Practical Lessons from Predicting Clicks on Ads at Facebook (2014)论文阅读
文章链接: https://quinonero.net/Publications/predicting-clicks-facebook.pdf
- abstract
Facebook日活跃度7.5亿,活跃广告主1百万
特征工程最重要:user和ad的历史信息胜过其他特征
轻微提升模型效果:数据新鲜度、学习率、数据采样
增加一个重要特征和选择正确的模型更关键
- introduction
按点击收费广告效果依赖于点击率预估。相比于搜索广告使用搜索query,Facebook更依赖人口和兴趣特征。
本文发现决策树和逻辑回归的混合模型比其他方法好3%。
线性分类两个要素:特征变换、数据新鲜度
在线学习
延时、可扩展性
- experimental setup
划分训练数据和测试数据模拟在线数据流。
评估指标使用预测精度:归一化熵(Normalized Entropy,NE)和校正度(calibration)
NE = 预测log loss/平均历史ctr;越低效果越好。使用背景ctr(即平均历史ctr)是为了评估相对历史ctr更不敏感。
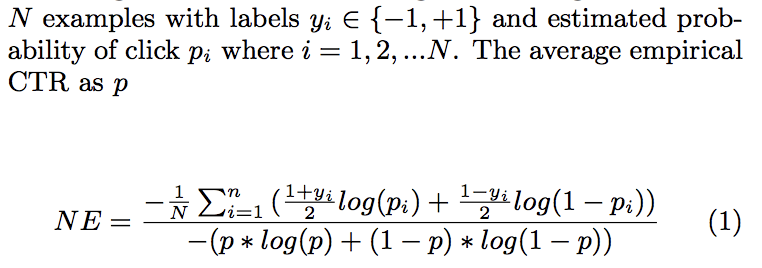
calibration = 平均估计ctr/历史ctr = 期望点击数/实际点击数。
不用AUC是因为它度量排序效果且没有校正度概念。NE反映了预测精度且隐藏反映校正度。
- prediction model structure
使用决策树做特征变换
更新的数据得到更好效果
SGD:

Bayesian online learning scheme for probit regression (BOPR)的似然和先验:
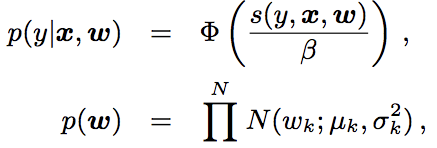
更新算法:
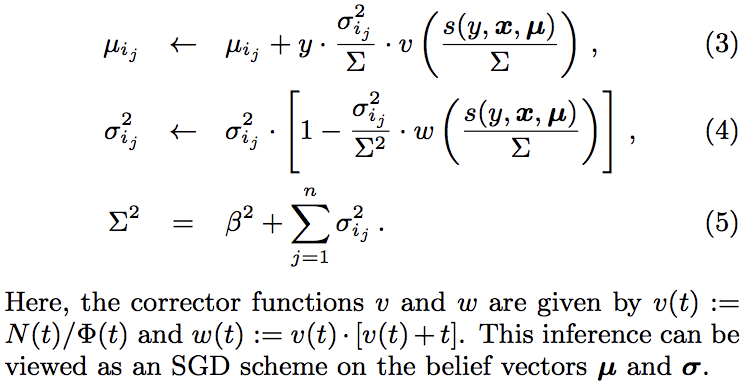
—— decision tree feature transforms
连续特征:离散化分桶
类别特征:笛卡尔积
每个GBDT输出作为编码某种规则的特征,再用线性分类器:

