AshMap如何让hash保持一致
学Java的都知道hashMap的底层是“链表散列”的数据结构也也可以说是hash表。在put的实话先根据key的hashcode重新计算hash值的,而我们又知道hash是一种算法。所以哈希码并不是完全唯一的。
查看哈希码百科:

哈希表可以说就是数组链表,底层还是数组但是这个数组每一项就是一个链表
一:为什么说hashmap的put方法是根据key进行hashcode计算的呢?
查看源码:

在查看hash方法,如下:

查看putVal方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node [] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode )p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
二:hashmap怎么解决key的hash值冲突问题的?

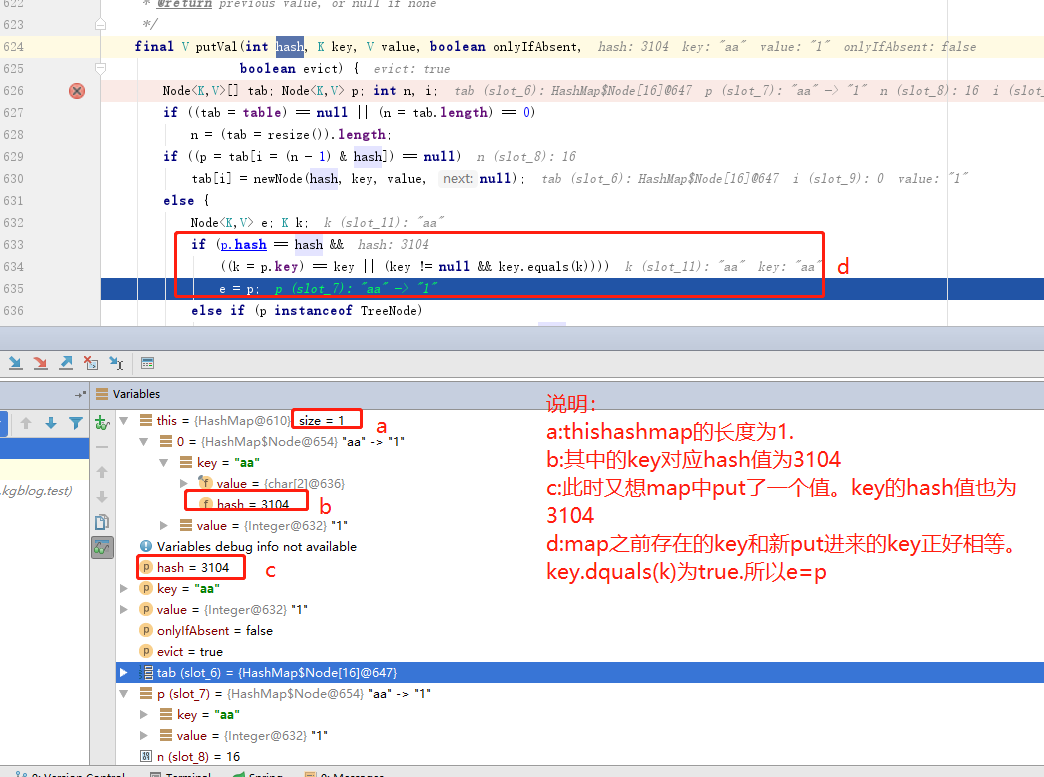
上图是源码截图,说明:
1:初始化map的大小。默认是16
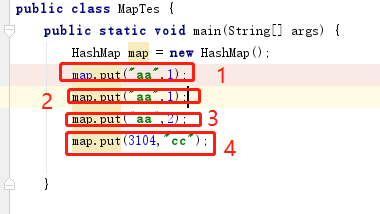
示例代码:HashMap map = new HashMap();
2:如果tab为空,就newNode一个放到链表中
示例代码:map.put("aa",1); 也就是图-1测试代码中的1
3:根据key算出的hash值如果存在,且key的值和map中已经存在的值equals了。所以就不处理。
如下图:
测试代码如图-1测试代码中的1和 2
4:如果p是TreeNode的子类进行putTreeValu
5:如果key的hash值和map中已经存在的key的hash相等且key不同的时候,如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
如图-1测试代码 1和4中key的hesh值都为3104
图-1测试代码
在来看下Node这个内部类:

