小记---------Hadoop读、写文件步骤,HDFS架构理解
- namespaceID:是文件系统的唯一标识符,在文件系统首次格式化之后生成的
- cTime:表示NameNode存储时间的创建时间,NameNode更新之后,此处的值 为更新时间戳。
- storageType:存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE)
- clusterID:是系统生成或手动指定的集群ID(集群所有节点都相同)
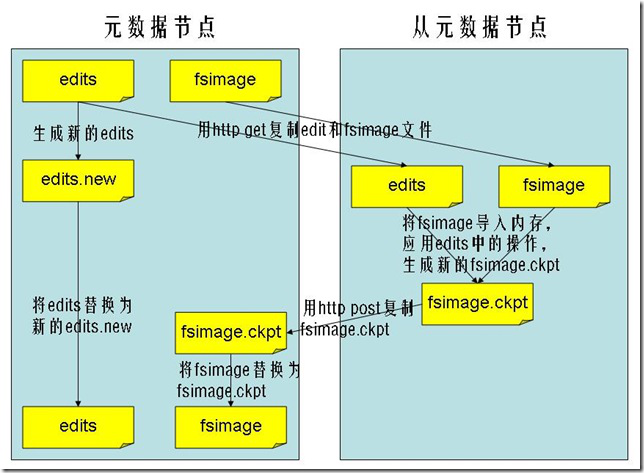
- Secondary NameNode请求NameNode进行edit log的滚动(即创建一个新的edit log)将新的编辑操作记录到新生成的edit log文件;
- 通过http get方式,读取nameNode上的fsimage和edit文件,到Secondary NameNode上
- 读取fsimage到内存中,即加载fsimage到内存,然后执行edits中所有操作,并生成一个新的fsimage文件,即这个检查点被创建
- 通过http post方式,将新的fsimage文件传送到namenode
- Namenode使用新的fsimage文件替换原来的fsimage文件,让1,创建的edits替代原来的edits文件,并且更新fsimage文件的检查点时间,整个处理过程完成。
- Secondary nameNode 的处理,是将fsimage和的its文件周期合并,不会造成NameNode重启时造成长时间不可访问的情况。

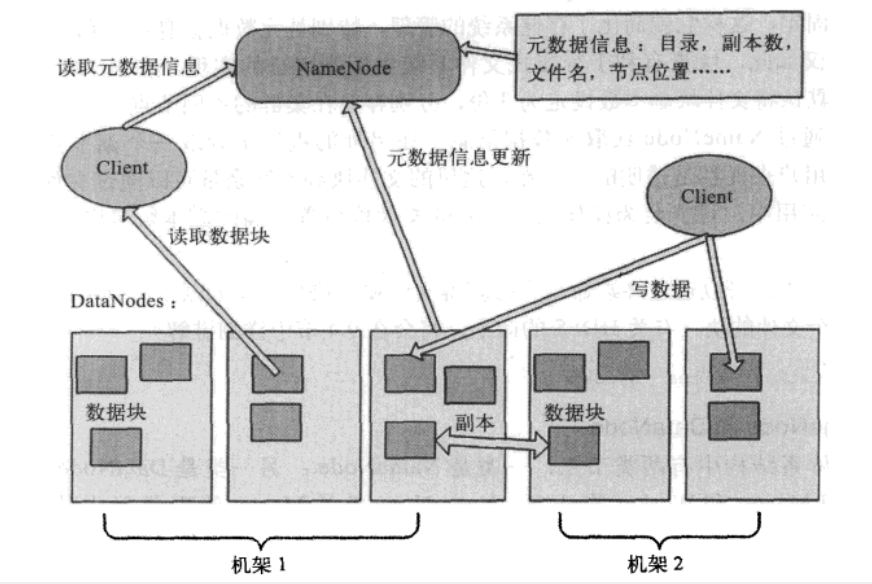
- client端通过DistributedFileSystem对象的open函数调用Namenode请求文件块所在的位置(三个副本位置都会获取到),然后返回给client端。
- client端在FSDataInputSteam调用read函数,然后连接文件第一个块最近的DataNode,第一个读取完毕后,再查找存储下一个块所在最近的DataNode,直到整个文件块读取完毕后,返回给client端,并关闭读流close函数
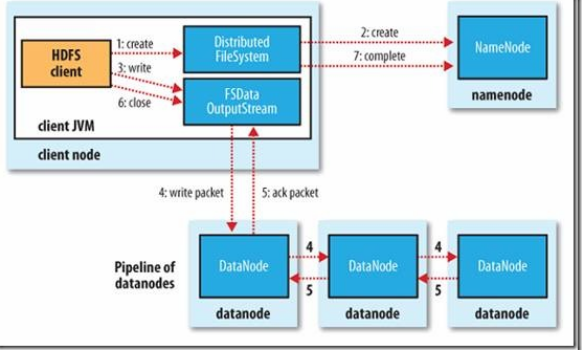
- client端通过调用DistributedFileSystem对象中的create()函数在NameNode的文件系统命名空间中创建一个新文件。
- Namenode会通过多种验证保证新的文件不存在文件系统中,并且确保请求client端拥有创建文件的权限。当所有验证通过时,NameNode会创建一个新文件的记录,如果创建失败则抛处IOException异常;如果成功,则DistributedFileSystem返回一个FSDataOutputStream给client端用来写入数据。其中FSDataOutputStream包含一个数据流对象DFSOutputStream,client端将使用它来处理和DataNode即NameNode之间的通信。
- 当client端写入数据时,DFSOutputStream会将文件分割成包,然后放入一个内部队列,我们成为“数据队列”
- DataStream会将这些小的文件包放入数据流中,DataStreamer的作用是请求NameNode为新的文件包分配合适的DataNode存放副本,返回的DataNode列表形成一个“管道”,
- HDFS首先会关闭管道。
- 然后在确认通知队列中的文件包都会被添加到数据队列的前端,当前存放于正常工作的DataNode之上的文件块会被赋予一个新的身份,并且和NameNode进行关联。
- 失败的DataNode过段时间从故障中恢复过来,之前存放进去的部分数据块会被删除,然后管道把失败的DataNode删除
- 在步骤2中的文件块继续被写到管道中的另外两个DataNode中
- 最后NameNode会注意到现在的文件块副本数没有达到配置属性要求,会在另外的DataNode上重新安排创建一个副本,随后的文件会正常执行写入操作
- 重新格式化意味着集群的数据会被全部删除,格式化前需考虑数据备份或转移问题,
- 先删除主节点(namenode节点),Hadoop的临时存储目录tmp、namenode存储永久性元数据目录dfs/name、Hadoop系统日志文件目录log中的内容(删除内容,而不是删除文件夹)
- 删除所有数据节点(datanode节点),Hadoop的临时存储目录tmp、namenode存储永久性元数据目录dfs/name、Hadoop系统日志文件目录log中内容
- 格式化一个新的分布式文件系统
- Hadoop的临时存储目录tmp(即core-site.xml配置文件中的hadoop.tmp.dir属性,默认值是/tmp/hadoop-${user.name}),如果没有配置hadoop.tmp.dir属性,那么hadoop格式化时将会在/tmp目录下创建一个目录
- Hadoop的namenode元数据目录(即hdfs-site.xml配置文件中dfs.namenode.name.dir属性,默认值是${hadoop.tmp.dir}/dfs/name),同意如果没有配置该属性,那么hadoop在格式化时将自行创建,
