式) U ...
- 1.Urllib2模块使用
网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地. Urllib2介绍: urllib2 是 Python2.7 自带的模块(不需要下载,导入即可使用) urllib2 官方文 ...
- iOS开发——常见BUG——window决定程序的状态栏管理问题
Xcode7升级之后遇到的问题 问题一: 老项目在Xcode6上运行没有任何问题,但在Xcode7上运行直接崩了! 经过一波分析: 发现是因为我顶部状态栏处添加了topWindow,用于处理Tab ...