基于上三角变换或基于DFS的行(列)展开的n阶行列式求值算法分析及性能评估
进入大一新学期,看完《线性代数》前几节后,笔者有了用计算机实现行列式运算的想法。这样做的目的,一是巩固自己对相关概念的理解,二是通过独立设计算法练手,三是希望通过图表直观地展现涉及的两种算法的性能差异。
本文主要完成了以下工作:
(1)、分析上三角变换算法的设计与时间复杂度;
(2)、提出基于DFS的行列式展开算法并分析;
(3)、分析两种算法的时间复杂度,并通过统计比较两种算法的实际性能。
一、上三角变换、主对角线元素相乘
该算法通过上三角变换来简化计算,核心是简单的高斯消元法(gaussian elimination),算法分析如下。对高斯消元比较熟悉的朋友可以直接略过:-)
【1】、主对角线上所有元素都不为0的行列式
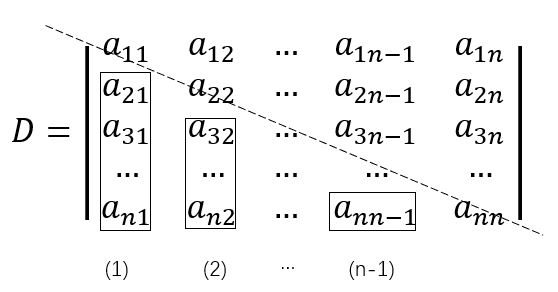
总目标是遍历主对角线的每一个元素aii,并每次从该元素往下构造零三角形;即按照从上至下、从左至右的顺序化为上三角行列式。对应到高斯消元法中,这是一种简单的顺序消元。
例如:第(1)步遍历到达a11,扫描其下第2~n行,通过等价转换,消去第1列相关元素B1={a21、a31、...、an1}(图中矩形框部分),则B1中所有元素都成为了0;
第(2)步遍历到达a22,往下扫描第3~n行,等价地消去B2={a32、a42、...、an2}中的所有元素,于是B2中所有元素都为0。
……
第(n-1)步遍历到达an-1 n-1,此时只剩下元素an n-1,执行消去后,主对角线下方便出现了完整的零三角形。
因此最多遍历n-1步即可完成转换。
上述过程可归纳为:对所有1 <= p <= n-1,以主对角线元素app为基准,通过等价变换使元素a1 p、a2 p、...、an p全为0。
以上讨论明确了算法的框架,但尚未提及等价变换的具体方法。想必各位读者已经猜到,这里的变换是根据——将任意一行的各元素分别乘相同系数后,加到另一行对应的元素上,行列式值不变——这一基本性质。本算法的等价转换只用到了这一条性质。
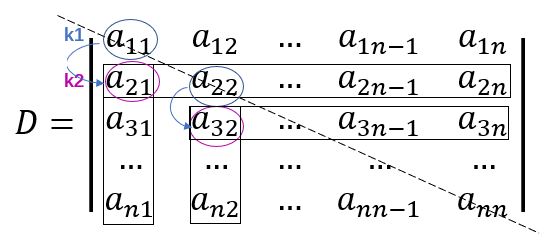
为了实现消去,以主对角线元素app作为基准,记为k1;将待消去元素aip记为k2。第p步消元时,将基准所在行p的每一个元素apj乘上某个系数便得到增量Δaij,再将增量分别加到待消去元素所在行i的每个元素aij(也包括待消去元素),便可使元素aip = 0并保持行列式等价。
如图所示为p = 1时,k1,k2的相对位置。
对于待消去元素,j = p时,要求a‘ij = aij + Δaij = 0,因此各元素aij增量如下。
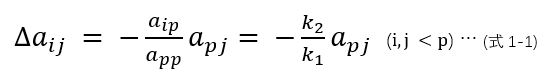
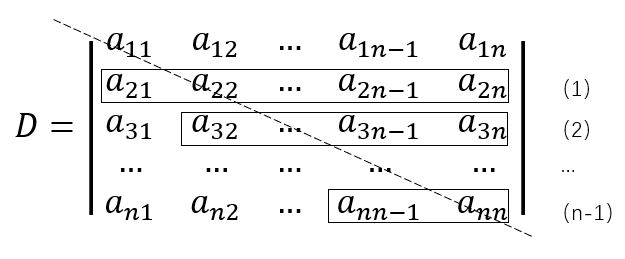
除此之外发现,第(1)步消去后,a21 = 0,a31 = 0,则下步消去不必考虑a31,以此类推,待变换元素aij的实际操作范围依次缩小,如图中矩形框所示。
通过分析容易设计出针对单个基准元素的消去算法。注意还有许多可以改进的地方:例如因为主对角线元素app(k1)在式1-1的分母位置,所以当k1绝对值很小时,浮点运算时会引起很大的误差,从而影响算法的稳定性。这个问题将在下一小节得到解决。

void
triangle_trans(double **square, int size, int pos)
{
double k1, k2;
k1 = square[pos][pos];
; i < size; i++)
{
k2 = square[i][pos];
for(int j=pos; j < size; j++)
{
square[i][j] += k2 * square[pos][j] * (-) / k1;
}
}
}
对所有主对角线元素应用上述算法,即可得出上三角形。根据上三角形性质,只需将主对角线元素相乘便可得到行列式的值。
; i < size-; i++)
{
triangle_trans(square, size, i);
}
; i < size; i++)
{
ret *= square[i][i]; /* diagonal line */
}
接下来对整个算法的时间复杂度进行计算。算法整体由一个三重循环、一个单循环构成。对于一个n阶行列式:
从3重循环看:
最外层循环(遍历主对角线元素)执行次数为n-1;
次外层循环(遍历行)关键代码语句频度为1+2+...+(n-1) = n * (n-1) / 2;