- 必须注意格式化前必须清楚所有子节点(DataNode节点)dfs/name 下的内容,否则在启动hadoop时子节点的守护进程会启动失败。因为如果该文件内容存在,格式化时就不会重新创建该目录,则clusterID ,namespaceID与主节点(namenode)不一致,从而hadoop启动失败
- bin : Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop
- etc : Hadoop配置文件所在的目录,包括core-site.xml 、hdfs-site.xml 、mapred-site.xml 等从Hadoop1.0继承而来的配置文件和yam-site.xml等Hadoop2.0新增的配置文件
- include : 对外提供的变成库头文件(具体动态库和静态库在lib目录中),这些头文件均是用c++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。
- lib : 该目录包含了Hadoop对外提供的变成动态库和静态库,与include目录中的头文件结合使用
- libexec : 各个服务对用的shell 配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。
- sbin : Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本
- share : Hadoop各个模块编译后的jar包所在目录
|
属性
|
默认值
|
属性说明
|
|
dfs.name.dir
|
${hadoop.tmp.dir}/dfs/name
|
NameNode元数据保存路径,多个守则以 “ , ” 分割,不能有空格
|
| dfs.data.dir |
${hadoop.tmp.dir}/dfs/data
|
datanode保存数据库的目录,同上可设置多个
|
|
fs.chexkpoint.period
|
3600秒
|
每隔3600秒secondaryNameNode执行checkpoint来合并fsimage和edits(就是edits与fsimage合并)
|
|
fs.checkpoint.size
|
67108864(64M)
|
当edits文化部达到64M时secondaryNameNode执行checkpoint来合并fsimage和eidts
|
|
dfs.block.size
|
67108864(64M)
|
hdfs每个文件块的大小(HDFS1.0默认64;HDFS2.0默认128)
|
|
dfs.replication
|
3
|
指定副本数;(之后的修改不会对已经上传的文件起作用)
|
|
dfs.permissions
|
true
|
文件操作时的权限检查表示,最好设置成false把,不然操作HDFS可能会报权限异常
|
|
参数
|
属性值
|
解释
|
|
fs.dafaultFS
|
NameNode URL
|
hdfs://host:port
|
|
io.file.buffer.size
|
131072
|
SequenceFiles文件中,读写缓存size设定
|
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>
master为服务器IP地址,其实也可以使用主机名 </description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>
该属性值单位为KB,131072KB即为默认的64M
</description>
</property>
/configuration>
|
参数
|
属性值 |
解释
|
|
dfs.namenode.name.dir
|
在本地文件系统所在的NameNode的存储空间和持续化处理日志
|
如果这是一个以逗号分隔的目录列表,然后将名称表被复制的所有目录,以备不时之需
|
|
dfs.namenode.hosts/
dfs.namenode.hosts.exclude
|
Datanodes permitted/excluded列表
|
如有必要,可以使用这些文件来控制允许数据节点的列表
|
| dfs.blocksize |
268435456
|
大写的文件系统HDFS块大小为256MB
|
|
dfs.namenode.handler.count
|
100
|
设置更多的namenode线程,处理从datanode发出的大量RPC请求
|
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>分片数量,伪分布式将其配置成1即可</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/tmp/namenode</value>