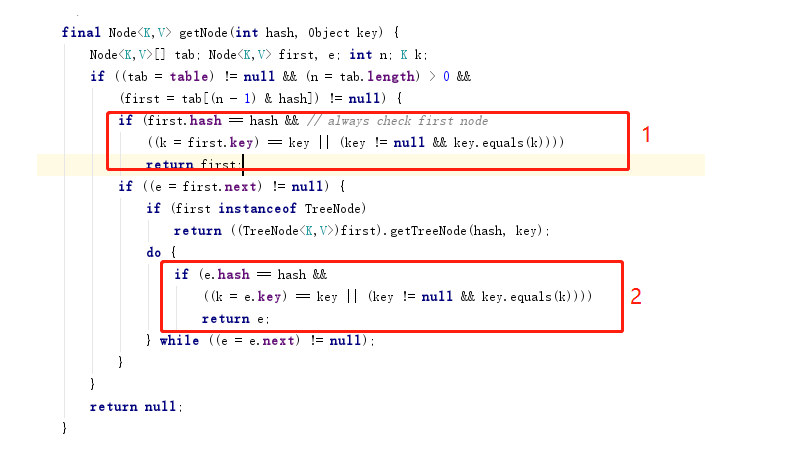
三:在来看看怎么get方法
说明:
1:如果链表中第一个值的hash值和需要获取的key的hash值相等的话,就直接取出。
2:如果链表first.next !=null就循环查找链表中的key,知道查询到key.equals(k) 取出对应的值。
查看源码或许感觉不懂,那么画图来说明:

总结:
数据结构:哈希表可以说就是数组链表,底层还是数组但是这个数组每一项就是一个链表。
map的put方法:
1:new hashMap的时候初始化默认大小为16
2:当map.put("aa",1)的时候判断map没有值,就把aa算的hash值放到0X004的位置
3:当再次执行map.put("aa",1)的是计算aa的hash值为3104.此时在OX004的位置已经有数据了。进行判断存在的key和新put的key是否相同。相同不处理,值覆盖
4:执行map.put("aa",2)的时候key和已经存在的key相同就直接覆盖value了
5:执行map.put(3104,"cc")的时候,key的hash值也为3104.此时数组中OX004已经存在数据,判断key是否相同。发现3104和aa不相同【注:此时就发生了hash冲突】,那么就aa这个链表前面追加3104
6:执行map.put("bb","cc")。假设bb计算出的hash值是3105就存放在了OX005上。
其他依次类推
map的get方法:
当执行map.get("bb")的时候先计算出bb的hash值为3105在对应的位置(也就是0X005)取出第一个判断值是不是bb如果是就直接取出value.
当执行map.get("aa")的时候先计算出aa的hash值为3104,去对应的位置取出判断值(3104)不等于(aa)且还有next。就循环取出进行比较。
AshMap如何让hash保持一致的更多相关文章
- 哈希与位图(Hash and BitMap)
Hash:哈希机制 BitMap:位图机制 目的:都是为了保证检索方便而设置的数据结构 对于大数据进行排序,由于内存限制,不可能在内存中进行,所以采取BitMap机制 为了在大数据中快速检索以及操作数 ...
- 复杂的 Hash 函数组合有意义吗?
很久以前看到一篇文章,讲某个大网站储存用户口令时,会经过十分复杂的处理.怎么个复杂记不得了,大概就是先 Hash,结果加上一些特殊字符再 Hash,结果再加上些字符.再倒序.再怎么怎么的.再 Hash ...
- 对抗密码破解 —— Web 前端慢 Hash
(更新:https://www.cnblogs.com/index-html/p/frontend_kdf.html ) 0x00 前言 天下武功,唯快不破.但在密码学中则不同.算法越快,越容易破. ...
- 散列表(hash table)——算法导论(13)
1. 引言 许多应用都需要动态集合结构,它至少需要支持Insert,search和delete字典操作.散列表(hash table)是实现字典操作的一种有效的数据结构. 2. 直接寻址表 在介绍散列 ...
- hash表长度优化证明
hash表冲突的解决方法一般有两个方向: 一个是倾向于空间换时间,使用向量加链表可以最大程度的在节省空间的前提下解决冲突. 另外一个倾向于时间换空间,下面是关于这种思路的一种合适表长度的证明过程: 这 ...
- SQL Server-聚焦查询计划Stream Aggregate VS Hash Match Aggregate(二十)
前言 之前系列中在查询计划中一直出现Stream Aggregate,当时也只是做了基本了解,对于查询计划中出现的操作,我们都需要去详细研究下,只有这样才能对查询计划执行的每一步操作都了如指掌,所以才 ...
- C# salt+hash 加密
一.先明确几个基本概念 1.伪随机数:pseudo-random number generators ,简称为:PRNGs,是计算机利用一定的算法来产生的.伪随机数并不是假随机 数,这里的" ...
- SQL 提示介绍 hash/merge/concat union
查询提示一直是个很有争议的东西,因为他影响了sql server 自己选择执行计划.很多人在问是否应该使用查询提示的时候一般会被告知慎用或不要使用...但是个人认为善用提示在不修改语句的条件下,是常用 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
随机推荐
- BZOJ 5170: Fable
离散化+树状数组 求当前位之前是否有k位比它大 这样的话它就需要前移k位 剩下的按照原来的顺序依次填入 其实我觉得sort一下就可以做出来了 太久没写树状数组了 所以写了一下树状数组 #include ...
- 移动端调试 — 安卓机+chrome
移动端开发时,我们常使用chrome自带的模拟器,模拟各种手机设备. 但模拟毕竟是模拟,当开发完毕,使用真机访问页面出现问题时如何调试呢? 下面介绍一种针对Android机的调试方法 1. 在pc和a ...
- 测开之路八十二:匿名函数:lambda表达式
# 匿名函数:lambda表达式# lambda 参数: 逻辑f = lambda name: print(name)f('tom') f2 = lambda x, y: x + yprint(f2( ...
- java注解编程@since 1.8
一.基本元注解: @Retention: 说明这个注解的生命周期 RetentionPolicy.SOURCE -> 保留在原码阶段,编译时忽略 RetentionPolicy.CLASS -& ...
- OAUTH2.0协议-菜鸟级
OAUTH2.0入门必看 一.摘要 OAUTH协议为用户资源的授权提供了一个安全的.开放而又简易的标准.与以往的授权方式不同之处是OAUTH的授权不会使第三方触及到用户的帐号信息(如用户名与密码),即 ...
- Spring学习(四)--面向切面的Spring
一.Spring--面向切面 在软件开发中,散布于应用中多处的功能被称为横切关注点(cross- cutting concern).通常来讲,这些横切关注点从概念上是与应用的业 务逻辑相分离的(但是往 ...
- Junit测试错误:### Error building SqlSession
错误代码: org.apache.ibatis.exceptions.PersistenceException: ### Error building SqlSession.### The error ...
- luoguP3384 [模板]树链剖分
luogu P3384 [模板]树链剖分 题目 #include<iostream> #include<cstdlib> #include<cstdio> #inc ...
- 重命名sql数据库
use master select spid from master.dbo.sysprocesses where dbid=db_id('TW') 查看连接,杀死线程 use master kill ...
- redhat6.5单用户重置root密码
(1),按 “e” 键进入该界面,继续按 “e” 键进入下一个界面. (2).上下键选中第二个kernel选项,继续按 “e” 键进行编辑. (3).在新的界面里面加一个空格,再输入“1”:或者输入“ ...