solr 中文分词器IKAnalyzer和拼音分词器pinyin
solr分词过程:
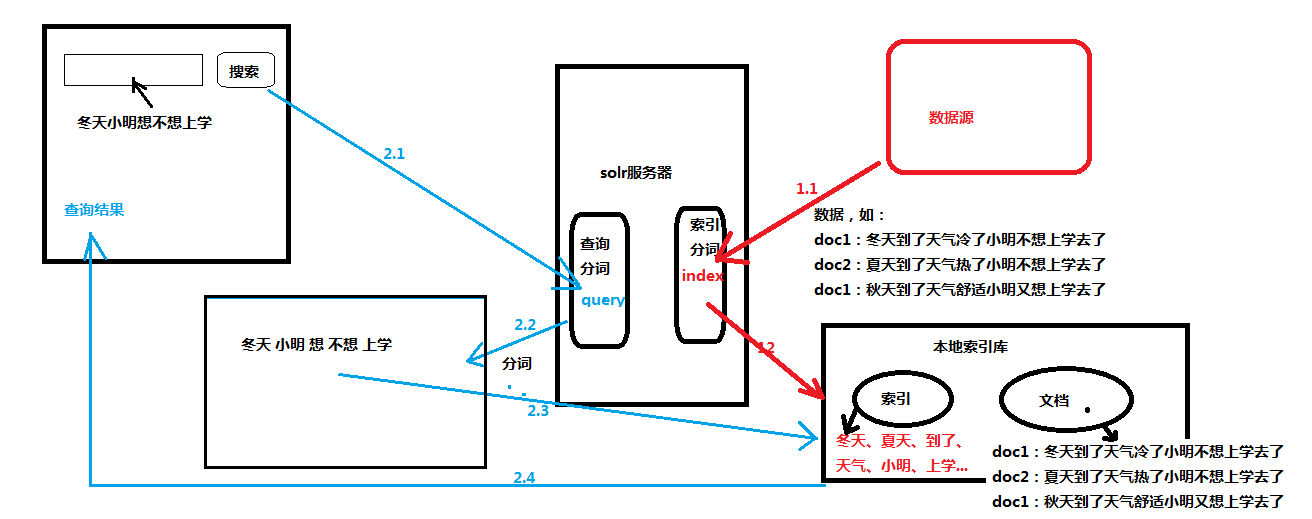
Solr Admin中,选择Analysis,在FieldType中,选择text_en
左边框输入 “冬天到了天气冷了小明不想上学去了”,点击右边的按钮,发现对每个字都进行分词。这不符合中国人的习惯。
solr6.3.0自带中文分词包,在 \solr-6.3.0\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-6.3.0.jar,但是不能自定义词库
好在我们有IKAnalyzer(已无人更新,目前版本是2012)和pinyin分词插件。
IKAnalyzer安装
IKAnalyzer下载地址:https://github.com/EugenePig/ik-analyzer-solr5
因为原始的IKAnalyzer已经不支持solr5以后的版本,这里是修改过后的
用git clone到本地或者直接下载zip到本地,然后执行mvn clean instal(Java8),或者mvn clean -Djavac.src.version=1.7 -Djavac.target.version=1.7 install(jdk1.7)
执行完,在项目 /target 目录下,看到jar文件
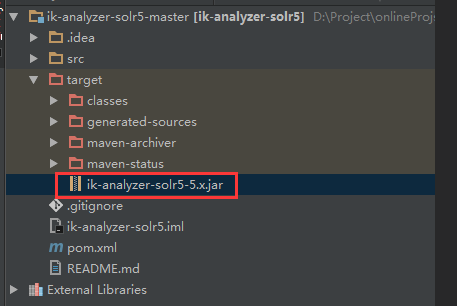
将改jar文件copy到 solr目录:\solr-6.3.0\server\solr-webapp\webapp\WEB-INF\lib
然后修改core的配置文件:\solr-6.3.0\server\solr\test\conf\managed-schema
添加如下配置:
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
</analyzer>
</fieldType>
或者
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
保存重启solr,到选择test核心-Analysis,进入分词页面,输入“冬天到了天气冷了小明不想上学去了”,FieldType选择“text_cn”,点击Analyse Value按钮:
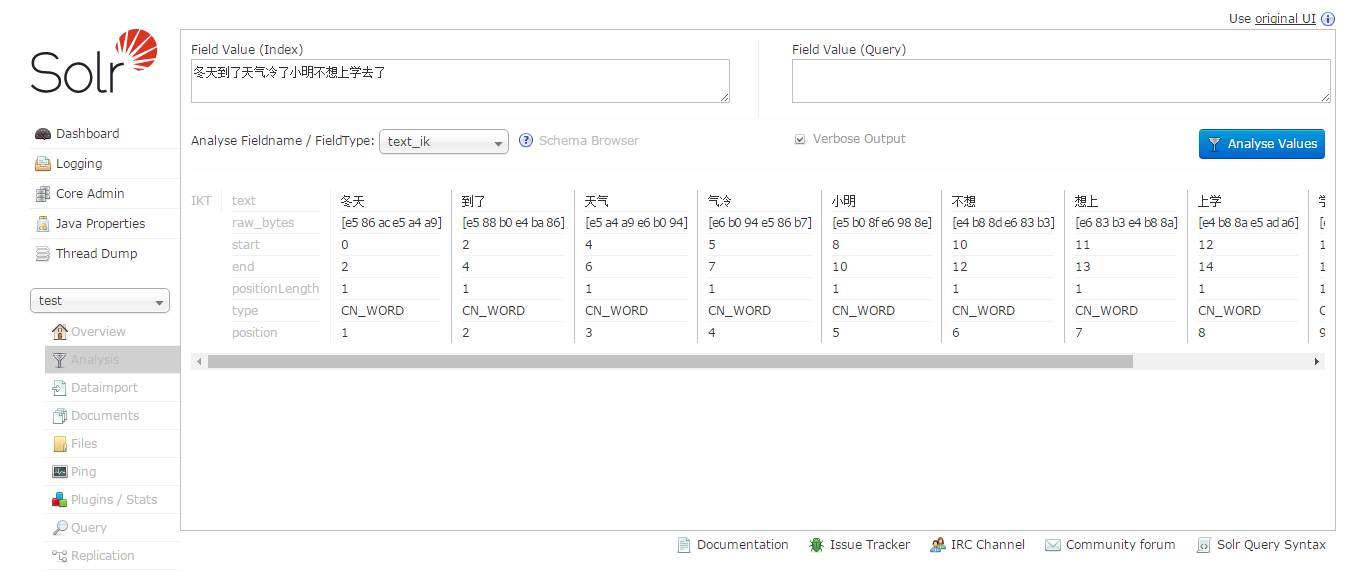
看到已经分词中文成功了。
pinyin安装
pinyin下载地址:http://files.cnblogs.com/files/wander1129/pinyin.zip
下载后将2个jar文件copy到\solr-6.3.0\server\solr-webapp\webapp\WEB-INF\lib目录下,
然后修改core的配置文件:\solr-6.3.0\server\solr\test\conf\managed-schema,添加:
<!-- 配置拼音分词 pinyin-->
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
</fieldType>
重启solr
到选择test核心-Analysis,进入分词页面,输入“冬天到了天气冷了小明不想上学去了”,FieldType选择“text_pinyin”,点击Analyse Value按钮:
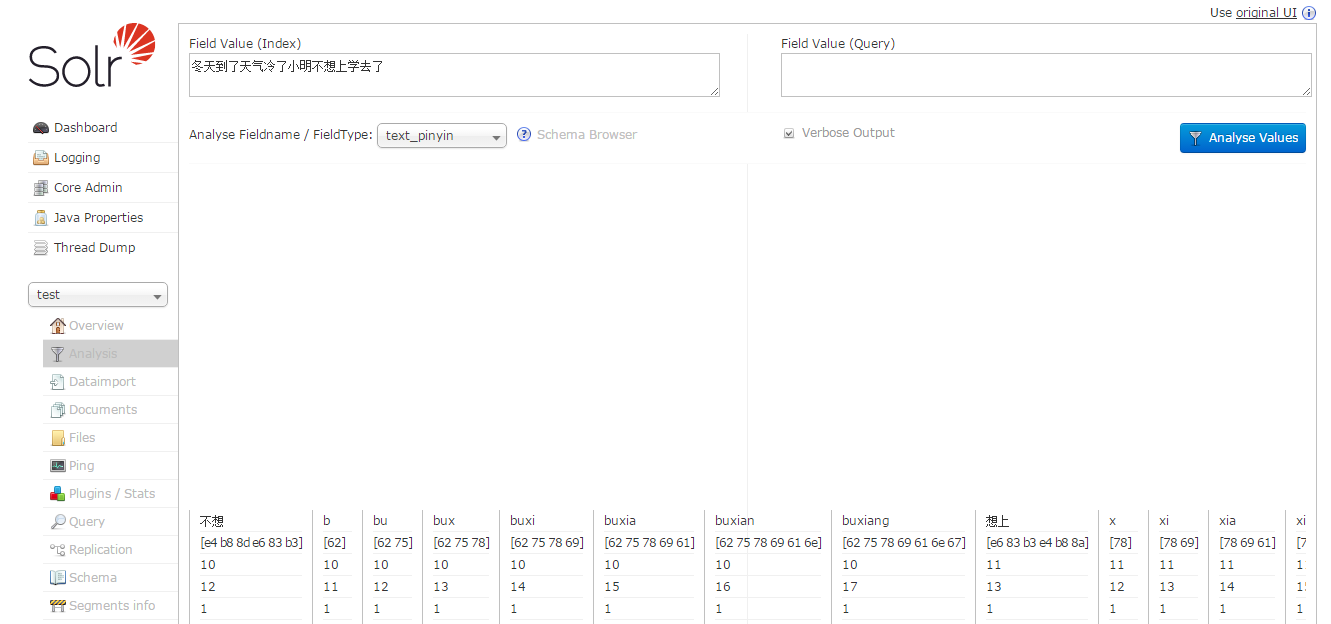
看到汉字转成拼音了。
solr 中文分词器IKAnalyzer和拼音分词器pinyin的更多相关文章
- 如何在Elasticsearch中安装中文分词器(IK)和拼音分词器?
