<机器学习实战>读书笔记--决策树
1、决策树的构造
createBranch伪代码:
检测数据集中的每个子项是否属于同一分类:
IF SO RETURN 类标签
ELSE
寻找划分数据集的最好特征
划分数据集
创建分支节点
FOR 每个划分的子集
调用函数createBranch并增加返回结果到分支节点中
RETURN 分支节点
划分数据集的大原则:将无序的数据变的更加有序。在划分数据集之前之后信息发生的变化称为信息增益,获得信息增益最高的特征就是最好的选择
熵定义为信息的期望值。熵越大越离散。
计算给定数据集的香农熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
2.决策树的构造算法
ID3算法
ID3算法是一种分类决策树算法。他通过一系列的规则,将数据最后分类成决策树的形式。分类的根据是用到了熵这个概念。熵在物理这门学科中就已经出现过,表示是一个物质的稳定度,在这里就是分类的纯度的一个概念。公式为:
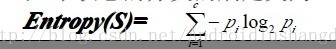
C4.5算法
C4.5与ID3在核心的算法是一样的,但是有一点所采用的办法是不同的,C4.5采用了信息增益率作为划分的根据,克服了ID3算法中采用信息增益划分导致属性选择偏向取值多的属性。信息增益率的公式为:
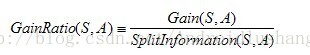
分母的位置是分裂因子,他的计算公式为:
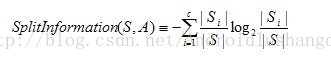
CART算法
CART算法对于属性的值采用的是基于Gini系数值的方式做比较,gini某个属性的某次值的划分的gini指数的值为:

<机器学习实战>读书笔记--决策树的更多相关文章
- 机器学习实战 - 读书笔记(13) - 利用PCA来简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第13章 - 利用PCA来简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- 机器学习实战 - 读书笔记(11) - 使用Apriori算法进行关联分析
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第11章 - 使用Apriori算法进行关联分析. 基本概念 关联分析(associat ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 机器学习实战 - 读书笔记(06) – SVM支持向量机
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第6章:SVM 支持向量机. 支持向量机不是很好被理解,主要是因为里面涉及到了许多数学知 ...
- 【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
原文地址: https://www.cnblogs.com/steven-yang/p/5686473.html ------------------------------------------- ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
- 机器学习实战读书笔记(二)k-近邻算法
knn算法: 1.优点:精度高.对异常值不敏感.无数据输入假定 2.缺点:计算复杂度高.空间复杂度高. 3.适用数据范围:数值型和标称型. 一般流程: 1.收集数据 2.准备数据 3.分析数据 4.训 ...
- <机器学习实战>读书笔记--朴素贝叶斯
1.朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法, 最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model, ...
随机推荐
- PHP爬虫(3)PHP DOM开源代码里的大坑和字符编码
一.开源代码的问题 在PHP爬虫(2)中介绍了开源工程Sunra.PhpSimple.HtmlDomParser.在实际工作中发现一个问题,例如http://www.163.com的网页数据怎么也抓取 ...
- Hibernate 之核心接口
1.持久化和ORM 持久化是指把数据(内存中的对象)保存到可持久保存的存储设备中(如硬盘),主要应用于将内存中的数据存储到关系型数据库中,在三层结构中,持久层专注于实现系统的逻辑层面,将数据使用者与数 ...
- c#设计模式之观察者模式(Observer Pattern)
场景出发 一个月高风黑的晚上,突然传来了尖锐的猫叫,宁静被彻底打破,狗开始吠了,大人醒了,婴儿哭了,小偷跑了 这个过程,如果用面向对象语言来描述,简单莫过于下: public class Cat { ...
- iOS 设置 (plist)
Architectures:
- ASP.NET Core使用Ping判断网络是否接通
static void Main(string[] args) { // 主机地址 string targetHost = "bing.com"; string data = &q ...
- 546. Remove Boxes
Given several boxes with different colors represented by different positive numbers. You may experie ...
- 【Oracle 12c】最新CUUG OCP-071考试题库(56题)
56.(14-14) choose the best answer: You need to create a table with the following column specificatio ...
- Bootstrap框架常用总结
Bootstrap框架常用标签: 标题标签:<h1>-<h6> bootstrap中也设置的相同的样式 - 若要使用 必须使用空标签来定义 比如<s ...
- UML总结
http://www.cnblogs.com/riky/archive/2007/04/07/704298.html
- QuantLib 金融计算——基本组件之 InterestRate 类
目录 QuantLib 金融计算--基本组件之 InterestRate 类 InterestRate 对象的构造 一些常用的成员函数 如果未做特别说明,文中的程序都是 Python3 代码. Qua ...