最内层循环(遍历列)关键代码语句频度为:
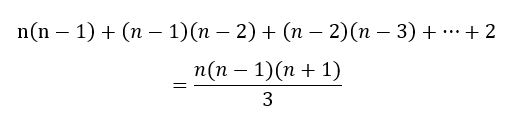
从单循环看:关键代码语句频度为n。
综上所述,所有关键代码语句执行频度为: 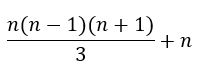
可求得时间复杂度为 O( n3 )。
【2】、主对角线上存在零元素
在这种情况下基准元素app可能取零值,根据式1-1,其中分式无意义,因此上面提到得算法便失效了。如何解决?思路很简单:在进行第p步消元前,先选出别的行,与基准元素所在行做交换,使得基准元素不再为0即可。
从这个思路入手,我们可以考虑高斯消元的列主元消去法、全主元消去法。
列主元消去法的核心是:在第p步消元前,找出p行下所有第p列元素绝对值最大的非零元素 anp, 交换第n行与第p行并修改符号,即可将绝对值最大的anp作为主元。但这样还存在问题:倘若p行下所有第p列元素都是0,列主元消去法便也失效了。
为了解决这个问题,最终引入全主元消去法。
全主元消去法与列主元消去法思想类似,只不过列主元消除法仅从第p列中选取绝对值最大的非零元素、只做行交换。而全主元消除法释从第p行第p列开始的右下角范围中所有元素中选取一个绝对值最大的非零元素anr作为主元,同时交换第n行与r列,这样就扩大了交换范围,保证了算法的有效。
有读者会问,上述算法中选择非零元素即可,为何还要保证“绝对值最大”?这其实正好回答了上一小节里遗留下的稳定性问题。选择绝对值最大的元素,则进行式1-1的运算时,能最大程度地保证精度,从而提高算法的稳定性。这真是一举两得。
全主元消去法也适用于【1】。对于大多数行列式而言其稳定性已经足够。
到这里关于借鉴高斯消元法的行列式上三角变换算法的描述就全部结束了。
二、DFS与行列式按行展开
该算法核心思想是:n阶行列式D=|aij|等于它的任意一行各元素与其代数余子式乘积之和,即对j行展开时:
D = a1jA1j + a2jA2j + ... + anjAnj,j = 1,2,...,n
而代数余子式可表示为:
Aij = (-1)i+jMij
其中余子式又为一个新的n-1阶行列式,故可以将n阶行列式递归分解,直至成为二阶行列式。
在这里自然地想到用DFS(深度优先搜索)实现算法,理由如下:
(1)、每一步都满足递归特性;(2)、根据余子式定义,还需确保删除元素aik所在列,即搜索路径上不会重复出现列。
综上可以证明,该算法的本质是一种DFS,注意所谓的“搜索”其实是“求值”过程。由于搜索算法的特性,我们发现其时间复杂度并不优于上一节所提到的算法。但继续研究并非毫无意义,至少可以为上一节算法的时间复杂度提供对照。
搜索的对象是当前所处深度中的每一个元素的余子式;搜索的终止条件为余子式达到2阶,此时可以简单地通过主对线乘积 - 副对角线乘积求出该行余子式的值,并返回上一层继续搜索。
由于我们采用按行展开,搜索的深度正是待求值余子式第一行在原始行列式中的绝对行数,如图显示了这种关系,其中椭圆部分为当前所处元素,方框部分为当前搜索所处的范围(椭圆部分的余子式)。

引入数组记录本次搜索及在此之前所有被删除过的列,这样在本次搜索时便可跳过这些列,搜索结束后,需恢复本次删除的列,释放供上层搜索。
static char *term_visited = NULL;
double
det_A(double **square, int bound_row, int size)
{
int i, j, k;
double result = 0.0;
)
{
/*
* | |
* D = | a11 [row][col_1] a12 [row][col_2] |
* | a21 [row+1][col_1] a22 [row+1][col_2] |
* | |
*/
, col_2=-;
; j < size; j++)
{
if(!term_visited[j])
{
)
col_1 = j;
)
col_2 = j;
);
}
}
assert(col_1 != - && col_2 != -);
][col_2] - square[row][col_2] * square[row+][col_1];
}
;
; j < size; j++)
{
if(!term_visited[j])
{
term_visited[j] = ;
/*
* Recursive calling to implement row/column expand formula...
