数据结构09—— 并查集(Union-Find)
一、关于并查集
并查集(Union-Find)是一种树型的数据结构,常用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。并查集(Union-Find)从名字可以看出,主要它涉及两种基本操作:合并和查找。这说明,初始时并查集中的元素是不相交的,经过一系列的基本操作(Union),最终合并成一个大的集合。
二、并查集的设计和基本实现
1.并查集接口的设计
public interface UF {
int getSize();
boolean isConnected(int p, int q);
void unionElements(int p, int q);
}
2.第一版本的并查集实现:基于数组
package com.zfy.uf;
public class UnionFind1 implements UF {
private int[] id; // 我们的第一版Union-Find本质就是一个数组
public UnionFind1(int size) {
id = new int[size];
// 初始化, 每一个id[i]指向自己, 没有合并的元素
for (int i = 0; i < id.length; i++) {
id[i] = i;
}
}
@Override
public int getSize() {
return id.length;
}
// 查找元素p所对应的集合编号
// O(1)复杂度
private int find(int p) {
if (p < 0 || p >= id.length)
throw new IllegalArgumentException("p is out of bound.");
return id[p];
}
// 查看元素p和元素q是否所属一个集合
// O(1)复杂度
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(n) 复杂度
@Override
public void unionElements(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID) {
return;
}
for (int i = 0; i < id.length; i++) {
// 合并过程需要遍历一遍所有元素, 将两个元素的所属集合编号合并
if (id[i] == pID) {
id[i] = qID;
}
}
}
}
3.第二版的并查集
package com.zfy.uf;
public class UnionFind2 implements UF {
// 我们的第二版Union-Find, 使用一个数组构建一棵指向父节点的树
// parent[i]表示第一个元素所指向的父节点
private int[] parent;
// 构造函数
public UnionFind2(int size) {
parent = new int[size];
// 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for (int i = 0; i < size; i++)
parent[i] = i;
}
@Override
public int getSize() {
return parent.length;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p) {
if (p < 0 || p >= parent.length)
throw new IllegalArgumentException("p is out of bound.");
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while (p != parent[p])
p = parent[p];
return p;
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
parent[pRoot] = qRoot;
}
}
4. 基于size的优化
package com.zfy.arithmetic.unionfnd; /**
* Created by vincent on 2018/10/15 上午10:13
*/
public class UnionFind3 implements UF { private int[] parent; // parent[i]表示第一个元素所指向的父节点
private int[] sz; // sz[i]表示以i为根的集合中元素个数 // 构造函数
public UnionFind3(int size){ parent = new int[size];
sz = new int[size]; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for(int i = 0 ; i < size ; i ++){
parent[i] = i;
sz[i] = 1;
}
} @Override
public int getSize(){
return parent.length;
} // 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p){
if(p < 0 || p >= parent.length)
throw new IllegalArgumentException("p is out of bound."); // 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while( p != parent[p] )
p = parent[p];
return p;
} // 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
@Override
public boolean isConnected( int p , int q ){
return find(p) == find(q);
} // 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
@Override
public void unionElements(int p, int q){ int pRoot = find(p);
int qRoot = find(q); if(pRoot == qRoot)
return; // 根据两个元素所在树的元素个数不同判断合并方向
// 将元素个数少的集合合并到元素个数多的集合上
if(sz[pRoot] < sz[qRoot]){
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}
else{ // sz[qRoot] <= sz[pRoot]
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
}
5.Main测试方法
package com.zfy.arithmetic.unionfnd;
import java.util.Random;
public class Main {
private static double testUF(UF uf, int m){
int size = uf.getSize();
Random random = new Random();
long startTime = System.nanoTime();
for(int i = 0 ; i < m ; i ++){
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.unionElements(a, b);
}
for(int i = 0 ; i < m ; i ++){
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.isConnected(a, b);
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
public static void main(String[] args) {
// UnionFind1 慢于 UnionFind2
// int size = 100000;
// int m = 10000;
// UnionFind2 慢于 UnionFind1, 但UnionFind3最快
int size = 100000;
int m = 100000;
UnionFind1 uf1 = new UnionFind1(size);
System.out.println("UnionFind1 : " + testUF(uf1, m) + " s");
UnionFind2 uf2 = new UnionFind2(size);
System.out.println("UnionFind2 : " + testUF(uf2, m) + " s");
UnionFind3 uf3 = new UnionFind3(size);
System.out.println("UnionFind3 : " + testUF(uf3, m) + " s");
}
}
测试结果:
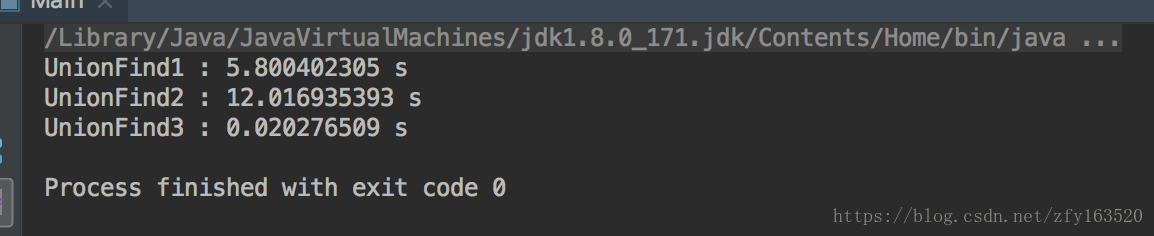
因为本人太懒,一直没有画图,以后一定会改进!!!!!