<description>命名空间和事务在本地文件系统永久存储的路径</description>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>slaver1, slaver2</value>
<description>datanode1, datanode2分别对应DataNode所在服务器主机名</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>大文件系统HDFS块大小为256M,默认值为64M</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
<description>更多的NameNode服务器线程处理来自DataNodes的RPCS</description>
</property>
</configuration>
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/datanode</value>
<description>DataNode在本地文件系统中存放块的路径</description>
</property>
</configuration>
|
参数
|
属性值
|
解释
|
|
mapreduce.framework.name
|
yarn
|
执行框架设置为Hadoop YARN
|
|
mapreduce.map.memory.mb
|
1536
|
对maps更大的资源限制的
|
|
maperduce.map.java.opts
|
-Xmx2014M
|
maps中对jvm child 设置更大的堆大小
|
|
mapreduce.reduce.memory.mb
|
3072
|
设置reduces对于较大的资源限制
|
|
mapreduce.reduce.java.opts
|
-Xmx2560M
|
reduces对jvm child 设置更大的堆大小
|
| mapreduce.task.io.sort.mb |
512
|
更高的内存限制,而对数据进行排序的效率
|
|
mapreduce.task.io.sort.factor
|
100
|
在文件排序中更多的流合并为一次
|
|
mapreduce.reduce.shuffle.prarllelcopies
|
50
|
通过reduces从更多的map中读取较多的平行 副本
|
<configuration>
<property>
<name> mapreduce.framework.name</name>
<value>yarn</value>
<description>执行框架设置为Hadoop YARN</description>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
<description>对maps更大的资源限制的</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx2014M</value>
<description>maps中对jvm child设置更大的堆大小</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
<description>设置 reduces对于较大的资源限制</description>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
<description>reduces对 jvm child设置更大的堆大小</description>
</property>
<property>
<name>mapreduce.task.io.sort</name>
<value>512</value>
<description>更高的内存限制,而对数据进行排序的效率</description>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
<description>在文件排序中更多的流合并为一次</description>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
<description>通过reduces从很多的map中读取较多的平行副本</description>
</property>
</configuration>
|
参数
|
属性值
|
解释 |
|
yarn.nodemanager.aux-services
|
NodeManager上运行的附属服务。需配置或mapreduce_shuffle,才可运行MapReduce程序
|
|
|
yarn.resourcemanager.hostname
|
MR 的hostname
|
|
小记---------Hadoop读、写文件步骤,HDFS架构理解的更多相关文章
- java读/写文件
读取文件参考:https://blog.csdn.net/weixin_42129373/article/details/82154471 写入文件参考:https://blog.csdn.net/B ...