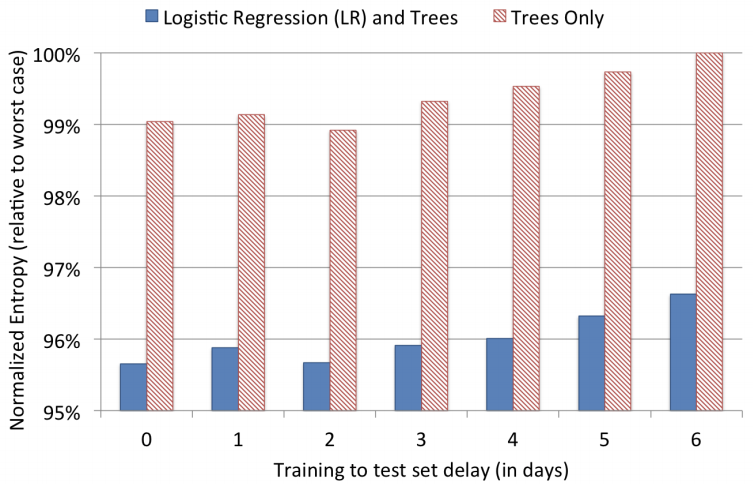
有GBDT特征变换相对于没有,NE下降3.4%。一般的特征工程只能下降千分之二左右。

使用GBDT特征变换先出减少特征数,代价仅仅减少很少的效果。
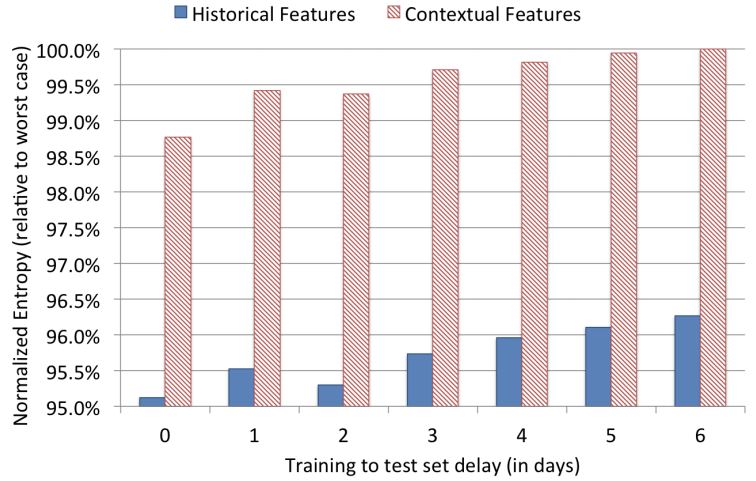
—— data freshness
周级别更新改为天级别更新,NE下降1%。因此需要天级别更新。
线性分类器部分可以实时更新
—— online linear classifer

#1,#2,#3 每个特征有独立的学习率
#4,#5 所有特征共享一个学习率
效果排名:#1,#2=#5,#4,#3。
#1是LR,独立学习率。

#5全局统一学习率的问题主要因为不同特征有取值的样本的个数差距大。样本少的特征权重衰减过快。
#3虽然缓解此问题但是仍然差,因为学习率衰减太快导致过早结束训练。
LR和BOPR效果接近,但是LR模型比BOPR小一半。不过BOPR有Bayes形式,更适合explore/exploit方法。
—— online data joiner

结合requestID拼接点击和展示,HashQueue存impression,HashMap存click。展示需要等待点击事件,等待时间窗需要仔细调,过小点击拼接不上、过大需要更多存储且时效性差。
有点击无法拼接意味着历史ctr低于真实值,因此需要校正。
需要做保护机制,比如click数据流卡住,trainer需要断开与joiner的连接。
- containing memory and latency
—— number of boosting trees
#leaves per tree <= 12
500 trees取得大部分提升
而且为了计算和存储效率,数的棵数不要太多。