声明:我使用的Elasticsearch的版本是5.4.0,安装分词器前请先安装maven 一:安装maven https://github.com/apache/maven 说明: 安装maven需 ...
- 开源项目在线化 中文繁简体转换/敏感词/拼音/分词/汉字相似度/markdown 目录
前言 以前在 github 上自己开源了一些项目.碍于技术与精力,大部分项目都是 java 实现的. 这对于非 java 开发者而言很不友好,对于不会编程的用户更加不友好. 为了让更多的人可以使用到这 ...
- Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装.这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索. 一.创建Core: ...
- es 修改拼音分词器源码实现汉字/拼音/简拼混合搜索时同音字不匹配
[版权声明]:本文章由danvid发布于http://danvid.cnblogs.com/,如需转载或部分使用请注明出处 在业务中经常会用到拼音匹配查询,大家都会用到拼音分词器,但是拼音分词器匹配的 ...
- elasticsearch 拼音+ik分词,spring data elasticsearch 拼音分词
elasticsearch 自定义分词器 安装拼音分词器.ik分词器 拼音分词器: https://github.com/medcl/elasticsearch-analysis-pinyin/rel ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- solr 中文分词 IKAnalyzer
solr中文分词器ik, 推荐资料:http://iamyida.iteye.com/blog/2220474?utm_source=tuicool&utm_medium=referral 使 ...
- 全文检索引擎Solr系列——整合中文分词组件IKAnalyzer
IK Analyzer是一款结合了词典和文法分析算法的中文分词组件,基于字符串匹配,支持用户词典扩展定义,支持细粒度和智能切分,比如: 张三说的确实在理 智能分词的结果是: 张三 | 说的 | 确实 ...
- Solr7.3.0入门教程,部署Solr到Tomcat,配置Solr中文分词器
solr 基本介绍 Apache Solr (读音: SOLer) 是一个开源的搜索服务器.Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现.Apache ...
随机推荐
- 定时自动从FTP服务器取数据脚本
环境需求:某些情况下经常需要向FTP服务器取文件,可以用定时任务执行简单脚本自动去取相应文件. 一般用法: ~]# ftp IP地址 端口 //ftp命令可以通过yum install ftp方式 ...
- 只用200行Go代码写一个自己的区块链!
Coral Health · 大约23小时之前 · 220 次点击 · 预计阅读时间 7 分钟 · 不到1分钟之前 开始浏览 区块链是目前最热门的话题,广大读者都听说过比特币,或许还有智能合约,相信大 ...
- MVC aspx
客户端服务器---Model(模型)---View(视图)---Control(控制器) 1.ASP.NET MVC 2.新建项目引擎选aspx.在Controllers创建控制器,默认启动Home ...
- vue2.0项目实战(5)vuex快速入门
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式.它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化.Vuex 也集成到 Vue 的官方调试工具 ...
- (set stringstream)单词数 hdu2072
单词数 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submis ...
- 线程(Thread)
package cn.gouzao.demo3; public class ThreadDemo extends Thread{ public void run(){ for(int i=0;i< ...
- Grunt安装与环境配置
公司项目还没有前后端分离,而前端是使用node.js搭建起来的,现在需要自己动手开发,故学习下并做为记录防止以后忘记. grunt依赖node.js,所以在安装之前确保你安装了 Node.js.然后开 ...
- go 终端读写、文件读写
go 终端读写 操作终端相关文件句柄常量 os.Stdin:标准输入 os.Stdout:标准输出 os.Stderr:标准错误输出 示例: package main import ( "b ...
- Linux检查和收集硬件信息的常用命令总结
Linux检查和收集硬件信息的常用命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Linux基础真的很重要,基础不牢,地动山摇.这句话我是听老男孩创始人冉总说的一句话,起初 ...
- Hadoop基础-通过IO流操作HDFS
Hadoop基础-通过IO流操作HDFS 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.上传文件 /* @author :yinzhengjie Blog:http://www ...