* D = (-1)^(i+j) * M(i,j)
*/
, size);
)
acc = -acc;
result += acc;
term_visited[j] = ;
}
}
return result;
}
接下来计算时间复杂度,可以看出,对于n阶行列式,关键代码语句频度为:
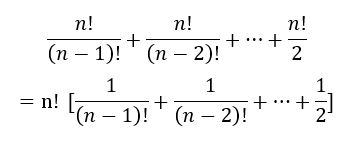
观察可知,n!右边式子实际上为函数f(x) = ex的麦克劳林展开式中令x = 1时的一部分,当n趋于∞时,该式子趋于e - 1/n! - 2 - Rn(1) = e-2,即趋于常数。因此可得到算法的时间复杂度为:O(n!)。
ohh!!!真糟糕
三、统计方法
通过对两种算法时间复杂度的分析,我们发现两个算法都拥有很高的时间复杂度O(n3)和O(n!),并且当算法规模增加时,时间复杂度差距很大。到这里这篇博文已经没有写下去的必要了,但毕竟“挖了一个坑”,不能丢下坑就草率结题,因此笔者还是决定简单地做下数据统计。(由此可见写博文前进行预判是多么重要(ˉ▽ˉ;) )
如下程序通过简单地调用clock()函数实现对算法运行时间的低精度统计,重复运行N次后求算术平均值并输出。将输出结果写入csv文件并导入作图程序,得到最终的统计图。
clock_t s, d;
double sum;
double ret;
#define N 100
;u<N;u++)
{
s = clock();
#if USING_EXPAND
ret = det_A(square, , size);
#elif USING_TRIANGLE
ret = det_trig(square, size);
#endif
d = clock() - s;
sum += ( / CLOCKS_PER_SEC;
#if PRINT_TRANS_SPEED