—— boosting feature importance
一般少量特征贡献大部分提升。top10特征贡献一半特征重要度,last300贡献<1%重要度。
几个特征举例
contextual: local time of day, day of week, device, current page
historical: cumulative number of clicks on an ad, avg ctr of the ad in last week, avg ctr of the user
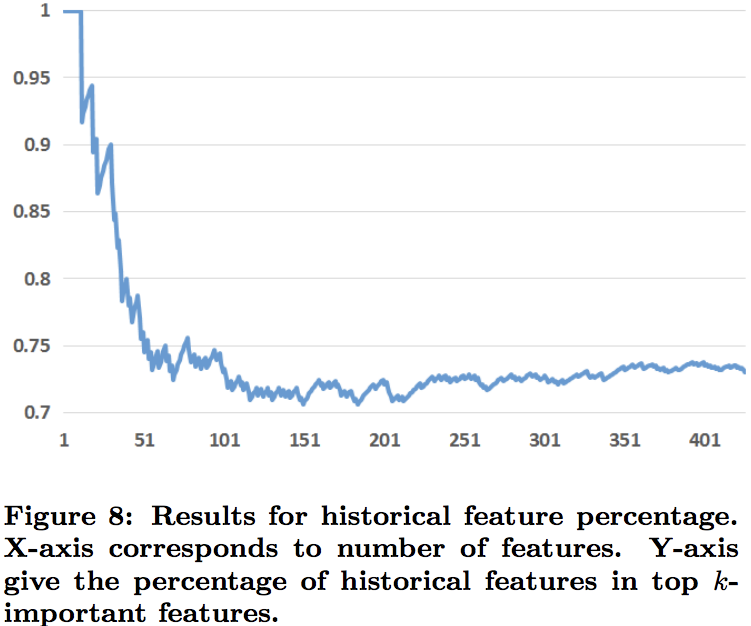
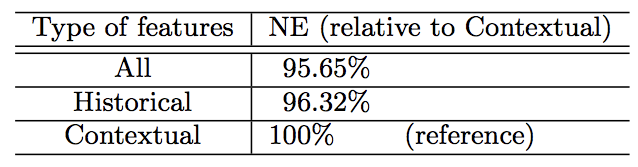
—— historical features
historical比contextual更有用:top10重要度都是historical特征。
contextual特征更适合处理冷启动问题。
contextual特征更依赖数据新鲜度,当然部分因为historical特征已经包含长期累积的用户行为
- coping with massive training data
亿级别以上样本量
—— uniform subsampling
更多数据效果更好。不过10%数据只有1%效果损失。
—— negative down sampling
类别不均衡需要负例下采样,目前最佳采样率是0.025
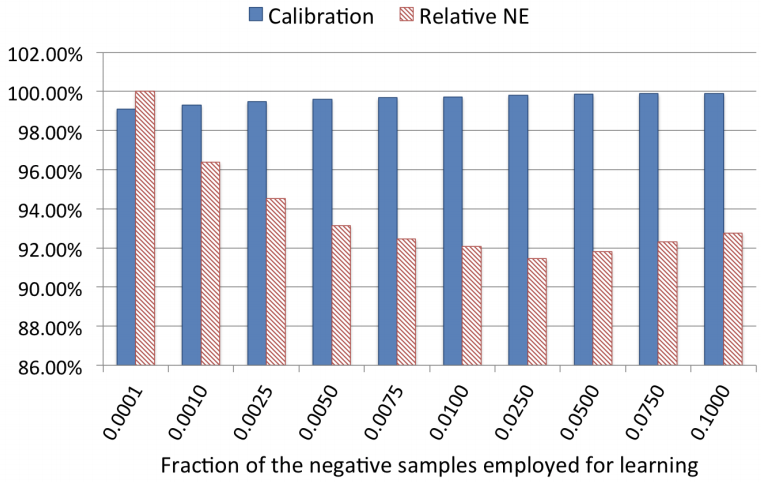
—— model re-calibration
因为负采样所以需要ctr校正。