结束语:合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。
参考:bobobo老师的玩转数据结构
版权声明:尊重博主原创文章,转载请注明出处 https://www.cnblogs.com/hsdy
数据结构09—— 并查集(Union-Find)的更多相关文章
- 数据结构之并查集Union-Find Sets
1. 概述 并查集(Disjoint set或者Union-find set)是一种树型的数据结构,常用于处理一些不相交集合(Disjoint Sets)的合并及查询问题. 2. 基本操作 并查集 ...
- 数据结构 之 并查集(Disjoint Set)
一.并查集的概念: 首先,为了引出并查集,先介绍几个概念: 1.等价关系(Equivalent Relation) 自反性.对称性.传递性. 如果a和b存在等价关系,记 ...
- 并查集(Union/Find)模板及详解
概念: 并查集是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题.一些常见的用途有求连通子图.求最小生成树的Kruskal 算法和求最近公共祖先等. 操作: 并查集的基本操作有两个 ...
- 【基本数据结构】并查集-C++
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中.这一类问题近几年来反复出 ...
- 数据结构(并查集||树链剖分):HEOI 2016 tree
[注意事项] 为了体现增强版,题目限制和数据范围有所增强: 时间限制:1.5s 内存限制:128MB 对于15% 的数据,1<=N,Q<=1000. 对于35% 的数据,1<=N,Q ...
- POJ 1611 The Suspects 并查集 Union Find
本题也是个标准的并查集题解. 操作完并查集之后,就是要找和0节点在同一个集合的元素有多少. 注意这个操作,须要先找到0的父母节点.然后查找有多少个节点的额父母节点和0的父母节点同样. 这个时候须要对每 ...
- 【算法与数据结构】并查集 Disjoint Set
并查集(Disjoint Set)用来判断已有的数据是否构成环. 在构造图的最小生成树(Minimum Spanning Tree)时,如果采用 Kruskal 算法,每次添加最短路径前,需要先用并查 ...
- Java 并查集Union Find
对于一组数据,主要支持两种动作: union isConnected public interface UF { int getSize(); boolean isConnected(int p,in ...
- 【简单数据结构】并查集--洛谷 P1111
题目背景 AA地区在地震过后,连接所有村庄的公路都造成了损坏而无法通车.政府派人修复这些公路. 题目描述 给出A地区的村庄数NN,和公路数MM,公路是双向的.并告诉你每条公路的连着哪两个村庄,并告诉你 ...
随机推荐
- ERP行业销售如何挖掘潜在客户?
要看不同阶段,小企业发展到一定程度,第一个需求是单体财务系统.因为这个时候财务忙不过来了.在大一点就需要业务系统了,就是生产+进销存.有分公司就有集团级软件需求,接着就是oa啊HR啊上下游管理啊等等. ...
- CentOS7中永久保存systemd日志
将systemd的日志写入磁盘: 1.在/var/log/目录下创建日志存放目录,并加入systemd-journal的权限: ~]#mkdir /var/log/journal ~]#chown r ...
- ls 操作命令 -l/-R和rm -r dir 功能实现
ls -R #include <sys/stat.h> #include <dirent.h> #include <fcntl.h> #include <st ...
- SqlServer数据库(可疑)的解决办法
当数据库发生这种操作故障时,可以按如下操作步骤可解决此方法, 打开数据库里的Sql 查询编辑器窗口,运行以下的命令. // 1.使用指定值强制重新配置:(1.0表示为真假) sp_configure ...
- 问题记录-Get data from file(fonts/arial.ttf) failed, error code is 32
time:2015/04/19 1. 描述:运行cocos的cpp-test例子,结果修改了代码之后提示错误:Get data from file(fonts/arial.ttf) failed, e ...
- ETCD TLS 配置的坑
一.环境准备 环境总共 3 台虚拟机,系统为centos7,1个 master,2 个 etcd 节点,master 同时也作为 node 负载 pod,在分发证书等阶段将在另外一台主机上执行,该主机 ...
- [BZOJ 1924][Sdoi2010]所驼门王的宝藏
1924: [Sdoi2010]所驼门王的宝藏 Time Limit: 5 Sec Memory Limit: 128 MBSubmit: 1285 Solved: 574[Submit][Sta ...
- Directed Graphs
有向图 Introduction 就是边是有方向的,像单行道那样,也有很多典型的应用. 点的出度指从这个点发出的边的数目,入度是指向点的边数.当存在一条从点 v 到点 w 的路径时,称点 v 能够到达 ...
- PHP_GET后门,躲避任何安全软件
经常拿到一些比较好的php站想要留住.插入菜刀一句话,很容易被管理发现,不管是eval还是assert,就是管理发现不了,有时连接也会被各种的安全软件拦截.现在教大家一个简单的技巧.本人一直在用,留的 ...
- js图形库
SVG.js viz.js graphviz的js实现版 raphael d3 (http://d3js.org/) JavaScript InfoVis Toolkit Flotr2 and Env ...