std::cout << (double)d / CLOCKS_PER_SEC << std::endl; // = 0
#endif
}
std::cout << sum/N << " ms" << std::endl;
四、性能对比
如下所示为两种算法的平均绝对时间对比图。横坐标为目标行列式规模(n^2),纵坐标为运行100次所消耗的平均时间,单位为ms。(在Core i7-8550 @3.9GHz测试)
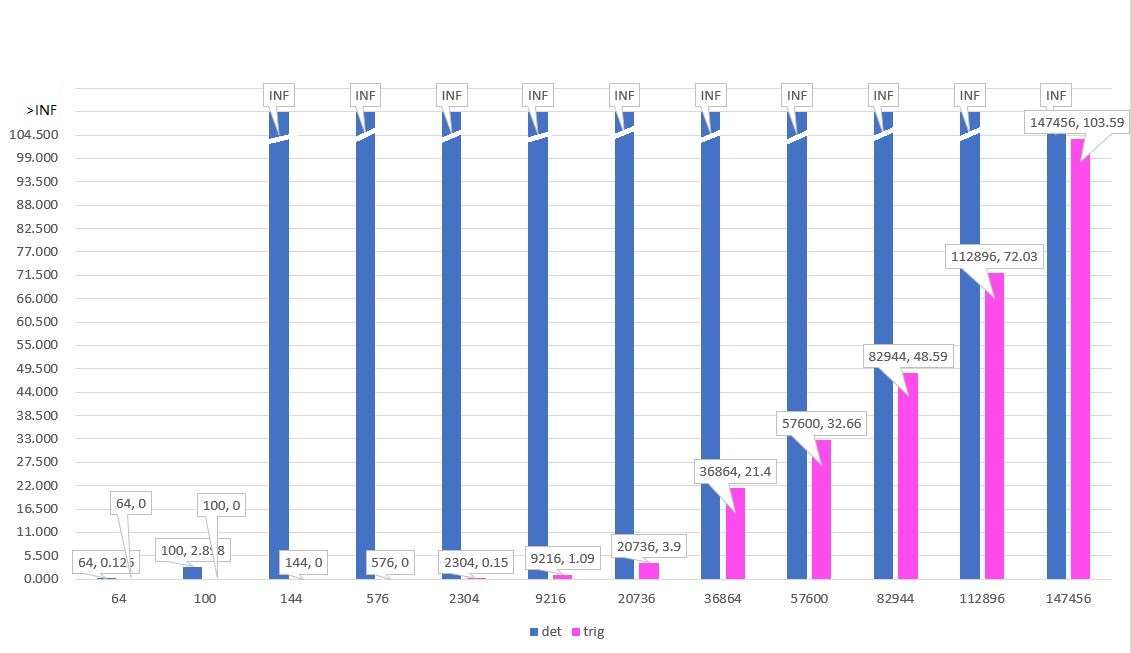
INF表示消耗时间超出实验所允许的设定值(1s)。
如下所示为两种算法的平均绝对时间对比图。横坐标为目标行列式规模(n^2),纵坐标为以基于三角变换的算法在147456规模的绝对耗时为基准,各规模绝对耗时与基准的比值。
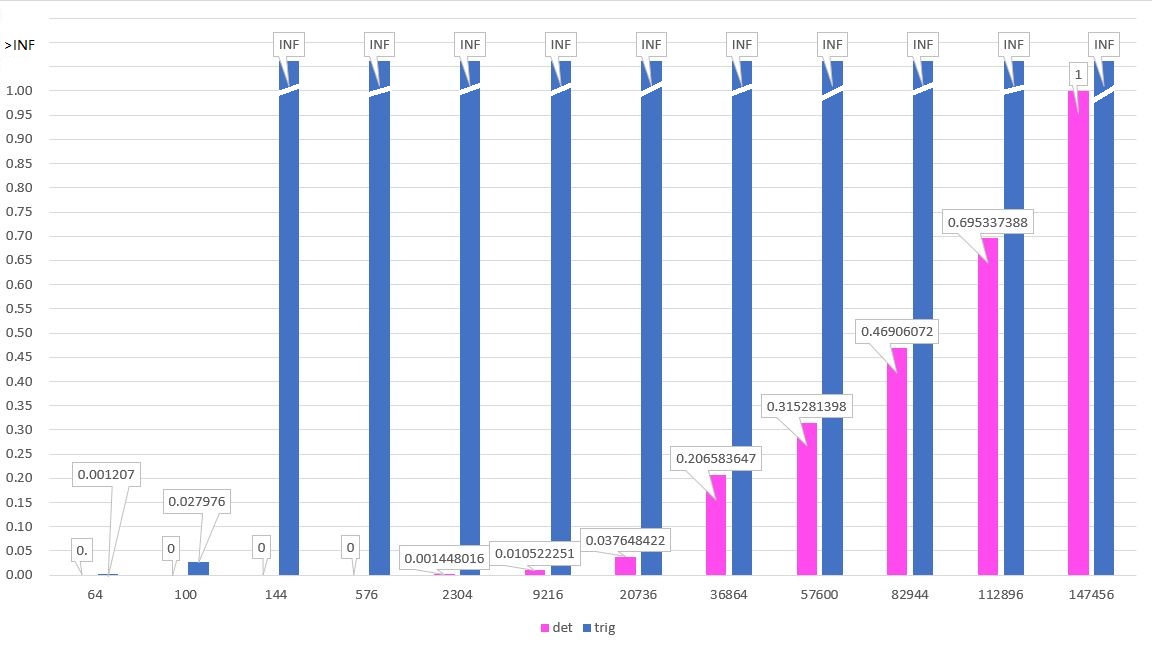
由此可见,基于行(列)展开定理的算法在144(12阶)规模下,运行时间就达到了统计设定的上限;而此时基于上三角变换的算法运行时间甚至还低于定时器的精度,即便在实验所做的最大规模下,基于上三角变换的算法运行时间仍然不到105ms,开销远低于前者,性能差距悬殊。
第二种算法时间复杂度太高,意义不大;而第一种算法在数据规模较小时,时间复杂度可以接受,并且对于一些行列式来说第一种算法是稳定的,因此第一种算法具有一定实用价值。
基于上三角变换或基于DFS的行(列)展开的n阶行列式求值算法分析及性能评估的更多相关文章
- [Swust OJ 643]--行列式的计算(上三角行列式变换)
题目链接:http://acm.swust.edu.cn/problem/643/ Time limit(ms): 1000 Memory limit(kb): 65535 Description ...