Practical Lessons from Predicting Clicks on Ads at Facebook (2014)论文阅读的更多相关文章
- [笔记]Practical Lessons from Predicting Clicks on Ads at Facebook
ABSTRACT 这篇paper中作者结合GBDT和LR,取得了很好的效果,比单个模型的效果高出3%.随后作者研究了对整体预测系统产生影响的几个因素,发现Feature+Model的贡献程度最大,而其 ...
- Practical Lessons from Predicting Clicks on Ads at Facebook
ABSTRACT 这篇paper中作者结合GBDT和LR,取得了很好的效果,比单个模型的效果高出3%.随后作者研究了对整体预测系统产生影响的几个因素,发现Feature(能挖掘出用户和广告的历史信息) ...
- 【论文阅读】ICLR 2022: Scene Transformer: A unified architecture for predicting future trajectories of multiple agents
ICLR 2022: Scene Transformer: A unified architecture for predicting future trajectories of multiple ...
- 论文阅读 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks
6 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks link:https://arxiv.org/ab ...
- 【论文阅读】A practical algorithm for distributed clustering and outlier detection
文章提出了一种分布式聚类的算法,这是第一个有理论保障的考虑离群点的分布式聚类算法(文章里自己说的).与之前的算法对比有以下四个优点: 1.耗时短O(max{k,logn}*n), 2.传递信息规模小: ...
- 利用GBDT模型构造新特征具体方法
利用GBDT模型构造新特征具体方法 数据挖掘入门与实战 公众号: datadw 实际问题中,可直接用于机器学**模型的特征往往并不多.能否从"混乱"的原始log中挖掘到有用的 ...
- GBDT原理及利用GBDT构造新的特征-Python实现
1. 背景 1.1 Gradient Boosting Gradient Boosting是一种Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向.损失函数是 ...
- 广告点击率 CTR预估中GBDT与LR融合方案
http://www.cbdio.com/BigData/2015-08/27/content_3750170.htm 1.背景 CTR预估,广告点击率(Click-Through Rate Pred ...
- ML学习分享系列(2)_计算广告小窥[中]
原作:面包包包包包包 改动:寒小阳 && 龙心尘 时间:2016年2月 出处:http://blog.csdn.net/Breada/article/details/50697030 ...
随机推荐
- windows修复失效图标
taskkill /im explorer.exe /fcd /d %userprofile%\appdata\localdel iconcache.db /astart explorer.exeex ...
- django 模板里面for循环和if常用的方法
django 模板里面for循环常用的方法 {% for %} 允许我们在一个序列上迭代.与Python的for 语句的情形类似,循环语法是 for X in Y ,Y是要迭代的序列而X是在每一个特定 ...
- ubuntu install themes && use it
one step: I am going to show you the installation of a theme with Numix theme and Unity Tweak Tool. ...
- SecureCRT配置华为S5700交换机
我准备从交换机中监控某台设备的流量,所以要配置交换机的某个口作为镜像口,用来下载另外一个指定端口的流量. 第一步:华为5700交换机 简而言之网口部分除了最后四个都是用来连接下级网络设备的,最后四个端 ...
- 【Web】jquery合并单元格
合并单元格的情况,在开发中还是比较多见的,以下仅介绍合并行的情况. 原来的table效果 效果如下: 代码如下: <!DOCTYPE html> <html xmlns=" ...
- React 克隆组件 -- React.cloneElement(可以用来修改子组件属性值,复制子组件,添加子组件)
项目要求实现按钮级权限,简单来说就是需要通过后台数据绑定来控制前端页面哪些操作按钮需要渲染,哪些操作按钮不需要渲染, 大体的方案是: 在原有的按钮标签外再套一层按钮权限控制标签,然后每个具体的按钮对照 ...
- python基础知识(保留字和标识符、变量、常量、基本数据类型)
保留字 保留字是python语言中已经被赋予特定意义的一些单词,开发程序时,不可以作为变量.函数.类.模块和其他对象的名称来使用例如:import 关键字输入后会变色 通过代码进行查看 import ...
- PJzhang:关闭wps小广告和快速关闭445端口
猫宁!!! kali linux上安装的wps,没有广告,而且轻巧简洁. 如果你在windows上安装wps,除了ppt.word.excel,还会有一个h5的应用,当然,最令人烦扰的当 ...
- Autofac依赖注入容器
依赖注入容器-- Autofac https://github.com/danielpalme/IocPerformance Unity 更新频率高,微软的项目Grace 综合性能更高 目录: 一.简 ...
- Windows编程中各种操作文件的方法
windows编程中文件操作有以下几种常见方法:1.C语言中文件操作.2.C++语言中的文件操作.3.Win32 API函数文件操作.4.MFC CFile类文件操作.5.MFC CFileDialo ...