- Hadoop学习笔记一(HDFS架构)
介绍 Hadoop分布式文件系统(HDFS)设计的运行环境是商用的硬件系统.他和现存的其他分布式文件系统存在很多相似点.不过HDFS和其他分布式文件系统的区别才是他的最大亮点,HDFS具有高容错的特性 ...
- C++ 二进制文件 读 写文件
1 #include <iostream> 2 #include <string> 3 #include<fstream> 4 using namespace st ...
- read(),write() 读/写文件
read read()是一个系统调用函数.用来从一个文件中,读取指定长度的数据到 buf 中. 使用read()时需要包含的头文件: <unistd.h> 函数原型: ssize_t re ...
- 关于使用 Java 分片读\写文件
分片读取文件方法: /** * 分片读取文件块 * * @param path 文件路径 * @param position 角标 * @param blockSize 文件块大小 * @return ...
- c# 读/写文件(各种格式)
最简单的: --------写 //content是要写入文本的字符串 //(@txtPath + @"\" + rid + ".txt");要被写入的TXT ...
- RandomAcessFile、MappedByteBuffer和缓冲读/写文件
项目需要进行大文件的读写,调查测试的结果使我决定使用MappedByteBuffer及相关类进行文件的操作,效果不是一般的高. 网上参考资源很多,如下两篇非常不错: 1.花1K内存实现高效I/O的Ra ...
- 【HDFS API编程】图解客户端写文件到HDFS的流程
- Hadoop优势,组成的相关架构,大数据生态体系下的模式
Hadoop优势,组成的相关架构,大数据生态体系下的模式 一.Hadoop的优势 二.Hadoop的组成 2.1 HDFS架构 2.2 Yarn架构 2.3 MapReduce架构 三.大数据生态体系 ...
随机推荐
- 几种最常见的js array操作方法及示例
1. 序言 操作array可谓前端最基础的工作,无论是从接口中取的数据,还是筛选数据,或者是添加按钮权限等等操作,array都是绕不开的东西.array的操作很多,初学者十分容易搞混,不是很熟练的情况 ...
- react-报错-1
react 错误提示:显示IP端口被占用
- [深度学习] 各种下载深度学习数据集方法(In python)
一.使用urllib下载cifar-10数据集,并读取再存为图片(TensorFlow v1.14.0) # -*- coding:utf-8 -*- __author__ = 'Leo.Z' imp ...
- maven项目创建4 dao层整合
项目配置文件要放在打包成war包的web项目中 创建文件步骤 1 SqlMapConfig.xml <?xml version="1.0" encoding=" ...
- <image>的src属性的使用
刚接触前端不久.怎么用image显示图片是个问题,怎么使用数据流还是base64呢?小小的研究一下 <image src="url"> 1.接口返回数据流,src可以直 ...
- ORA-01440:要减小精度和标准,则要修改的列必须为空
修改字段的精度时,提示“ ORA-01440:要减小精度和标准,则要修改的列必须为空 ” 解决方法:将该表中的数据全部删除即可
- H5 video全屏与取消全屏兼容
H5 video全屏与取消全屏各浏览器兼容, requestFullscreen()全屏方法,exitFullscreen()退出全屏方法.兼容各个浏览器与css3兼容一样加个前缀即可. // 全屏 ...
- es6字符串的扩展——模板
todo1.模板字符串 传统的 JavaScript 语言,输出模板通常是这样写的(下面使用了 jQuery 的方法). $('#result').append( 'There are <b&g ...
- Linux下不同组件运行命令
Spark优化配置 添加外包路径 1.1 vim $SPARK_HOME/conf/spark-defaults.conf spark.executor.extraClassPath file:/// ...
- SQL中模糊查询的模式匹配
SQL模糊查询的语法为: “Select column FROM table Where column LIKE 'pattern'”. SQL提供了四种匹配模式: 1. % 表示任意0个或多个字符. ...