- 在Linux(CentOS 6.6)服务器上安装并配置基于Apache的SVN服务器
#!/bin/bash # # 在Linux(CentOS 6.6)服务器上安装并配置基于Apache的SVN服务器: # # .安装服务 # .创建svn版本库 # .创建svn用户 # .配置sv ...
- django 基于form表单上传文件和基于ajax上传文件
一.基于form表单上传文件 1.html里是有一个input type="file" 和 ‘submit’的标签 2.vies.py def fileupload(request ...
- 面向服务体系架构(SOA)和数据仓库(DW)的思考基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台
面向服务体系架构(SOA)和数据仓库(DW)的思考 基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台 当前业界对面向服务体系架构(SOA)和数据仓库(Data Warehouse, ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- 5.7 并行复制配置 基于GTID 搭建中从 基于GTID的备份与恢复,同步中断处理
5.7 并行复制配置 基于GTID 搭建中从 基于GTID的备份与恢复,同步中断处理 这个文章包含三个部分 1:gtid的多线程复制2:同步中断处理3:GTID的备份与恢复 下面文字相关的东西 大部分 ...
- Android学习-- 基于位置的服务 LBS(基于百度地图Android SDK)--定位SDK
原文:Android学习-- 基于位置的服务 LBS(基于百度地图Android SDK)--定位SDK 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
- 基于栈的指令集与基于寄存器的指令集的区别,JVM指令集实例
现代JVM在执行Java代码的时候,通常都会将解释执行与编译执行两者结合起来 所谓解释执行,就是通过解释器来读取字节码,遇到相应的指令就去执行该指令. 所谓编译执行,就是通过即时编译器(Just In ...
- 基于栈的指令集与基于寄存器的指令集详细比对及JVM执行栈指令集实例剖析
基于栈的指令集与基于寄存器的指令集详细比对: 这次来学习一些新的概念:关于Java字节码的解释执行的一种方式,当然啦是一些纯理论的东东,但很重要,在之后会有详细的实验来对理论进行巩固滴,下面来了解一下 ...
随机推荐
- QQ聊天框变成方框口口口口的解决办法
QQ聊天框变成方框口口口口的解决办法 安装了QQ拼音输入法6.0之后,发现 QQ聊天对话框好友名称变成框口口口口口,网上没有找到办法,卸载轻聊版,安装完整版9.03之后,再次启动就好了.
- win10.64位wnmp-nginx1.14.0 + PHP 5. 6.36 + MySQL 5.5.59 环境配置搭建 结合Thinkphp3.2.3
本文20%是原创,另外参考了这里https://blog.csdn.net/foolly/article/details/78963025 作者:CSDN 古雨蓝枫 和这里https://www.cn ...
- navicat 导入execl失败
在使用navicat导入execl是遇到了如下图的错误 在更换多个版本的navicat后问题依然如故. 解决办法; 1.打开需要导入的execl 2.安装一个AccessDatabaseEngine_ ...
- MVC JsonResult 结果返回
使用MVC之后, 默认的ActionResult 有很多子类譬如 JsonResult之类, 可以很方便. 基本用法如下: public ActionResult GetVacatio ...
- Springboot jar包外指定配置文件及原理
解决方案: 修改maven的pom.xml文件 不拷贝资源文件 <resources> <resource> <directory>src/main/resourc ...
- jenkins自动构建站点
jenkins构建iis主要内容, 安装过程百度很多,就不多介绍 看图是主要内容 msbuid功能 1.执行vs的编译过程 2.编译好的文件发布到具体的路径下 批处理功能 1.创建站点 2.创建对应的 ...
- 在局域网中搭建自己的gis服务器
在局域网中搭建自己的gis服务器 需求 在客户的B/S应用系统中使用电子地图.该系统只可运行于内部网中. 分析 由于系统中的电子地图只能运行于局域网中所以不能采用googl ...
- 使用Linux的环境变量
许多程序和脚本都使用环境变量来获取系统信息,并存储临时数据和配置信息: 1.什么是环境变量 用来存储关于shell会话和工作环境的信息,就叫做环境变量: bash shell下两种类型: 1.全局变量 ...
- Python for循环之图像练习
矩形 # 控制行 for i in range(1,5): # 控制列 for j in range(1,8): # 用end在末尾传入空格串,这样print函数就不会自动换行了 print('*', ...
- 对python的一些拙见
对于python,总的来说有点机缘巧合的识得了它.当我录取专业是计算机的时候,身边的一些人向我介绍了这个解释型脚本语言吧.大一自学了一部分,刚好听的网课是嵩天老师的课,这学期迫不及待地拉着舍友选了这个 ...